相关性建模方法在计算机视觉领域里得到了广泛应用。比如,在目标检测领域,该类方法主要考虑像素间的空间领域关系;在视频建模中,考虑帧之间的相关性;在细腻度图像分类中,考虑类别标签间的结构相关性;该类方法在样本不均衡下的模型建立中同样适用,充分挖掘类别间的相关部分等等。下面主要对相关方法进行一个简单汇总与总结,给自己的后续研究提供思路。
1. 细腻度图像分类
该文名称为Fine-grained Image Classification by Exploring Bipartite-Graph Labels,发表在CVPR 2016上。概括来说,该文基于CNN架构,在最后的全连接层(Soft Max)融入二分图标签(BGL, bipartite-graph labels),以此解决了细腻度图像分类中的两大难题:1) 由于细腻度类别标签数的有限性造成CNN模型的过拟合;2) 细腻度类别间的相似性很难学习辨别性的特征表示。所谓二分图标签(BGL),就是作者事先定义的粗略标签,可理解为对细腻度标签根据不同性质的一系列分组;也可看着是对细腻度标签的不同属性划分。比如,论文中举了一个关于餐馆-菜品的例子,如下图:
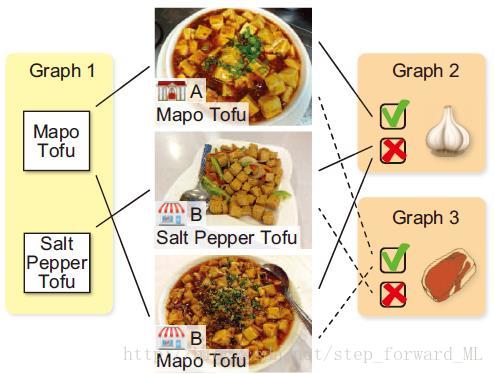
其中,中间一列为3个细腻度标签,边上的Graph1-3为预定义的粗略标签。在Graph 2中有两个类别:加蒜与否;此粗标签能将细腻度类别划分为两组。很明显,定义的一系列粗略标签与细腻度标签具有层次结构。假如现在有了一系列预定义的粗标签,那么在CNN模型的最后一层中,无非是结合细腻度标签,在Soft Max上进行扩展并学习相应的权重参数。下面来看看论文的形式化过程。
首先,我们看看只有细腻度标签在Soft Max上的形式化。假设给定训练数据集
其中,
上式对
由上式可知定义的一系列粗略标签在细腻度标签给定情况下相互独立。这里为了简化并与文中一致,定义的联合概率分布函数为:
其中
注意,由于BGL的二值属性,
有了
这里省略了归一化因子。我们能轻易构造对数似然函数,注意文中提到为了防止过拟合,在对数似然函数中加入了正则化因子,基本思想是保证细腻度标签与相关的粗略标签的权重相似,即:
最终的对数似然函数为
该目标函数对
2. 样本不平衡下的人脸识别
该文名称为Extended SRC: Undersampled Face Recognition via Intraclass Variant Dictionary,发表在PAMI2012上。传统的SRC方法建立在信号总是能在过完备字典下得到稀疏线性表达,该方法在样本均衡下的人脸识别能达到非常好的效果。但是针对样本不均衡的分类问题,该方法由于不能建立少数样本类的过完备字典而不能达到预期的识别率。而这篇论文所提方法在Sparse Representation-Based Classification (SRC) 的基础上进行扩展,充分利用人脸数据集的相关性进行建模,来解决少样本类的分类问题。
现在我们考虑一个样本不均衡的分类问题。假设在人脸数据集中,类A中有充足的训练样本,即是在不同采集条件不同姿态不同遮挡下的某一人脸。而类B中只有一个训练样本,即是在特定采集条件下特定姿态下的某一人脸。那么怎么才能构造合适的字典B来有效的表征在其它采集条件其它姿态其它遮挡下的人脸B?本文最大的创新之处就在于此,基本的思想就是各类内的人脸图像差异基本一致。比如,类A中有一张正脸,一张侧脸;而类B中只有一个训练样本为正脸,而测试样本正好为侧脸。那么,这两类的对应两张图像的差异应该不大。因此,作者进一步指出类内的差异总是能由其他类内的差异稀疏且线性表达,如下图

可知测试图像能由训练图像与其他类内的差异进行组合。那么从稀疏表示的角度看,少样本类的测试图像总能由所有训练样本组成的字典
其中
得到类别
本文方法思想简单,但很具创新性。即使是在一个训练样本下的识别率也能达到很好的效果。但是该方法的一个前提是构造的统一的差异字典必须过完备。