
一、什么是反向传播?
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。 在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
二、反向传播有什么作用?

该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
反向传播要求有对每个输入值期望得到的已知输出,来计算损失函数的梯度。因此,它通常被认为是一种监督式学习方法,虽然它也用在一些无监督网络(如自动编码器)中。它是多层前馈网络的Delta规则的推广,可以用链式法则对每层迭代计算梯度。反向传播要求人工神经元(或“节点”)的激励函数可微。
三、反向传播是怎么运作的?
BP网络的结构降法的基础上。BP网络的输入输出关系实质上是一种映射关系:一个 输入m输出的BP神经网络所完成的功能是从 一维欧氏空间向m维欧氏空间中一有限域的连续映射,这一映射具有高度非线性。它的信息处理能力来源于简单非线性函数的多次复合,因此具有很强的函数复现能力。这是BP算法得以应用的基础。
反向传播算法主要由两个环节(激励传播、权重更新)反复循环迭代,直到网络的对输入的响应达到预定的目标范围为止。
BP算法的学习过程由正向传播过程和反向传播过程组成。在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。如果在输出层得不到期望的输出值,则取输出与期望的误差的平方和作为目标函数,转入反向传播,逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯量,作为修改权值的依据,网络的学习在权值修改过程中完成。误差达到所期望值时,网络学习结束。

每次迭代中的传播环节包含两步:
- (前向传播阶段)将训练输入送入网络以获得激励响应;
- (反向传播阶段)将激励响应同训在这里插入图片描述练输入对应的目标输出求差,从而获得隐层和输出层的响应误差。




权重更新:
对于每个突触上的权重,按照以下步骤进行更新:

- 将输入激励和响应误差相乘,从而获得权重的梯度;

- 将这个梯度乘上一个比例并取反后加到权重上。

- 这个比例将会影响到训练过程的速度和效果,因此称为“学习率”或“步长”。梯度的方向指明了误差扩大的方向,因此在更新权重的时候需要对其取反,从而减小权重引起的误差。

四、如何选择好BP的优化函数?
反向传播训练方法:以减小 loss 值为优化目标,有梯度下降、momentum 优化 器、adam 优化器等优化方法。
这三种优化方法用 tensorflow 的函数可以表示为:
- train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
- train_step=tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss)
- train_step=tf.train.AdamOptimizer(learning_rate).minimize(loss)
1、梯度下降(一般最常用)
tf.train.GradientDescentOptimizer()使用随机梯度下降算法,使参数沿着 梯度的反方向,即总损失减小的方向移动,实现更新参数。

2、tf.train.MomentumOptimizer()在更新参数时,利用了超参数。

3、tf.train.AdamOptimizer()
使用时可以不填写完所有参数
tf.train.AdamOptimizer.__init__(
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
epsilon=1e-08,
use_locking=False,
name='Adam'
)

是一个寻找全局最优点的优化算法,引入了二次方梯度校正。
利用自适应学习率的优化算法,Adam 算法和随 机梯度下降算法不同。随机梯度下降算法保持单一的学习率更新所有的参数,学习率在训练过程中并不会改变。而 Adam 算法通过计算梯度的一阶矩估计和二 阶矩估计而为不同的参数设计独立的自适应性学习率。
相比于基础SGD算法,1.不容易陷于局部优点。2.速度更快
4、指数衰减学习率:
如果学习率太小,那么我们每次训练之后得到的效果都太小,这无疑增大了我们的无谓的时间成本。如果如图右所示,学习率太大,那我们有可能直接跳过最优解,进入无限的训练中。所以解决的方法就是,学习率也需要随着训练的进行而变化。
Tensorflow提供了一种灵活的学习率设置—指数衰减法。先从一个较大的学习率开始快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率:
decayed_learning_rate = learning_rate(decay_rate^(global_steps/decay_steps)
tensorflow 函数:
current_learning_rate = tf.train.exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=True/False)
- current_learning_rate: 当前使用的学习率
- learning_rate: 初始学习率
- decay_rate: 衰减系数
- decay_steps: 衰减步幅
- global_step: 训练总步数
- strircase: 参数为true时会对
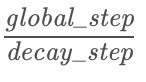
进行取整,从而学习率会呈阶梯式下降
【借鉴的出处:Principles of training multi-layer neural network using backpropagation ,URL:http://www.cs.unibo.it/~roffilli/pub/Backpropagation.pdf】
