一对多
查询type表的某一条数据,并且要同时查出所有typeid与之配置的user,最终要得到一个以下类型的Type对象
- public class Type {
- String id;
- String name;
- List<User> users;
- @Select("select * from user where typeid = #{typeid}")
- public List<User> findUserById(String typeid);
- @Results({
- @Result(property="id",column="id"),
- //users映射List<User> users,many=@Many是调用关联查询方法,"id"是关联查询条件,FetchType.LAZY是延迟加载
- @Result(property="users",column="id", many=@Many(select="hello.dao.MybatisDao.findUserById",fetchType=FetchType.LAZY))
- })
- @Select("select * from type where id=#{id}")
- public Type findTypeById(String id);
注意,如果省略第一个@Result, 查出来的type对象id是null,因为第二个@Result使用关联查询时把column="id"映射给了property="users"。
service层
- Type type = mybatisDao.findTypeById("1");
- System.out.println("延迟加载");
- type.getUsers();

因为设置了fetchType=FetchType.LAZY,mybatisDao.findTypeById("1")只会查询type表,当访问type.getUsers()时才会查询其关联表。
其它关联
一对一:把上面的many=@Many换成one=@One,其他原理是一样的
多对多:把多个字段映射成many=@Many,就是多对多了
多对一:把上面dao方法的返回值从Type换成List<Type>
通过SQL日志可以看到,前面的一对多关联查询实际上执行了两次select,
这就是hibernate中典型的n+1问题。
假设我现在type表中有三条记录,我要查出所有的type及其对应的user对象,最终得到一个List<Type>,查询过程是这样的

一共执行了四次查询,一次查type表,因为有三条记录,所以查了三次user表,以此来填充三个type对象的List<User> users属性。如果type表中有几百条数据,而且还有上十个表进行关联查询,结果无法设想。
在传统的xml配置方式中,是可以用一条SQL查出无限层嵌套的关联关系的。不过mybatis官方做出了一个说明,由于java注解的局限性,不支持那种映射方式。所以,如果想只用一条SQL查出关联映射,必须借住xml
xml无限层嵌套映射
这里以三层嵌套为例,以实现前端的三级菜单树。这是一个tree表,pid是其上级菜单的id。
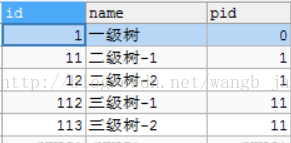
要得到的查询结果Tree对象,这个对象是可以无限递归的
- public class Tree {
- String id;
- String name;
- List<Tree> child;
dao
- @Mapper
- public interface TreeDao {
- @ResultMap("tree")
- @Select("SELECT p1.id,p1.name,p2.id id2,p2.name name2,p3.id id3,p3.name name3 "
- + "FROM tree p1,tree p2,tree p3 WHERE p1.id=p2.pid AND p2.id=p3.pid")
- public List findTree();

@ResultMap("tree"):映射结果集id是tree,前面说了,这个映射要在xml中配置
application.properties文件中添加配置
- #指定xml映射文件的路径
- mybatis.mapper-locations=classpath:hello/mapper/*
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
- <!-- 映射dao -->
- <mapper namespace="hello.dao.TreeDao">
- <!-- 结果集类型 -->
- <resultMap id="tree" type="hello.pojo.Tree">
- <!-- 映射字段 -->
- <result column="id" property="id" />
- <result column="name" property="name" />
- <!-- 嵌套第二张表 -->
- <collection property="child" ofType="hello.pojo.Tree" >
- <id column="id2" property="id" />
- <result column="name2" property="name" />
- <!-- 嵌套第三张表 -->
- <collection property="child" ofType="hello.pojo.Tree" >
- <id column="id3" property="id" />
- <result column="name3" property="name" />
- </collection>
- </collection>
- </resultMap>
- </mapper>
- [
- {
- "id": "1",
- "name": "一级树",
- "child": [
- {
- "id": "11",
- "name": "二级树-1",
- "child": [
- {
- "id": "112",
- "name": "三级树-1",
- "child": null
- },
- {
- "id": "113",
- "name": "三级树-2",
- "child": null
- }
- ]
- }
- ]
- }
- ]
使用JAVA注解还是XML
XML执行一条SQL语句,并不是一定比JAVA注解执行多条SQL性能更优
一条SQL:关联的表越多,笛卡尔积越大,查询结果的冗余数据也越多
多条SQL:只需单表查询,如果做好索引查询效率会非常高,查询结果也没有冗余 。
在现实中,如果使用其中一种方式的性能较低,则可以偿试另一方式
进行测试,同时还要考虑数据库优化策略