背景:
我现在生产使用的Jira是安装在物理机上的,而且是一台将近6年的古董机,Jira承载着我们公司日常的工作流任务交互,所以我必须想办法好好保护它。
目前的容灾方案是通过Linux的crontab每天晚上凌晨将DB中的数据和Jira的文件系统做一次异机备份(由于历史原因,我接手的时候就已经这样了,并非我本意),但是这样一旦发生磁盘损坏等问题会让我最多丢失一天的数据,而且需要重新搭建一次jira,并没有足够的信心。
于是为了将风险降到最低,并且在出现故障时可以迅速恢复,我们本篇来好好研究下如何更好的设计下Jira的容灾问题。因为Jira和Wiki一般都是一起采购使用的,所以这里我把这两个工具一起备份。
要解决容灾,首先要搞清楚工具的工作原理,其数据是由哪几部分组成的,否则如果遗漏了某些文件将会导致整个工具不可用。
Jira和Wiki需要备份的内容:
1 应用服务
应用服务包括原生的服务和已安装插件
2 业务数据,业务数据分为基础数据和附件
基础数据存储在关系型数据库中,包含用户信息、任务信息、空间信息等,mysql迁移可以直接解决这部分问题。
附件以文件方式存储在本地,需要找到相应的目录做压缩拷贝迁移,也是整个备份的重点。
Jira和Wiki提供的备份方式:
1 全量备份和恢复
可以通过系统工具全量的导出导入数据,但是恢复时间很长。
2 按空间/项目单个备份和恢复
可以选择单个空间或项目进行备份和恢复,但公司现在有上百个项目和空间,操作复杂度太高,所以该策略不适合。
3 并没有提供增量备份和恢复的方式
所以当初次备份恢复后,以上的1和2都不适用于增量数据的处理,需要寻找其它方式来解决增量数据同步的问题。
目录结构:
/data/atlassian
|
jira (jira app,除开logs都应该备份)
|
confluence (wiki app,除开logs都应该备份)
|
application-data
|
jira
|
dbconfig.xml(数据库配置,需要备份)
|
data (附件和图片,需要重点备份)
|
plugins (已安装的插件,需要备份)
|
monitor (不清楚用途,需要备份)
|
export (jira原生备份机制每日生成的文件,不需要备份,甚至可以删除)
|
import (jira恢复时使用的文件,不需要备份)
|
caches (jira的索引,需要备份)
|
其它(日志或临时文件,不需要备份)
|
confluence
|
confluence.cfg.xml (licence和数据库配置,需要备份)
|
plugins-* (插件相关,需要备份)
|
attachments (wiki的附件,需要重点备份)
|
index (wiki的索引,需要备份)
|
viewfile(查看文件宏,展现用的,需要备份)
|
其它(日志或临时文件,不需要备份;有几个拿不准的目录,需要备份)
文件大小:
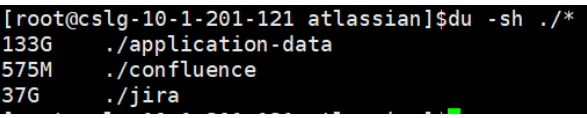
jira和confluence一样做为工具类竟然有37G的大小明显有问题,对它进行瘦身:

所以备份前可以将这些历史日志清理掉,节省很大的磁盘空间,并可以提高同步效率。
Jira还有个日备份数据也需要清理:


所以清理完以后我需要维护的数据从180G下降到100G左右!几乎降低了一半!
备份的步骤:
总体原则:保持备机目录结构和数据库结构不变,通过rsync和数据库同步方式做热备。
1 mysql相对于其他模块是独立的,可以先行
2 转移jira数据内容之前,先把历史log和备份文件清除,特别是export中每日备份数据,文件又多又大,已经没有保留的意义
3 转移wiki的数据内容之前,只需要把log清除,然后全量压缩复制过去
4 在备机恢复做验证时,主机需要阻断从备机过来的请求,避免移植过程中配置项有依赖。
后面重点讲下rsync如何做同步
1 主机上添加rsync配置:
/etc/rsyncd.conf中添加
[atlassian_backup]
path=/data/atlassian
comment=atlassian rsync
#ignore errors
read only=yes
list =yes
uid=root
gid=root
secrets file=/etc/rsync/atlassian.scrt
auth users = jingtao
vi /etc/rsync/atlassian.scrt
jingtao:******
chmod 600 /etc/rsync/atlassian.scrt
2 备机先主动全量同步一次
vi /etc/jira_rsyncd.pass
******
chmod 600 /etc/jira_rsyncd.pass
/usr/bin/rsync -avPz --ignore-errors --delete --contimeout=30 --timeout=3600 --password-file=/etc/jira_rsyncd.pass [email protected]::atlassian_backup /data/atlassian/
3 备机配置增量同步
crontab -e
0 */1 * * * nohup /usr/bin/rsync -avPz --exclude=jira/logs --ignore-errors --delete --contimeout=30 --timeout=3600 --password-file=/etc/jira_rsyncd.pass [email protected]::atlassian_backup /data/atlassian/ &
wq
service crond restart
这样每小时备机就会从主机把文件同步一次,也就是说我们最多只会丢失一小时的文件数据。
Jira和Wiki操作命令和涉及到的配置文件
/data/atlassian/jira/bin/start-jira.sh 启动jira
/data/atlassian/jira/bin/stop-jira.sh 关闭jira
/data/atlassian/confluence/bin/start-confluence.sh 启动wiki
/data/atlassian/confluence/bin/stop-confluence.sh 关闭wiki
grep 8080 /data/atlassian/jira/conf/server.xml jira的tomcat端口
grep 8005 /data/atlassian/jira/conf/server.xml jira程序端口
grep 8090 /data/atlassian/confluence/conf/server.xml wiki的tomcat端口
grep 8000 /data/atlassian/confluence/conf/server.xml wiki程序端口
/data/atlassian/application-data/jira/dbconfig.xml jira的DB配置
/data/atlassian/application-data/confluence/confluence.cfg.xml wiki的DB配置
注意:在验证备机的时候需要注意一个问题,我自己也遇到了。如果你买的license不是cluster类型的,同一时间内只能由一个进程,也就是说你必须把主机的Jira和Wiki停掉,才能验证备机,否则备机会报license的错。
