引言:
最近在使用SpringDataJPA做CRUD功能,在做到需要查询单个的功能的时候,我们发现SpringDataJPA为我们提供了两种办法findOne() 和 getOne(),那我们该如何选择呢,他们之间的区别又是什么呢,下面我们来总结一下
findOne() 和 getOne()的区别
1. 首先我们看一下Spring官方对他们的解释
/**
* Retrieves an entity by its id.
* @param id must not be {@literal null}.
* @return the entity with the given id or {@literal null} if none found
* @throws IllegalArgumentException if {@code id} is {@literal null}
* /
T findOne(ID id);
/**
* Returns a reference to the entity with the given identifier.
*
* @param id must not be {@literal null}.
* @return a reference to the entity with the given identifier.
* @see EntityManager#getReference(Class, Object)
*/
T getOne(ID id);
findOne:当我查询一个不存在的id数据时,返回的值是null.
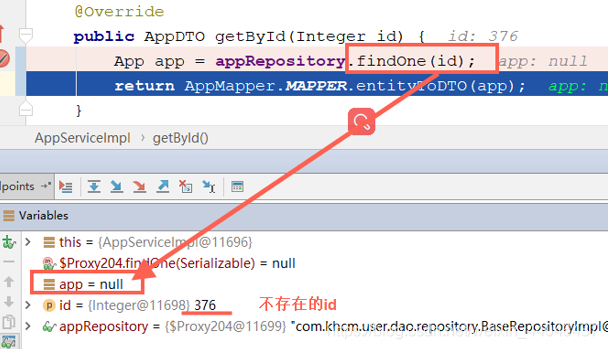
getOne: return 对具有给定标识符的实体的引用。当我查询一个不存在的id数据时,直接抛出异常,因为它返回的是一个引用,简单点说就是一个代理对象。
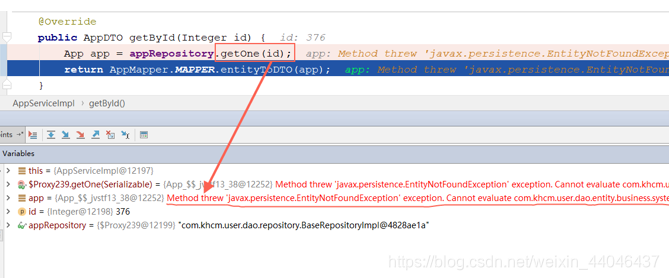
我们知道SpringDataJPA底层默认使用Hibernate,hibernate对于load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方法,hibernate一定要获取到真实的数据,否则返回null。所以我们可以吧findOne() 当成hibernate中get方法,getOne()当成hibernate中load方法来记忆。。。。。
补充
以前我们使用Spring Data Jpa 的查询单个的时候,可以使用findOne()方法根据id查询。但是在2.0.5以后,不能用来当作根据id查询了。2.0.5以后变成了findById(id).get()来查询了。
2.0.5版本以前的CrudRepository类是这样的:
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> save(Iterable<S> var1);
T findOne(ID var1);
boolean exists(ID var1);
Iterable<T> findAll();
Iterable<T> findAll(Iterable<ID> var1);
long count();
void delete(ID var1);
void delete(T var1);
void delete(Iterable<? extends T> var1);
void deleteAll();
}
2.0.5版本以后的CrudRepository类是这样的:
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}
