1.环境搭配
- 1.1安装scrapyd
pip install scrapyd - Scrapyd是一个服务,用来运行scrapy爬虫的
- 它允许你部署你的scrapy项目以及通过HTTP
- JSON的方式控制你的爬虫 官方文档:http://scrapyd.readthedocs.org/
DOS 成功样例

可视化成功样例
输入 url: http://127.0.0.1:6800/

- 1.2安装Scrapy-client
pip install scrapy-client - scrapy-client 相当于一个客户端
- 它允许我们将本地的scrapy项目打包发送到scrapyd 这个服务端
2.部署
-
部署Scrapyd
-
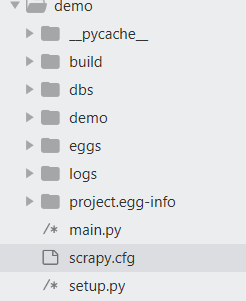
首先进入Scrapy框架的根目录,里面有一个scrapy.cfg文件
-
本scrapy项目叫 demo
-
修改scrapy.cfg文件
-
首先将url的注释去除,url,就是我们要将scrapy部署到的服务器地址
-
随后将 [deploy] 改为 [deploy:scrapyd1],这里需要注意的是scrapyd1是我们自己定义的,任意均可。

-
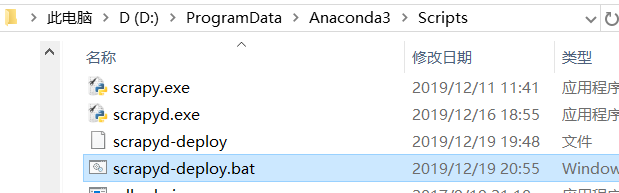
进入
D:\ProgramData\Anaconda3\Scripts(python安装的地址) -
在此目录下创建文件
scrapyd-deploy.bat -
文件的内容为(内容中的D:\ProgramData\Anaconda3请大家根据自己情况进行更改)
@echo off
"D:\ProgramData\Anaconda3\python.exe" "D:\ProgramData\Anaconda3\Scripts\scrapyd-deploy" %*
运行
- 1 首先运行scrapyd

- 2 进入爬虫的根目录运行
scrapyd-deploy scrapyd1 -p xlwb - scrapyd1是我们之前定义的 [deploy:scrapyd1]
- xlwb 是自己命名
- 如何进入的不是爬虫的根目录执行此操作出现的情况为
Error: no Scrapy project found in this location - 根目录执行效果为

此时我们已然成功的将
