Independently Recurrent Neural Network(IndRNN):Building A Longer and Deeper RNN
阅读并整理《Independently Recurrent Neural Network(IndRNN):Building A Longer and Deeper RNN》论文,并解析其TensorFlow实现代码。
文章提出一种独立的循环神经网络,该网络可以用下面的公式表示。
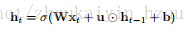
这里U是一个vector,圈点符号表示的是Hadamard product这样每一层中的神经元就相互独立的在更新对于第n个神经元,隐含状态
可以表示为
.这样使得下一层的某一个神经元与上一层所有神经元建立联系(上一层的输出作为这一层某一个神经元的输入),但与当前层的神经元没有联系,也就是所谓的相互独立。
这个网络公式方面实际上并不难,但作者对该网络的优势进行了很好的描述,下面逐一来看。
The gradient backpropagation throgh time for an IndRNN
下面来看公式看看IndRNN是如处理gradient vanishing and exploding 的 :
对于n-th个神经元
这里为了计算简洁先不考虑偏置。
定义我们要优化的目标函数在T时刻为
,那么我们就可以表示出梯度在传到 t 时刻是多少。
从公式中可以看到,梯度仅仅与
和
有关,其中
项是很容易调节的,这里的激活函数也往往属于某一特定范围。
而传统的RNN的梯度表示为:
这里的
是一个Jacobian matrix 。从IndRNN的公式中我们可以看到IndRNN的梯度仅与当前的weight相关,在特定的学习率的作用下这个权重只会有较小的更新,而Jacobian matrix的更新与特征值有关涉及到所有神经元的权重,因此每一个小的矩阵发生一点点的改变将会让该矩阵发生很大的波动。所以作者认为IndRNN的训练要比传统RNN更稳健。
下面设计方法来调整指数项到一个合适的范围从而使得IndRNN具有一定的长短期记忆。
假设T时刻的梯度能够传到t时刻,并记此时的梯度为
,只要保证对于每一个神经元满足:
,这样梯度就不会在t时刻消失。
同样为了防止梯度在t时刻过大,此时需要满足:
,这里的
是最大的梯度用来保证梯度传到此时可不至于爆炸。
此时引入relu作为激活函数时当前神经元的权重就被限制在
范围内
开源实现
Tensorflow:
https://github.com/batzner/indrnn
Keras:
https://github.com/titu1994/Keras-IndRNN
Pytorch:
https://github.com/StefOe/indrnn-pytorch
https://github.com/theSage21/IndRNN
https://github.com/zhangxu0307/Ind-RNN
Chainer:
https://github.com/0shimax/chainer-IndRNN