关于vim 使用sudo apt-get install vim 安装
vi 经常出问题,不习惯,建议使用vim
一、本地模式 ===》官方案例 Grep案例讲解
在hadoop-2.7.7文件下面创建一个input文件夹
mkdir /opt/software/hadoop-2.7.7/input复制hadoop的配置文件到input内
cp /opt/software/hadoop-2.7.7/etc/hadoop/*.xml /opt/software/hadoop-2.7.7/input命令讲解 格式 :cp 文件 复制文件的目标路径
执行Grep案例:
命令格式:用hadoop命令 执行jar包 jar包的路径 jar包内的wordcount案例 要计算的文件(输入) 输出结果(输出) 正则过滤hadoop jar /opt/software/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output 'd[a-z.]+'命令作用:计算出input以d开头的文件出现的个数
*注意output不能创建
否则会抛出 文件已经存在 异常
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/opt/software/hadoop-2.7.7/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)查看结果、
先查看输出的文件有那些ls -al /opt/software/hadoop-2.7.7/outputcat查看 输出文件,比如
cat /opt/software/hadoop-2.7.7/output/part-r-00000
二、wordcount案例 ===》统计单词数量
- 第一步创建文件夹
mkdir /opt/software/hadoop-2.7.7/wcinput- 进入文件夹创建wc.input文件向文件写入一些内容
进入文件夹创建文件cd /opt/software/hadoop-2.7.7/wcinputtouch /opt/software/hadoop-2.7.7/wcinput/wc.input
向文件中写入数据例如写入:vim /opt/software/hadoop-2.7.7/wcinput/wc.input
wc.input文件内容hadoop yarn hadoop mapreduce abcdabc admin a- 执行命令格式
*注意输出路径不能提前存在!!!
hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount 计算文件的文件名 输出结果文件
讲解命令:用hadoop命令 执行jar包 jar包的路径 jar包内的wordcount案例 要计算的文件 输出结果hadoop jar /opt/software/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput wcoutput- 第四步、cat查看结果 cat /opt/software/hadoop-2.7.7/wcoutput/part-r-00000
三、伪分布式模式启动hdfs并运行MapReduce
*注意 启用伪分布模式后,本地模式就不能用了!!
原因是本地模式用的是File协议,而伪分布模式用的是hdfs协议。扫描二维码关注公众号,回复: 8807015 查看本文章
伪分布模式是以集群方式搭建的,实际是完全分布式模式。适用于电脑配置比较底,没有多台电脑的程序员
cd /opt/software/hadoop-2.7.7/etc/hadoop第一步、配置环境
- 配置集群
1.1 配置hadoop-env.sh ===>给hadoop配置java_home环境可以另外开一个窗口,然后输入echo $JAVA_HOME获取jdk的位置vim /opt/software/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
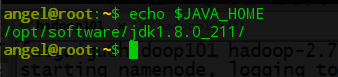
/opt/software/jdk1.8.0_211/ #不要看到就复制粘贴,看上面的讲解!这个路径是通过上面查询到JAVA_HOME的值

1.2 配置core-site.xmlvim /opt/software/hadoop-2.7.7/etc/hadoop/core-site.xml在<configuration></configuration>标签内添加
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value><!--按集群搭建时需要改成相应的域名--> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/software/hadoop-2.7.7/data/tmp</value> </property>
==============================================
1.3、配置hdfs-site.xmlvim /opt/software/hadoop-2.7.7/etc/hadoop/hdfs-site.xml和上面一样放置在configuration标签内
<!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property>
=============================================
第二步:启动集群
1、格式化NameNode(注意:第一次启动时格式化,以后就不要总格式化!)关于不能一直格式化,查看这篇https://blog.csdn.net/qq_41813208/article/details/100753659
hdfs namenode -format
2、启动NameNode
/opt/software/hadoop-2.7.7/sbin/hadoop-daemon.sh start namenode
3、启动DataNode
/opt/software/hadoop-2.7.7/sbin/hadoop-daemon.sh start datanode
第三步:查看集群
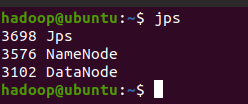
输入 jps得到结果如下结果,说明NameNode 和 DataNode正常!!!
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
虚拟机内则在 浏览器输入服务器ip:50070端口http://localhost:50070真实主机则输入,虚拟机的ip:50070同样可以访问到,正常情况下如下图
如果遇到无法访问:检查防火墙是否关闭了
centos6关闭防火墙: ================ service iptables status chkconfig iptables off //永久关闭防火墙 service iptables stop //临时关闭防火墙 service iptables status ccentos7关闭防火墙: ============= systemctl status firewalld //查看状态 systemctl stop firewalld //关闭防火墙 systemctl start firewalld //启动防火墙 systemctl disable firewalld //开机禁用防火墙 systemctl enable firewalld //开机启动防火墙第四步:操作集群
创建目录
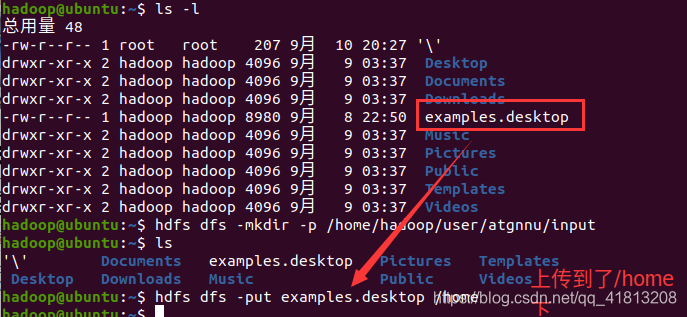
在/opt/module/hadoop-2.7.7下执行下列命令hdfs dfs -mkdir -p /home/hadoop/user/atgnnu/input
这里注意一下!!!创建成功后没有任何提示,该目录不存在真实机上!
创建成功后下面可以查看到
测试上传文件到文件系统上
上传examples.desktop文件 到home下hdfs dfs -put examples.desktop /home注意命令格式
hdfs dfs -put 想要上传的文件 上传到对应的目录(该目录必须要用上面的命令创建,原因是目录必须有hadoop已经管理的) 成功点击上面红框查看到根目录下的home文件夹,点进去后可以查看到子目录
所以 你可以随便找个文件替换上面的examples.desktop文件
上传成功的可以在浏览器上找到上传的文件,以及可以下载下来查看文件
Block Size表示 存放文件的最小单位,一块占128MB,可以后面更改,节约空间命令参数: -put 上传文件到/user/atguigu/input/下 hdfs dfs -put wcinput/wc.input /user/atgnnu/input/ -ls 查看文件是否正确 hdfs dfs -ls /user/atgnnu/input/ 运行mapreduce hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/atgnnu/input/ /user/atgnnu/output -cat 查看输出结果 hdfs dfs -cat /user/atgnnu/output/* -get 测试文件内容下载到本地 hdfs dfs -get /user/atgnnu/output/part-r-00000 ./wcoutput/ -rm -r 删除输出结果 hdfs dfs -rm -r /user/atgnnu/output





伪分布式模式二:YARN方式启动集群
第一步、配置yarn 集群环境
- 修改yarn-env.sh
vim /opt/software/hadoop-2.7.7/etc/hadoop/yarn-env.sh和之前一样配置JAVA_HOME环境变量,环境变量的获取用echo $JAVA_HOME获取jdk的路径
/opt/software/jdk1.8.0_211/ #不要看到就复制粘贴,看上面的讲解!这个路径是通过上面查询到JAVA_HOME的值
- 修改yarn-site.xml
vim /opt/software/hadoop-2.7.7/etc/hadoop/yarn-env.sh<!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
- 修改mapred-env.sh 和前面一样配置JAVA_HOME
vim /opt/software/hadoop-2.7.7/etc/hadoop/mapred-env.sh/opt/software/jdk1.8.0_211/ #不要看到就复制粘贴,看上面的讲解!这个路径是通过上面查询到JAVA_HOME的值- 修改mapred-site.xml
先cp复制一个模板文件并且命名去掉template后缀cp /opt/software/hadoop-2.7.7/etc/hadoop/mapred-site.xml.template /opt/software/hadoop-2.7.7/etc/hadoop/mapred-site.xmlvim /opt/software/hadoop-2.7.7/etc/hadoop/mapred-site.xml复制下面的代码到<confuguration></configuration>标签内
<!-- 指定MR运行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
第二步、启动集群
(用jps查看一下)首先保证namenode 和 datanode启动起来
如果配置了hadoop环境变量则可以直接输入下面两条命令,没有配置则找前面的完整路径启动
启动了就不需要运行下面命令:hadoop-daemon.sh start namenode; hadoop-daemon.sh start datanode配置了环境变量则可以简写
yarn-daemon.sh start resourcemanager; yarn-daemon.sh start nodemanager绝对路径运行:
/opt/software/hadoop-2.7.7/sbin/yarn-daemon.sh start resourcemanager/opt/software/hadoop-2.7.7/sbin/yarn-daemon.sh start nodemanager操作集群:浏览器输入虚拟机的外网ip:8088得到下面的结果表示正常
- 删除文件系统的输出文件(如果不存在则不需要操作!)
命令行输入,格式如下hdfs dfs -rm -R 输出文件的文件位置- 执行MapReduce程序(下面是一条命令)
命令格式 hadoop jar mapreduce的jar包 输入路径(浏览器可以访问到的)如下图url的 输出路径(不能提前存在)hadoop jar /opt/software/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /home/hadoop/user/atgnnu/input /home/hadoop/user/atgnnu/output- 查看运行结果
hdfs dfs -cat /home/hadoop/user/atgnnu/output/*配置历史服务器
- 修改mapred-site.xml;
vim /opt/software/hadoop-2.7.7/etc/hadoop/mapred-site.xml<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>localhost:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>localhost:19888</value> </property>






完全分布式:
