1. 二维码背景
自从微信推广二维码以来,在各个领域二维码的使用越来越广泛,几乎覆盖了各行各业,甚至连一些软件也使用二维码来登陆。那么在二维码登陆的背后是什么原理呢?
2. 解析二维码
我们要登陆PC版微信,需要扫描的图片如下:

我们通过解析路径发现其指向的路径为https://login.weixin.qq.com/l/obsbQ-Dzag==。那么这个网址有什么用呢?它是怎么来实现和登陆的用户相绑定的功能呢?
3.原理过程分析
自己懒得再画图,这边借用别人的图来解释。
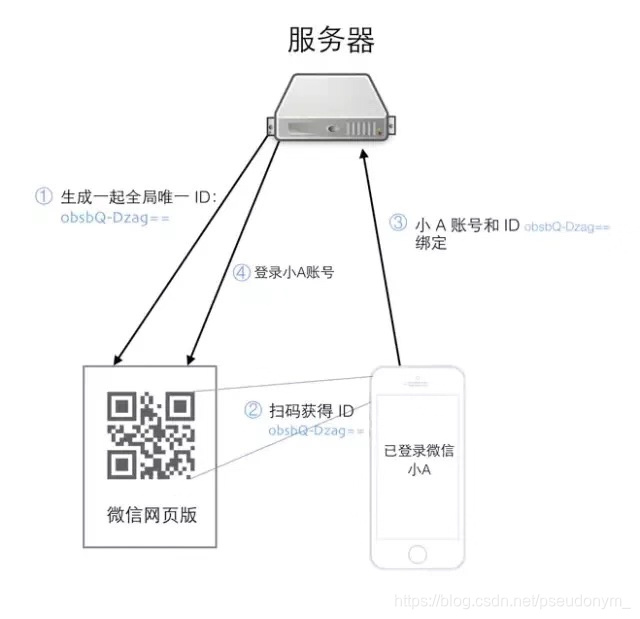
<1>用户访问微信网页版,此时微信服务器会为其生成一个全局唯一的UUID。然后这个UUID就存放在上面路径https://login.weixin.qq.com/l/obsbQ-Dzag==的后面,此时该操作并没有和用户有交互,所以该ID仅仅是个唯一字符串而已,系统并不知道该ID会和哪个用户相绑定。
如果过此时你不断地刷新,你会发现每次的ID都会发生过变化。感兴趣的可以自己手动来抓包,这里就不做示范了。注意:此时服务器和更改你网页还会建立一个长连接,为了节约系统资源,如果一段时间不扫描,便会超时。返回状态为408。
<2>用户扫描PC端的二维码,返回状态码为201,并且生成一个询问,是否登录。这个步骤的目的是为了获取起生成的全局唯一UUID,为了下一步和微信绑在一起。
<3>用户如果此时点击确认登陆,则会像系统发送一条请求,并且将UUID和用户账号(或者token)一块发送过去。
<4>系统受到这一步的目的是将UUIIDI和用户账号(或token)绑定在一起,因为二者都是唯一,便可以确定唯一的对应关系。处理完该关系后,系统会向PC端反馈消息,这个UUID对应的用户是A,然后网页便可请求加载A的微信信息和资料。
4.总结
二维码扫描看起来好像很高大上,其实原理还是比较简单的。首先浏览器获取一个唯一的、临时的UUID,然后等待用户扫描,如果扫描并且确认,后台系统就会将二者绑定,然后发送也浏览器这个UUID绑定的用户信息。从而确定对应关系。
注意:在超时、网络断开、或者其他设备浏览器上登陆后,,此前绑定的UUID将会失效,这样会形成更有效的安全防护。有些二维码不能扫是因为它会访问钓鱼网站,从而造成财产直接或间接流失。
