MapReduce框架原理之OutputFormat数据输出
OutputFormat数据输出
相较于InputFormat,OutputFormat相对而言简单些.
OutPutFormat是MapReduce输出的基类,所有MapReduce输出都实现了OutputFormat接口.
1. 文本输出TextOutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写成文本行.它的键值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换成字符串.
2. SequenceFileOutputFormat
将SequenceFileOutputFormat输出作为后续的MapReduce任务的输入,这是一种好的输入格式,因为它存储的是二进制格式,格式紧凑,易于压缩.
3. 自定义OutputFormat
(1)自定义一个类, 继承FileOutputFormat类
(2)自定义一个RecordWriter类,继承RecordWriter类,具体改写输出数据的方法write()
4. 代码实现
OutputFormat类
package outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OPFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
return new OPRecordWriter(context);
}
}
RecordWriter类
package outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class OPRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream google = null;
private FSDataOutputStream other = null;
public OPRecordWriter(TaskAttemptContext job) throws IOException {
Configuration conf = job.getConfiguration();
FileSystem fs = FileSystem.get(conf);
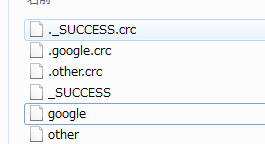
Path gPath = new Path("i:\\op_output\\google");
Path oPath = new Path("i:\\op_output\\other");
google = fs.create(gPath);
other = fs.create(oPath);
}
@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
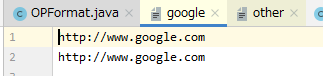
if (text.toString().contains("google")) {
google.write(text.getBytes());
google.write("\n".getBytes());
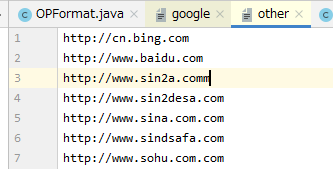
} else {
other.write(text.getBytes());
other.write("\n".getBytes());
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
IOUtils.closeStream(google);
IOUtils.closeStream(other);
}
}
Mapper类
package outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OPMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
Reducer类
package outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class OPReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for (NullWritable value : values) {
context.write(key, NullWritable.get());
}
}
}
Driver类
package outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OPDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path oPath = new Path("i:\\op_output");
if (fs.exists(oPath)) {
fs.delete(oPath, true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(OPDriver.class);
job.setMapperClass(OPMapper.class);
job.setReducerClass(OPReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(OPFormat.class);
FileInputFormat.addInputPath(job, new Path("i:\\op_input"));
FileOutputFormat.setOutputPath(job, oPath);
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}