在spark给出的闭包清理器中的代码注释中,关于闭包的例子,给出了一个类作为例子,稍作修改如下。
class SomethingNotSerializable {
def someMethod(): Unit = scope("one") {
def y = someValue
scope("two") {
println(y + 1)
}
}
def someValue = 1
def scope(name: String)(body: => Unit) = body
}在这个类中,可以看到,通过scope()函数分别实现了两层闭包。

其中,除了最外部的class文件的基础上,还生成了另外两个class文件,这两个就是scala中的闭包产生的函数class文件,可以从其名字带有$anonfun$中看出其为闭包的class文件。同时,在scope(“one”)函数中的方法体中也通过scope(“two”),产生了嵌套闭包,所以产生第二个闭包class。
通过javap -v命令查看闭包class文件的字节码。查看第一层嵌套的闭包class文件,在上面的代码中,可以看到在someMethod()函数中,定义了y()函数。在y()函数的定义中,设计到了外部函数someValue(),显然这里就是闭包操作将要引用的地方,看到y()函数的字节码。
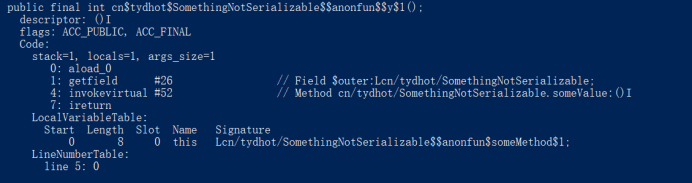
这里的字节码引用了外部类的某个field,这里可以试图通过getField指令得到对应的函数的MethodRef,并在下一个指令中调用,这里所需要的目标对象的field则是以$outer指代的闭包外部对象,也就是上文中的类SomethigNotSerializable。
再回到构造函数。

可以在构造方法中清楚地看到,外部类将以$outer的名字存放在本地变量表中,以便通过$outer指针获取闭包所需要的资源。同时,此处将会通过putfiled命令给其赋值。
由于该class文件中还有一层闭包嵌套,直接看到class文件的innerClass部分,可以看到其内部类,其嵌套的闭包也在其中。
![]()
回到spark的闭包清理器closureCleaner,每个spark的算子在调用时都会通过clean()方法来对闭包的资源进行清理,实则调用到的正是closureCleaner,也正是对上文的$outer的处理。
主要逻辑实现在其clean()函数中,目标类为func。
if (!isClosure(func.getClass) && lambdaFunc.isEmpty) {
logDebug(s"Expected a closure; got ${func.getClass.getName}")
return
}首先,将会通过isClosure()函数判断是否为闭包类。
private def isClosure(cls: Class[_]): Boolean = {
cls.getName.contains("$anonfun$")
}具体逻辑很简单,就如上文所示,直接判断其名称是否包含$anonfun$即可简单判断。
而后,将会通过getOuterClassesAndObejct()函数获取func中所有对于外部闭包对象的引用。
private def getOuterClassesAndObjects(obj: AnyRef): (List[Class[_]], List[AnyRef]) = {
for (f <- obj.getClass.getDeclaredFields if f.getName == "$outer") {
f.setAccessible(true)
val outer = f.get(obj)
// The outer pointer may be null if we have cleaned this closure before
if (outer != null) {
if (isClosure(f.getType)) {
val recurRet = getOuterClassesAndObjects(outer)
return (f.getType :: recurRet._1, outer :: recurRet._2)
} else {
return (f.getType :: Nil, outer :: Nil) // Stop at the first $outer that is not a closure
}
}
}
(Nil, Nil)
}如上文所说,实则实在遍历class文件中的所有field,找到$outer的就是外部的闭包引用,同时,如果外部闭包引用也是闭包类,那么同样获取其外部,直到最外层的非闭包类。
而后,禁止func中出现return返回值,在这里扫描,如果出现return直接报错。
getClassReader(func.getClass).accept(new ReturnStatementFinder(), 0)
private class ReturnStatementFinder(targetMethodName: Option[String] = None)
extends ClassVisitor(ASM6) {
override def visitMethod(access: Int, name: String, desc: String,
sig: String, exceptions: Array[String]): MethodVisitor = {
// $anonfun$ covers Java 8 lambdas
if (name.contains("apply") || name.contains("$anonfun$")) {
// A method with suffix "$adapted" will be generated in cases like
// { _:Int => return; Seq()} but not { _:Int => return; true}
// closure passed is $anonfun$t$1$adapted while actual code resides in $anonfun$s$1
// visitor will see only $anonfun$s$1$adapted, so we remove the suffix, see
// https://github.com/scala/scala-dev/issues/109
val isTargetMethod = targetMethodName.isEmpty ||
name == targetMethodName.get || name == targetMethodName.get.stripSuffix("$adapted")
new MethodVisitor(ASM6) {
override def visitTypeInsn(op: Int, tp: String) {
if (op == NEW && tp.contains("scala/runtime/NonLocalReturnControl") && isTargetMethod) {
throw new ReturnStatementInClosureException
}
}
}
} else {
new MethodVisitor(ASM6) {}
}
}
}之后,在验证完没有return返回值,确认完所有的外部引用对象,之后只要再次确认所有外部对象中被引用到的field就可以准备进行相应的复制与对应值的赋值。
if (accessedFields.isEmpty) {
logDebug(" + populating accessed fields because this is the starting closure")
// Initialize accessed fields with the outer classes first
// This step is needed to associate the fields to the correct classes later
initAccessedFields(accessedFields, outerClasses)
// Populate accessed fields by visiting all fields and methods accessed by this and
// all of its inner closures. If transitive cleaning is enabled, this may recursively
// visits methods that belong to other classes in search of transitively referenced fields.
for (cls <- func.getClass :: innerClasses) {
getClassReader(cls).accept(new FieldAccessFinder(accessedFields, cleanTransitively), 0)
}
}所有外部类所被引用的字段将会被存储在accessedFields中,在后面的操作判断是否被引用到。
之后,将会开始对所有出现过的$outer进行初始化与克隆。
for ((cls, obj) <- outerPairs) {
logDebug(s" + cloning the object $obj of class ${cls.getName}")
// We null out these unused references by cloning each object and then filling in all
// required fields from the original object. We need the parent here because the Java
// language specification requires the first constructor parameter of any closure to be
// its enclosing object.
val clone = cloneAndSetFields(parent, obj, cls, accessedFields)
// If transitive cleaning is enabled, we recursively clean any enclosing closure using
// the already populated accessed fields map of the starting closure
if (cleanTransitively && isClosure(clone.getClass)) {
logDebug(s" + cleaning cloned closure $clone recursively (${cls.getName})")
// No need to check serializable here for the outer closures because we're
// only interested in the serializability of the starting closure
clean(clone, checkSerializable = false, cleanTransitively, accessedFields)
}
parent = clone
}
if (parent != null) {
val field = func.getClass.getDeclaredField("$outer")
field.setAccessible(true)
// If the starting closure doesn't actually need our enclosing object, then just null it out
if (accessedFields.contains(func.getClass) &&
!accessedFields(func.getClass).contains("$outer")) {
logDebug(s" + the starting closure doesn't actually need $parent, so we null it out")
field.set(func, null)
} else {
// Update this closure's parent pointer to point to our enclosing object,
// which could either be a cloned closure or the original user object
field.set(func, parent)
}
}在这里,前面扫描得到的$outer对象都会在这里被深克隆一份,其所需要被引用的字段也将被专门赋值到被克隆的对象上以便闭包类进行引用。而后回到被清理的闭包类func中,如果func中的assessedField中不存在该$outer的field,也就是闭包函数中并没有用到外部的这个对象,将会直接被赋值为null,达到减少网络传输和降低序列化要求的目的,否则将会直接被赋值在该field上。
闭包清理器ClosureCleaner的主要流程也结束。
