Hadoop系列文章 SpringBoot编程实现HDFS读写文件、MapReduce程序实现
在Apache Hadoop 2中。Apache已经将资源管理功能剥离到Apache Hadoop
YARN中,这是一个通用的分布式应用管理框架,而Apache Hadoop
MapReduce(又名MRv2)仍然是一个纯粹的分布式计算框架。
一般来说,以前的MapReduce运行时(又称MRv1)已经被重用,并且没有对其进行重大的操作。因此,MRv2能够确保与MRv1应用程序的兼容性。然而,由于一些改进和代码重构,一些api被呈现为向后不兼容的。
首先hadoop运行程序要以jar包为主体,我用的是springboot项目,在生成jar包时用jar命令,用bootJar命令生成的jar包会有各种问题。
HDFS操作
引入依赖
// ========== HADOOP 相关
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common
compile group: 'org.apache.hadoop', name: 'hadoop-common', version: '3.2.1'
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs
compile group: 'org.apache.hadoop', name: 'hadoop-hdfs', version: '3.2.1'
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client
compile group: 'org.apache.hadoop', name: 'hadoop-client', version: '3.2.1'
compile group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-core', version: '3.2.1'
winutils
winutils是在windows平台使用hadoop的必要组件!
码代码
读取HDFS中的文件
@Test
public void testProc() throws IOException {
log.info("hello lombok and hdfs");
// 设置winutils目录
System.setProperty("hadoop.home.dir", "F:\\hadoop\\hadoop-3.0.0");
// 读取hdfs中的配置文件 : org.apache.hadoop.conf.Configuration
Configuration configuration = new Configuration();
// org.apache.hadoop.hdfs.DFSUtil
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//设置使用hdfs分布式文件系统,指定hdfs实现类,不然将会出现访问错误
// 设置hdfs uri
configuration.set("fs.defaultFS", "hdfs://192.168.84.132:9000");
// org.apache.hadoop.fs.FileSystem 获取文件系统
org.apache.hadoop.fs.FileSystem fileSystem = org.apache.hadoop.fs.FileSystem.get(configuration);
// 读取文件 , try-with-resources 自动关闭资源
try (FSDataInputStream fsDataInputStream = fileSystem.open(new Path("/root/test/index.html"))) {
// IOUtils.copyBytes(fsDataInputStream, System.out, 4096, true); , 读取并写到控制台
IOUtils.copyBytes(fsDataInputStream, System.out, 4096, true);
}
}

写内容到文件中
要确保将操作的目录“其它”用户有权限操作哦,可以使用hdfs dfs -chmod 777 /root/test开放某个目录的权限。

@Test
public void testProc2() throws IOException {
log.info("hello lombok and hdfs 写一些东西到hdfs文件中");
// 设置winutils目录
System.setProperty("hadoop.home.dir", "F:\\hadoop\\hadoop-3.0.0");
// 读取hdfs中的配置文件 : org.apache.hadoop.conf.Configuration
Configuration configuration = new Configuration();
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//设置使用hdfs分布式文件系统 设置使用hdfs分布式文件系统,指定hdfs实现类,不然将会出现访问错误
// 获取配置
configuration.set("fs.defaultFS", "hdfs://192.168.84.132:9000");
// org.apache.hadoop.fs.FileSystem
org.apache.hadoop.fs.FileSystem fileSystem = org.apache.hadoop.fs.FileSystem.get( configuration);
// 写文件 , try-with-resources 自动关闭资源
try (FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/root/test/second.index") , false)) {
fsDataOutputStream.writeUTF("now everything is control");
fsDataOutputStream.writeUTF("now everything is control");
fsDataOutputStream.writeUTF("now everything is control");
}
}

MapReduce操作
码代码
package cn.MapReduce;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 词频程序
*/
@Slf4j
public class WordCountT {
public static Text k = new Text();
public static IntWritable v = new IntWritable();
/**
* map阶段实现类
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* input中的每一行会调用一次map方法
* value是每一行的数据
* context是MapReduce的上下文
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
log.info("进入map阶段"+key);
//
// super.map(key, value, context);
// 将input文件中的一行行的数据进行处理
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
k.set(word);
v.set(1);
// 将每一行的每一个单词放入上下文中,给reduce处理。
context.write(k,v);
}
}
}
/**
* 从map到reduce的过程中MapReduce会对数据进行一些处理,合并key,将key-value对中的value做成一个value迭代器集合
*/
/**
* reduce阶段的输入key、value类型必须要与map阶段的输出key、value类型一致
*/
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
*
* @param key 是在map阶段处理完的数据key
* @param values 在map阶段处理完的value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
log.info("进入reduce阶段");
// super.reduce(key, values, context);
int counter = 0;
for (IntWritable value : values) {
counter += value.get();
}
log.info(" --------- key:"+key+" count:"+counter);
context.write(key ,new IntWritable(counter));
}
}
/**
* 驱动类
* @param args
* args[0] 为输入文件的路径
* args[1] 为结果输出的路径
* @throws IOException
* @throws ClassNotFoundException
* @throws InterruptedException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// System.setProperty("hadoop.home.dir", "F:\\hadoop\\hadoop-3.0.0");
// 读取hdfs中的配置文件 : org.apache.hadoop.conf.Configuration
org.apache.hadoop.conf.Configuration configuration = new Configuration();
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//设置使用hdfs分布式文件系统 设置使用hdfs分布式文件系统,指定hdfs实现类,不然将会出现访问错误
// 获取配置 , 连接到hdfs
configuration.set("fs.defaultFS", "hdfs://192.168.84.132:9000");
// ========================================================
// 设置Job实例的各个参数
// job名字
Job job = Job.getInstance(configuration, "mywordcountT");
// 指定job类
job.setJarByClass(WordCountT.class);
// 指定map类
job.setMapperClass(MyMapper.class);
// 指定map输出key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定数据输入路径
org.apache.hadoop.mapreduce.lib.input.FileInputFormat.addInputPath(job,new Path(args[0]));
// 指定reduce类及输出key、value类型
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 等待job完成
int isok = job.waitForCompletion(true) ? 0 : 1;
log.info("词频程序运行结束。");
System.exit(isok);
}
}
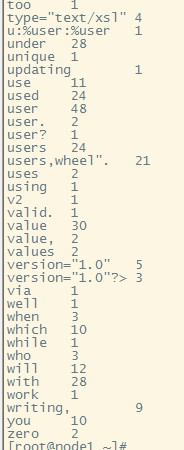
将程序放到服务器中运行
# hadoop jar /root/hhwordcount6.jar cn.MapReduce.WordCountT /root/input/ /root/output

# hdfs dfs -cat /root/output/part-r-00000