字符串有关函数:
- 字符串的片和下标(索引)
字符串是一个数组,python中叫元组。片是字符串的子序列(与集合相比有顺序),索引和c一样。
表与元组类似,但是元组不可修改表可以
s="hello"
s1=s[0:4]
print(s1)
print(len(s))
s=[1,2,3,4,5,"123"]
print(s)
print(s[2])
t="hello"
for i in range(len(t)):
print(i,t[i])
v=range(0,20,5)
for i in v:
print(i)
- expandtabs(self:str,arg:int) 延长字符串中制表符的长度,使得字符串制表符之间,开端与制表符之间,末尾与制表符之间的非空字符数目加空格字符数目达到参数arg个
s='name\tyears\tjob'
s1='wwt\t34\tKing'
s=s.expandtabs(20)
s1=s1.expandtabs(20)
print(s)
print(s1)
结果:

- isalnum(self:str),isalpha(self:str),isdecimal(self:str),isdigit(self:str)isnumeric(self:str) 判断是否字符串只由字母组成,只由字母数字组成,只由10进制数字组成,只有数字含义字符,只由数字组成,可以打印(不可打印如:\t \n),可为变量名(符合命名规范),只有空格组成
s1="English12"
s="{0},{1}"
s2=s.format(s1.isalnum(),s1.isalpha())
print(s2)
s="②"
s1="{v1},{v2}"
s2=s1.format(v1=s.isdecimal(),v2=s.isdigit())
print(s2)
s="2616"
s1="一"
print(s.isnumeric(),s1.isnumeric())
s="\nand\t"
print(s.isprintable())
s="m_found"
s2="8_u"
s1=s.isidentifier()
print(s1,s2.isidentifier())
s=" "
print(s.isspace())
注:定义一个字符串为Unicode,只需要在字符串前添加 ‘u’ 前缀即可
- translate(self:str,arg:table) 根据表翻译字符串
- replace(self:str,arg1:str,arg2:str根据arg1与arg2的映射翻译字符串
- maketrans(arg1:str,arg2:str) 由两个字符串生成字典
s="12345"
sa="abcde"
sd="c"
sb=str.maketrans(s,sa,sd)
b="a1bcde".translate(sb)
c="abcde".replace("bc","01")
print(b)
print(c)
- partition(self:str,arg:str) 根据参数字符串分割字符串成片,返回该元组
- rpartition(self:str,arg:str) 同上不同在于参数字符串从右匹配
- split(self:str,arg:int) 同上类似但可匹配多次也就可以分割多次(arg+1次)返回结果为表
- swapcase(self:str) 将字符串中大写变小写,小写变大写,返回结果
s="shadodw"
sa=s.partition("d")
sb=s.rpartition("d")
sc=s.split("d",2)
sd=s.swapcase()
print(sa,sb,sc,sd)
结果:
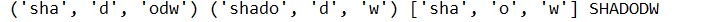
-
strip(self:str,arg:str) 脱去字符串左右边沿的子序列返回处理后的字符串
-
rstrip(self:str,arg:str) 脱去字符串右边沿的子序列返回处理后的字符串
-
lstrip(self:str,arg:str) 脱去字符串左边沿的子序列返回处理后的字符串
无参时 默认为去除空格 -
join(self:str,arg:str) 对字符串做填充处理,每个字符之间填充一个arg,返回结果字符串
-
ljust(self:str,arg1:int,arg2:str) 在字符串左边沿做填充处理,填充后总长arg1,填充内容为arg2
-
rjust(self:str,arg1:int,arg2:str) 在字符串右边沿做填充处理,填充后总长arg1,填充内容为arg2
s=" shshshineine"
sa=s.strip("ine")
sb=s.strip()
sc="shshshxshsh".lstrip("sh")
print(sc)
print(sa)
print(sb)
s="你是风儿我是沙"
sa=" ".join(s)
print(sa)
sb=s.ljust(20,"_")
sc=s.rjust(20,"_")
print(sb,sc)
结果:

