等把一本书全部看完后,再做调整,此处为整理部分。
两种链表类型:
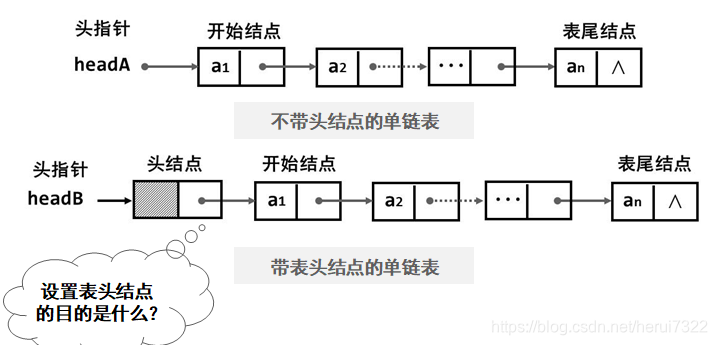
头结点有无有什么区别呢?
在表示空表时:有头结点直接head->next=null即可;没有头结点头指针指向为空。
在操作时需要判断是否在开始结点,那么在插入、删除等操作同样要判断当前位置。
所以加入头结点后,发现无需对开始结点特殊处理。
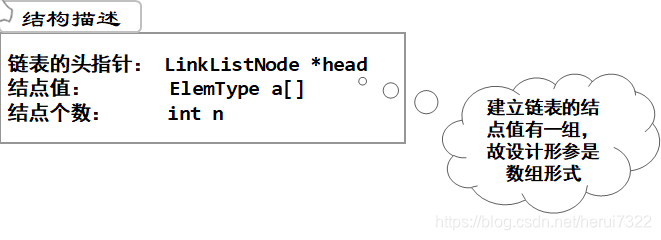
1.链表结构描述:
-
List item
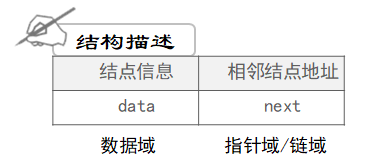
存数据存联系:data存储数据,next指向下一个节点。那么这种结构有什么优点呢? 它的特点是(存储地址不相邻可以在逻辑上相邻)
关于链表结点分配
- 静态分配
- 动态分配(在程序运行中申请得到的)
(1)结点的申请
p=(LinkListNode *)malloc(sizeof(LinkListNode));
函数malloc()分配一个大小为LinkListNode字节的空间,并将其首地址
放入指针变量p中。
(2)节点的释放
free(p);
释放p所指的结点变量空间。
(3)结点数据项的访问
利用结点指针p访问结点分量。
方法一:(*p).data 和 (*p).next
方法二: p->data 和 p->next
2.单链表的运算:
| 基本操作 |
|---|
| 1初始化 |
| 2建链表 |
| 3查找 |
| 4删除 |
| 5插入 |
- 1.单链表初始化
构造一个只有头结点的单链表。
/*==========================================
函数功能:单链表运算——初始化
函数输入:无
函数输出:链表头指针
============================================*/
LinkListNode *initialize_LkList(void)
{
LinkListNode *head;
head=(LinkListNode *)malloc(sizeof(LinkListNode)); //申请一个结点
if(head==NULL) exit(1); //存储空间分配失败
head->next=NULL; //指针域置空
}
注意:一般对申请空间极少的程序而言,动态申请新结点空间是不会出现问题。
但在实用程序里,尤其是对空间需求极大的程序,凡是涉及动态申请空间,一定要判断
空间是否申请成功,以防系统无空间可供分配。
思考:一般c语言书上会建议,不要返回局部量的地址,在InitList函数中head是局部量,这样的设计是否可靠呢?(下面介绍我也没弄明白,可以不看)
暂时我用不到,这一段也没看懂,在此展示一段测试代码及相关内容。
| 功能描述 | 输入 | 输出 |
|---|---|---|
| 创建一结构节点空间CreateNode | 无 | 结构结点空间地址LinkListNode * |
| 函数名 | 形参 | 函数类型 |
创建结点方式1:通过malloc函数申请,此种方式得到的内存空间在“堆”中。
创建结点方式2:通过定义结构变量,此种方式得到的内存空间在“栈”中。
测试程序如下:
//栈与对空间地址传递的测试
#include<stdio.h>
#include<malloc.h>
typedef struct node
{
int data;
struct node *next;
} LinkListNode;
LinkListNode *CreateNode(void)
{
LinkListNode *p,*Heap,Stack;
//Heap指向空间通过malloc函数申请,在堆中分配
Heap=(LinkListNode *)malloc(sizeof(LinkListNode));
Heap->data=6;
Heap->next=NULL;
//Stack变量空间在栈中分配
Stack=*Heap;//将Heap结点的内容复制给Stack结点
p=&Stack;
p=Heap;
return p;
}
int main()
{
LinkListNode *head,*x;
int y;
head=CreateNode();
x=head;
printf("%x:%d%d\n",x,x->data,x->next);
y=x->data;
printf("%x:%d%d\n",x,y,x->next);
return 0;
}
程序结果一:
在程序21行关闭,22行有效,即返回Heap空间地址时,程序执行的结果
程序结果二:
在程序22行关闭,21行有效,即返回Stack空间地址时,程序执行的结果
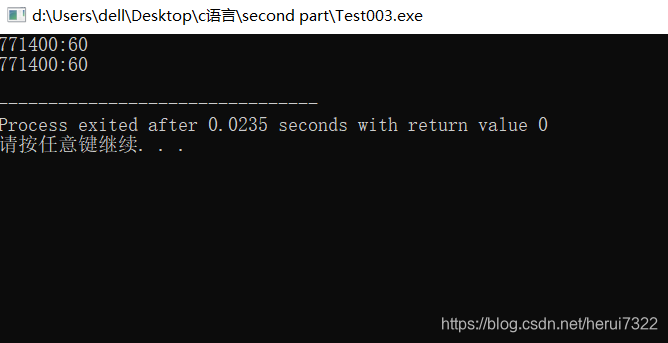
测试结果跟预想不一样,程序二跟预想出现差异。
思考结论:
在栈中分配的局部量地址,传递给主函数后,由于局部量空间被系统释放,
其间的内容随即失效——“将指针值作为函数的返回值时,不要返回一个局部量的地址。”
在堆中分配的空间虽然也是子函数局部量,但传递给主函数时,
由于这部分空间是由当前运行程序控制的,并未被释放,故而内容依然保留。
- 2.建立单链表
将线性表n个元素存放在一个单链表中,head为头指针。
1 ) 尾插法建立单链表
通过不断在单链表的尾部插入结点的方法来建立链表。
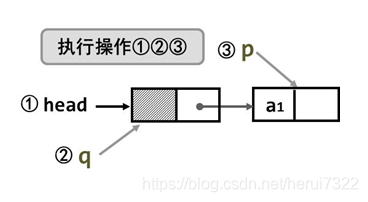
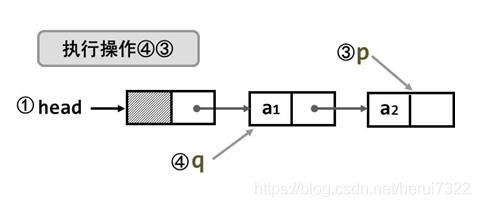
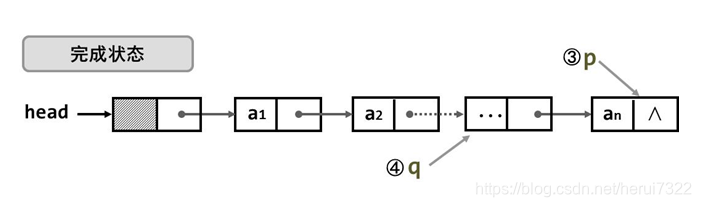
(1)申请头结点head head=malloc(sizeof(LinkListNode));
(2)前趋结点q=head q=head;
(3)申请当前结点p; p=malloc(sizeof(LinkListNode));
向p结点中添入结点值; p->data=a[i];
p的地址填入前趋q指针域; q->next=p;
(4)q=p q=p;
(5)尾结点指针域置NULL p->next=NULL;
重复步骤3~4直到结点数目满足要求为止
------------------------表2.1 尾插法建链表函数结构

——数据结构:头指针——>结点-------->结点——>尾结点
之前的数据结构中定义了struct node类型,包含data和next;initialize_LkList函数中分配了head指针。
- 尾插法创建单链表代码
/*===========================================
函数功能:单链表操作——尾插法建立链表
函数输入:结点值数组,结点个数
函数输出:链表的头指针
=============================================*/
LinkListNode *Create_Rear_LkList(ElemType a[],int n )
{
LinkListNode *head,*p, *q;
int i;
head=(LinkListNode *)malloc(sizeof(LinkListNode));
q=head;
for(i=0;i<n;i++)
{
p=(LinkListNode *)malloc(sizeof(LinkListNode));
p->data=a[i];
q->next=p;
q=p;
}
p->next=NULL;
return head;
2 ) 头插法建立单链表
——从一个空表开始,通过不断在单链表头部插入结点的方法来建立链表。
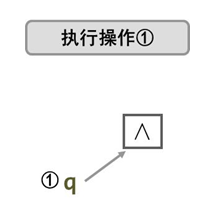
- 方法一
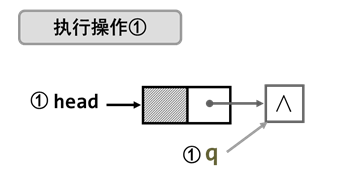
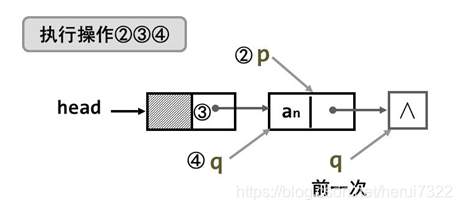
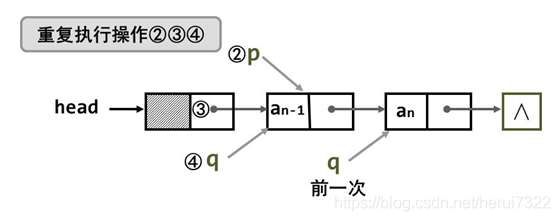

思考:头结点与p相连 与 p结点与q相连顺序颠倒一下可不可以?
- 前插法方法一c代码
/*===========================================
函数功能:单链表操作——头插法建立链表方法1
函数输入:结点值数组,结点个数
函数输出:链表的头指针
=============================================*/
LinkListNode *Create_Front1_LkList(ElemType a[], int n )
{
LinkListNode *head, *p, *q;
int i;
head=(LinkListNode *)malloc(sizeof(LinkListNode));
head->next=NULL;
q=head->next;
for(i=n-1; i>=0; i--)
{
p=(LinkListNode *)malloc(sizeof(LinkListNode));
p->data=a[i];
p->next=q;
head->next=p;
q=head->next;
}
- 方法二
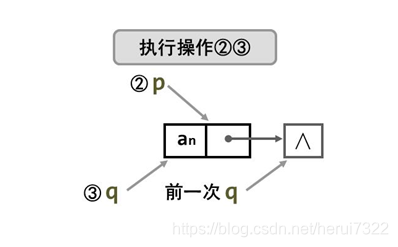
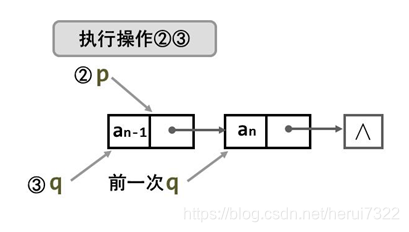

尾部前插c代码:
/*===========================================
函数功能:单链表操作——头插法建立链表方法2
函数输入:结点值数组,结点个数
函数输出:链表的头指针
=============================================*/
LinkListNode *Create_Front2_LkList(ElemType a[],int n )
{
LinkListNode *head, *p, *q;
int i;
q=NULL;
for(i=n-1; i>=0; i--)
{
p=(LinkListNode *)malloc(sizeof(LinkListNode));
p->data=a[i];
p->next=q;
q=p;
}
head=(LinkListNode *)malloc(sizeof(LinkListNode));
head->next=q;
return head;
}
- 方法三
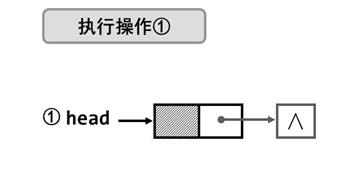
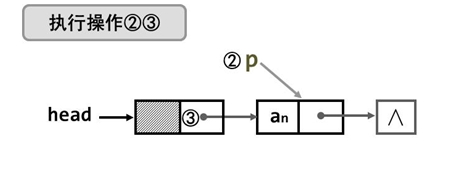
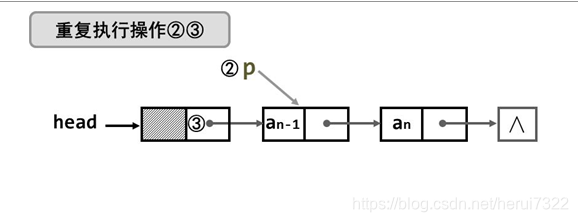

写的时候理顺关系,直接写就成。相关数据结构需要有结点值、*head、数组的大小n,以上都是。
程序实现:
/*===========================================
函数功能:单链表操作——头插法建立链表方法3
函数输入:结点值数组,结点个数
函数输出:链表的头指针
=============================================*/
LinkListNode *Create_Front3_LkList( ElemType a[],int n )
{
LinkListNode *head,*p;
int i;
head=(LinkListNode *)malloc(sizeof(LinkListNode));
head->next=NULL; //head指向的那块区域中data没赋初始值
for(i=n-1; i>=0; i--)
{
p=(LinkListNode *)malloc(sizeof(LinkListNode));
p->data=a[i];
p->next=head->next;
head->next=p;
}
return head;
}
3 . 单链表查找运算
单链表查找有两种方式,可以按值查找或按序号查找。
1)单链表中按值查找结点
意思是:在单链表中查找关键字
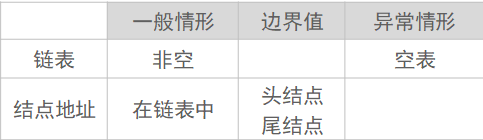
在设计前书写出所有情形
单链表按值查找——测试用例,代表性的测试数据,使具有完备性
输入:单链表头指针,要查找的关键字
输出:关键字所在结点的地址
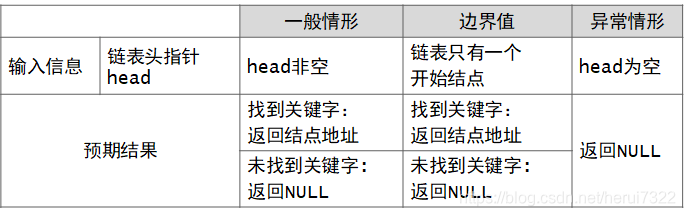
单链表按值查找——函数结构设计
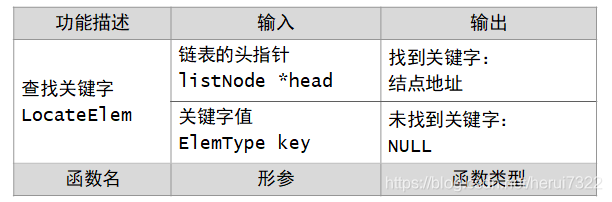
这个表,上功能区我能看出来,下边功能区始终还有疑问,去掉更好吗?
思考:关键字找不到时,输出NULL合适吗?
一般看课本上查找操作用返回的是boolean值,当然也要输出查找值的地址。这里返回地址,找不到关键字,应该返回和结点地址同类型的指针值,为了和正常的地址有区别,输出NULL是合适的。
单链表按值查找步骤:

思考:表非空,未找到——p=NULL
---------空表,head->next=NULL——p=NULL
这里关于NULL的定义:define NULL 0
=================================
程序实现:
/*===========================================
函数功能:单链表操作——按值查找结点
函数输入:链表的头指针,结点值
函数输出:找到:返回结点指针;未找到:返回NULL
=============================================*/
LinkListNode * Locate_LkList( LinkListNode *head, ElemType key)
{
LinkListNode *p;
p=head->next; //跳过表头结点
while(p != NULL && p->data != key ) //结点非空且结点值不是key
{
p=p->next; //p指向下一个结点
}
return p;
}
·
单链表中按序号查找结点
在单链表中查找第i个结点(头结点i=0)
测试用例设计
输入:单链表头指针,要查找的结点编号
输出:第i个结点的地址
·
测试用例取值范围如下表
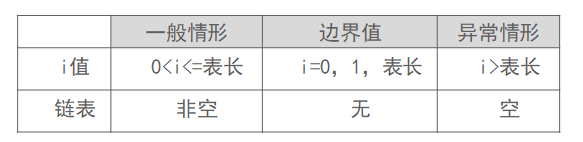
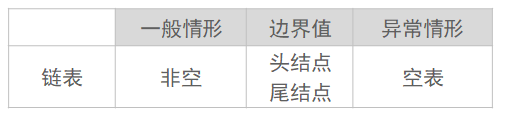
异常情形描述:
(1)表非空,i值出界;
(2)空表;
算法中函数正常返回找到的结点地址,异常可以返回NULL。
函数结构设计:

查找方法:
- 找到的情形:
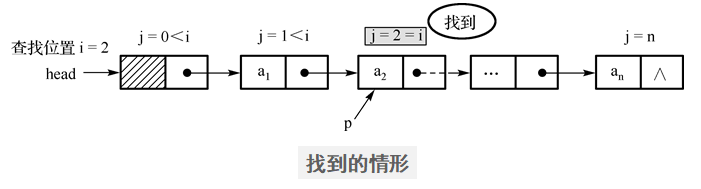
计数器“j” 置为“0”后,扫描指针p从链表的头结点开始顺着链扫描。当p扫描下一个结点时,计数器 j 相应地加 1 。
继续查找的条件:(1)j<i (2)p->next 非空
找到时的条件: (1)j=i (2) p非空
2.找不到的情形:
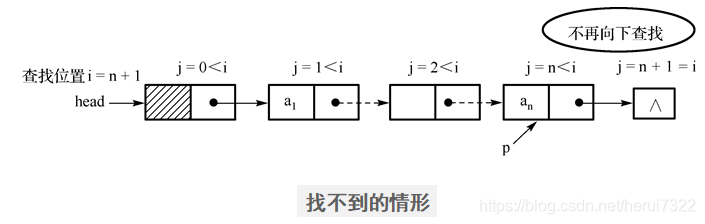
当p的后继为NULL且“j != i”时,则表示找不到第i个结点。
注意:头结点是第0个结点,把“ i=0 ”也归为异常。
算法描述:

问题:链表是不是随机存取结构?
(我去访问某一结点的时间相同就叫可以随机存取。)
答:在链表中,即使知道被访问结点的序号i,也不能像顺序表中那样直接按序号访问结点,而只能从链表的头指针出发,顺链域next逐个结点往下搜索,直至搜索到第 i 个结点为止。因此,链表不是随机存取结构。
程序实现:
/*===========================================
函数功能:单链表操作——按序号查找结点
函数输入:链表的头指针,待查结点序号
函数输出:找到:返回结点指针;未找到:返回NULL
=============================================*/
LinkListNode *Get_LkList(LinkListNode *head, int i )
{
int j;
LinkListNode *p;
p=head;j=0;
if (i==0) return NULL;
while( j<i && p->next != NULL) //未到达第i个结点且下一个结点非空
{
p=p->next;
j++;
}
if (i==j) return p; //找到第 i 个结点
else return NULL;
}
4.单链表的插入运算
在链表指定位置插入给定的值
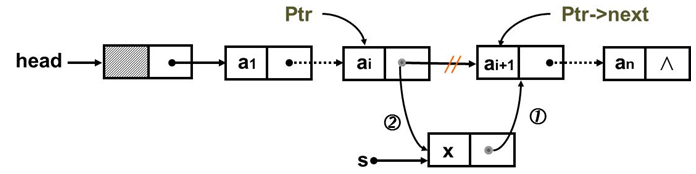
后插法介绍
示意图如下
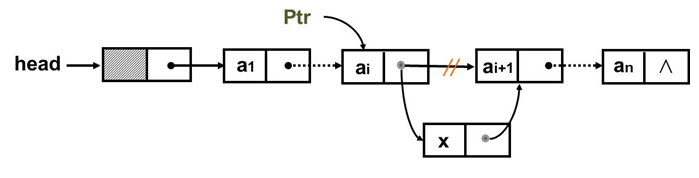
描述:在单链表结点a(i)之后插入x;已知a(i)的地址为Ptr
注释:ptr – pointer 指针
测试用例设计:
输入:插入点地址Ptr,待插入结点的值x
输出:无
设计用例取值范围
函数结构:
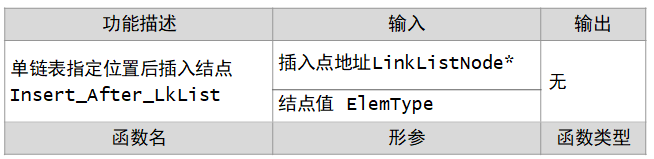
算法伪代码描述:

程序实现:
/*===========================================
函数功能:单链表操作——在指定位置后插入结点
函数输入:插入点地址,结点值
函数输出:无
=============================================*/
void Insert_After_LkList(LinkListNode *Ptr,ElemType x )
{
LinkListNode *s;
s=(LinkListNode*)malloc(sizeof(LinkListNode));
s->data=x;
s->next=Ptr->next;
Ptr->next=s;
}
·
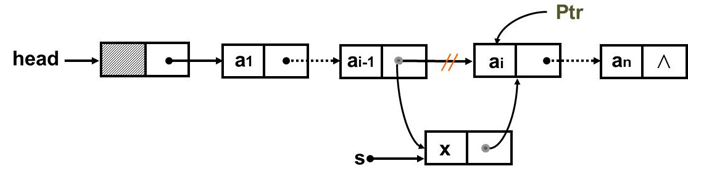
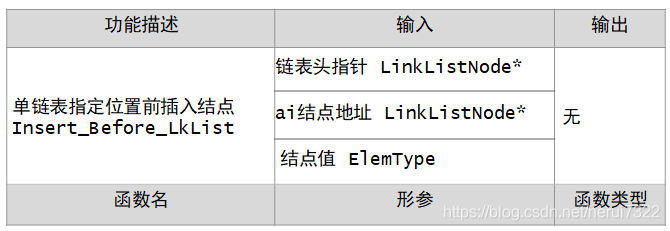
前插法
在单链表结点a(i)之前插入x;已知a(i)的地址为Ptr,如图
测试用例:
输入:
(1)链表头指针
(2)ai结点地址
(3)结点值x
输出:无
测试用例取值范围:
函数结构设计:
算法伪代码描述:
在指定的结点Ptr前插入值为x的结点

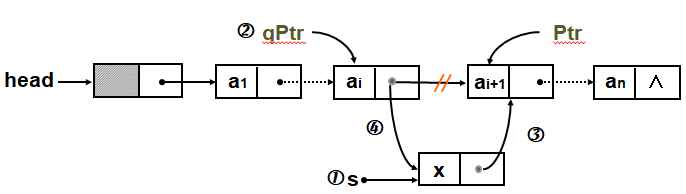
看到这我想到双链链表,虽然多花费了存储空间,多了front链域,不过“前插后插都很方便”,我只要改变:s->front=Ptr->front; Ptr->front->next=s; s->next=p; p->front=s;插入结点的两个链域和前一个结点的next域,插入位置的front域。
程序实现:
/*===========================================
函数功能:单链表操作——在指定位置后插入结点
函数输入:插入点地址,结点值
函数输出:无
=============================================*/
void Insert_After_LkList(LinkListNode *Ptr,ElemType x )
{
LinkListNode *s;
s=(LinkListNode*)malloc(sizeof(LinkListNode));
s->data=x;
s->next=Ptr->next;
Ptr->next=s;
}
===========================================================
5.单链表的删除运算
单链表结点的删除的方式按给定信息的不同,在此讨论两种方式。
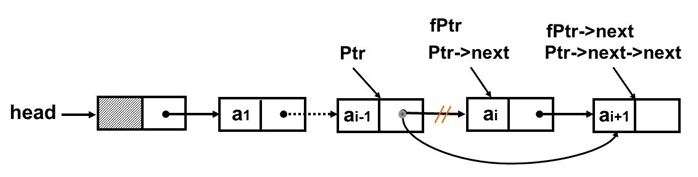
- 情形一:删除指定结点的后继结点,指定结点地址为Ptr
- 情形二:删除单链表第i个结点(头结点 i =0)
对于情形一,因为对给定结点地址异常是难以判断的。为了方便处理异常情形,可以在调用前判断异常情形,异常按异常状况处理,比如提示信息啊!
函数结构设计:
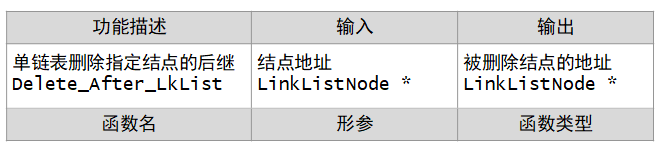
说明:函数返回的是被删除结点的地址,而没有释放这个节点空间,主要是考虑调用者有可能要继续使用这个结点信息,这个结点的释放时机将由调用者决定,有时这么处理是方便的,但一定要记着这个结点一旦不再使用,是要释放的(free(fPtr)),否则会造成内存泄漏。内存一直占着,可不泄露(变少)了。
算法伪代码描述:

程序实现:
/*===========================================
函数功能:单链表操作——删除指定结点的后继结点
函数输入:指定结点地址
函数输出:被删除结点地址
=============================================*/
LinkListNode * Delete_After_LkList( LinkListNode *Ptr)
{ LinkListNode *fPtr;
fPtr=Ptr->next;
Ptr->next=fPtr->next;
return fPtr;
}
情形二: 删除单链表指定结点 i
测试用例:
输入:链表头指针、结点编号
输出:被删除结点的地址
测试用例取值范围
函数结构设计:

算法伪代码描述

操作示意图

思考:关于单链表删除指定结点 i 中,异常情形是否都处理了。
GetElem 函数在找不到结点 i 时会返回NULL,在此情形下删除 i 后继的函数DeleterAfter(Ptr)将不会被执行,直接就返回qPtr了,故qPtr应该设置初值NULL,避免了再做DeleterAfter(Ptr)是否被执行的判断。
程序实现:
/*===========================================
函数功能:单链表操作——删除第i个结点
函数输入:链表头指针,结点编号
函数输出:正常:被删除结点地址;异常:NULL
=============================================*/
LinkListNode *Delete_i_LkList( LinkListNode *head, int i)
{ LinkListNode *Ptr,*qPtr=NULL;
Ptr=Get_LkList(head,i-1); //找到i结点的前趋地址
if( Ptr!=NULL && Ptr->next!=NULL )
qPtr=Delete_After_LkList(Ptr);
return qPtr;
}
算法的实现主要耗费在查找操作Get_LkList上,时间复杂度亦为O(n)。
最后,作为一篇一边记笔记一边记录的作业,要在另一篇写剩下的了,不然不好翻呀!
单链表的讨论作为结尾
链表中的对象也是按线性顺序排列的,但与数组不同,数组的线性顺序是由数组的下标决定的,而链表中的顺序则是由个对象中的指针决定的。相比于线性表顺序结构,其操作复杂。
- 动态结构,不需预先分配空间:使用链表结构可以克服顺序表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
- 指针占用额外存储空间:链表由于增加了结点的指针域额外占用空间。
- 不能随机存取,查找速度慢:链表失去了数组的随机读取的优点,且单向链表只能顺着一个方向查找
- 链表上实现的插入和删除运算,不需要移动结点,仅需修改指针。
如图所示: