hadoop环境搭建参考: https://blog.csdn.net/qq_26437925/article/details/78945077
* Java
compile group: 'org.apache.hadoop', name: 'hadoop-client', version: '2.7.4'
compile group: 'org.apache.hadoop', name: 'hadoop-yarn', version: '2.7.4'
import java.io.IOException;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);//这个1表示每个单词出现一次,map的输出value就是1.
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
context.write(new Text(line), one);
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
System.out.println("===start");
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
Job job = Job.getInstance(conf, WordCount.class.getSimpleName());
job.setJarByClass(WordCount.class);//我们在hadoop集群上运行作业的时候,要把代码打包成一个jar文件,然后把这个文件
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.226.128:9000/bigdata/nums/nums_small.txt"));
URI uri = URI.create("hdfs://192.168.226.128:9000/");
FileSystem fileSystem = FileSystem.get(uri,conf);
Path path = new Path("/bigdata/output");
if(fileSystem.exists(path)) {
fileSystem.delete(path);
System.out.println("the path exited,but alread has been deleted");
}
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.226.128:9000/bigdata/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
System.out.println("===end");
}
}* 输入文件

* 结果


----
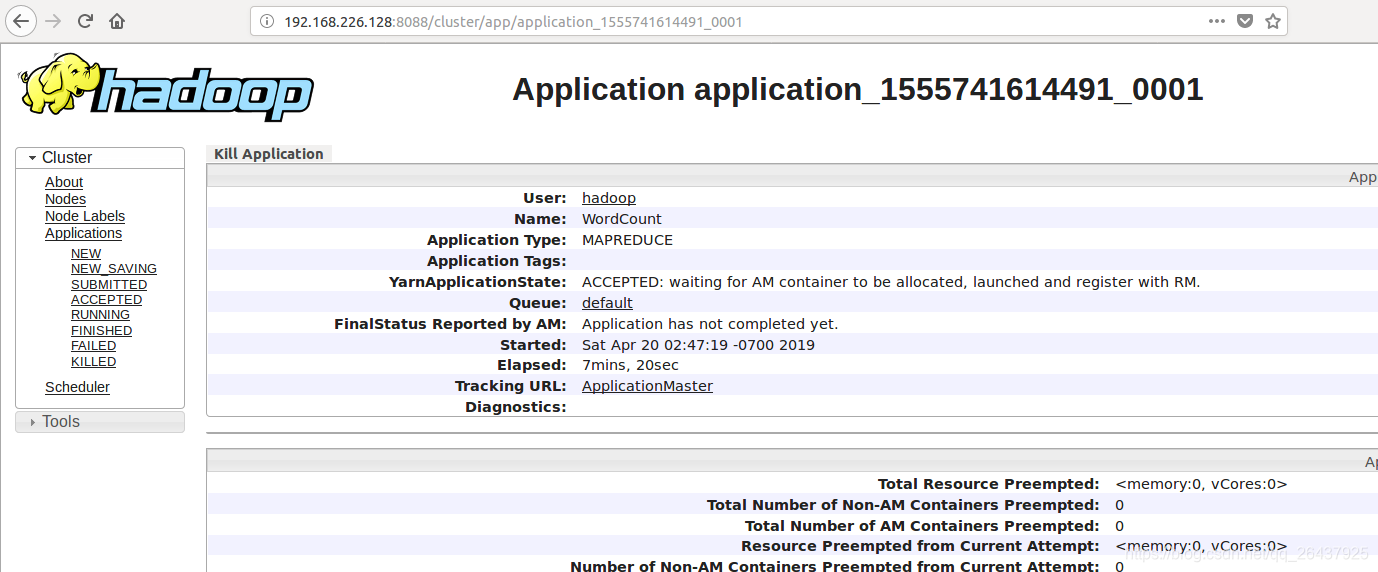
ACCEPTED: waiting for AM container to be allocated, launched and register wiith RM
http://192.168.226.128:8088/logs/yarn-hadoop-resourcemanager-vm2.log

import java.io.IOException;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);//这个1表示每个单词出现一次,map的输出value就是1.
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
context.write(new Text(line), one);
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
System.out.println("===start");
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
conf.set("fs.default.name", "hdfs://192.168.226.128:9000");
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.framework.name", "yarn");//集群的方式运行,非本地运行。
Job job = Job.getInstance(conf, WordCount.class.getSimpleName());
job.setJarByClass(WordCount.class);//我们在hadoop集群上运行作业的时候,要把代码打包成一个jar文件,然后把这个文件
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path inPath = new Path("hdfs://192.168.226.128:9000/bigdata/nums/nums_small.txt");
// Path inPath = new Path("/nums/nums_small.txt");
FileInputFormat.addInputPath(job, inPath);
URI uri = URI.create("hdfs://192.168.226.128:9000/");
FileSystem fileSystem = FileSystem.get(uri,conf);
Path path = new Path("/bigdata/output");
if(fileSystem.exists(path)) {
fileSystem.delete(path);
System.out.println("the path exited,but alread has been deleted");
}
// FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.226.128:9000/bigdata/output"));
FileOutputFormat.setOutputPath(job, path);
// System.exit(job.waitForCompletion(true) ? 0 : 1);
job.submit();
System.out.println("===end");
}
}参考:https://blog.csdn.net/xiao_jun_0820/article/details/43308743
http://www.hainiubl.com/topics/309
https://yy9991818.iteye.com/blog/2374110
https://www.cnblogs.com/hujingnb/p/10246187.html

