项目Github地址
我们将首先实现一个爬虫基类,由于各个会议的爬取都是从dblp出发,所以有很多类似的地方,我们可以把这些重复的操作/函数都封装在基类里,每个会议又有其独特之处,为每个会议单独写一个类,定义其特有的函数,这些子类都继承自基类。
基类主要包含了四个函数:
- main()
基于给定的搜索条件,包括年份、关键词、会议,进行遍历搜索:
def main(self):
for year in self.opt.Years:
print("{0}:".format(year))
for keyword in self.opt.Keywords:
keyword1 = self.opt.Meeting+' '+keyword
#url = 'https://dblp.uni-trier.de/search?q={0}%20venue%3A{1}%3A%20year%3A{2}%3A'.format(keyword,self.opt.Meeting,year)
url = 'https://dblp.uni-trier.de/search?q={0}%20year%3A{1}%3A'.format(keyword1,year)
page = self.get_page(url)
urls = self.get_url(page)
if urls != None:
print("所有论文页面url提取成功!共{0}篇。".format(len(urls)))
for url1 in urls:
print("论文页面:" + str(url1))
self.get_content(url1, year)
else:
print("年份:{0},关键词:{1} 没有相关论文!".format(year,keyword))
1)对于每个年份和关键词,构造dblp查询url。可以单独把会议信息作为一个查询条件放在url的venue字段中,但是这样做有个缺点,就是有些会议可能和其他会议联合召开,会有不同的venue名称,此时需要爬取多次,每次填入一个venue名称,如NAACL就有多个venue名称:

还有一个更好的做法是把会议信息和关键词放在一起,当作关键词进行检索,此时他会把相关会议的所有venue,包括正文、workshop等都包括在内一起全部爬取下来。
构造好dblp查询url后(会议、关键词、年份),将会得到以下页面:
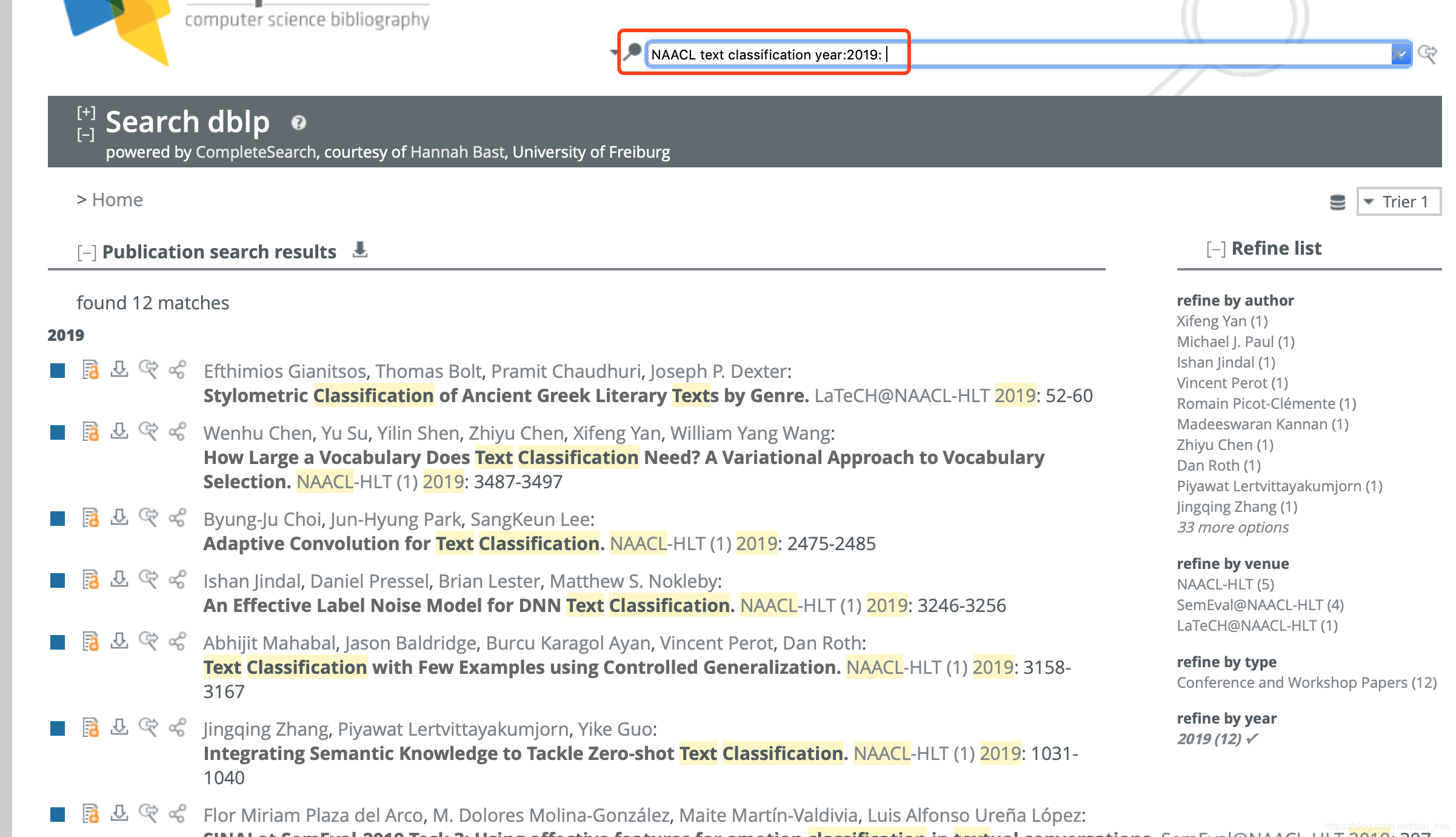
注意:关键词顺序大小写都不敏感。
- get_page()
使用get_page()函数对dblp查询url得到的页面进行爬取,如上面的页面。
get_page(url,flag=True,threshold=20)该函数基于给定的url对相关的页面内容进行爬取;flag参数默认为True,用于返回页面对应的文本内容,当flag为false时,返回页面对应的2进制内容(当爬取pdf时会用到);threshold参数是一个阈值,当请求出现异常时,就进行重试,threshold是重试次数的上限,默认为20.
def get_page(self,url, flag=True, threshold=20):
count = 0
while True:
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
if flag:
return response.text
else:
return response.content
return None
except RequestException:
print('fail')
count = count + 1
if count >= threshold:
break
continue- get_urls
对上述爬取的页面进行解析,得到每篇论文对应的页面url。
def get_url(self,page):
soup = BeautifulSoup(page, 'lxml')
urls = []
for i,a in enumerate(soup.select('.publ-list .inproceedings .publ ul .drop-down .head a')):
if i%4==0:
urls.append(a['href'])
if urls!=[]:
p_str = soup.select('#completesearch-info-matches')[0].get_text()
if 'one' not in p_str:
pattern = re.compile('\d+',re.S)
num = pattern.findall(p_str)[0]
else:
num = 1
assert int(num)==len(urls)
return urls
return None
每篇论文有四个标记,其中第一个对应的页面可以找到论文的pdf下载链接。使用BeautifulSoup库对爬取的页面进行解析,得到每篇论文页面的url,存储在urls列表中。同时解析出上图红框中的数字,和得到的urls列表的大小比较,应该是一样的。
接下来再对每篇论文的页面进行爬取,解析出每篇论文pdf的下载链接(这一部分,每个会议都有独特之处,在之后的子类构造中会详细介绍),再对每篇论文的pdf下载链接进行爬取,得到论文内容,并保存在本地指定位置。
- saveFile
def saveFile(self,pdf_url, title, year):
'''
if '/' in self.opt.Meeting:
meeting = self.opt.Meeting.replace('/','_')
else:
meeting = self.opt.Meeting
'''
name = self.opt.path+str(self.opt.Field) + '/' + str(self.opt.Meeting) + '/' + str(year)
if not os.path.exists(name):
os.makedirs(name)
#filepath = name + '/{}.pdf'.format(title)
filepath = name + '/{}.pdf'.format(md5(title.encode()).hexdigest())
#filepath = name + '/{}.pdf'.format(pdf_url.split('/')[-1])
if not os.path.exists(filepath):
content = self.get_page(pdf_url, False)
if content != None:
with open(filepath, 'wb') as f:
f.write(content)
else:
print("已经下载过了!")保存路径为指定路径+/领域名称/会议名称/年份/相关论文的pdf文件。
论文pdf文件的命名可以直接采用论文的标题,也可以采用论文标题对应的md5编码或者论文pdf链接中的数字。
