感知机(Perceptron)
一种简单的感知机结构如下图所示,由三个输入节点和一个输出节点构成,三个输入节点x1,x2,x3分别代表一个输入样本x的三个特征值;w1,w2,w3分别代表三个特征值对应的权重;b为偏置项;输出节点中的z和o分别代表线性变换后的输出值和非线性变换后的输出值。
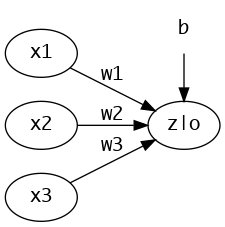
{z=x1∗w1+x2∗w3+x3∗w3+bo=f(z)(1)
其中映射函数
f为激活函数,下面列几个常见的激活函数:
| 函数名 |
函数表达式 |
导数 |
|
sigmoid |
f(z)=1+e−z1 |
f(z)[1−f(z)] |
|
tanh |
f(z)=ez+e−zez−e−z |
1−f(z)2 |
|
softmax |
f(z)=∑j=0nezjezi |
经常用其构成的
损失函数的导数:
f(zi)−t(i) |
神经网络(Neural Network)
神经网络基本结构
神经网络与感知机类似,但是它的节点更加复杂,下图是一个含有1层隐藏层的神经网络,也是一种最简单的神经网络,我们可以看到这个神经网络的输入层有2个节点,隐藏层有3个节点,输出层有1个节点。我们可以认为神经网络由多个感知机构成。我们以下图所示结构为例,实现一个可以进行数据分类的神经网络。

假设我们有N个样本,对于每一个样本来说,都有两个特征值,对于这样的每一个样本
x(x1,x2)都满足公式2,公式中带小括号的上标代表神经网络的层数,
wij为相邻两层两个节点之间的权重系数,其中的
i代表前一层的第
i个节点,
j代表后一层的第
j个节点。
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧z1(1)=x1∗w11(1)+x2∗w21(1)+b1(1), h1=f(z1(1))z2(1)=x1∗w22(1)+x2∗w22(1)+b2(1), h2=f(z2(1))z3(1)=x1∗w13(1)+x2∗w23(1)+b3(1), h3=f(z31)z(2)=h1∗w1(2)+h2∗w2(2)+h3∗w3(2)+b(2), o=f(z(2))(2)
我们可以用矩阵形式改写公式2:
⎩⎪⎪⎪⎨⎪⎪⎪⎧Z1=X⋅W1+B1H=f(Z1)Z2=H⋅W2+B2Y^=f(Z2)(3)
公式2中
X[N×2]为输入矩阵,
B1 [N×3]为隐藏层偏置矩阵,
W1 [2×3]为输入层到隐藏层的权重矩阵,
W2 [3×1]为隐藏层到输出层的权重矩阵,
B2 [N×1]为输出层偏置矩阵,
Y^[N×1]为输出矩阵(结果预测矩阵),
Z1,
H矩阵维度为
N×3,
Z2矩阵维度为
N×1。
神经网络损失函数
我们这里用改写的方差公式作为神经网络预测分类结果的损失函数,正确的分类结果矩阵记为
Y[N×1]:
func=2N1∗i=1∑N(Y^−Y)2(4)
根据梯度下降法,我们需要求损失函数
func的梯度,梯度下降法的实现可以看这里。损失函数可以表示为
func=f(X,W1,W2,B1,B2)的形式(类似地,
Z1=f(X,W1,B1),
Z2=f(Z1,W2,B2)),由于
W1,W2,B1,B2是我们需要训练的参数,所以我们需要分别求
func对
W1,W2,B1,B2的梯度(这里涉及到矩阵的求导,见附录)。
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂W2∂func=∂Z2∂func∗∂W2∂Z2=(N1∗∑i=1N(Y^−Y))∗(Z1T⋅f′(Z1,W2,B2))∂B2∂func=∂Z2∂func∗∂B2∂Z2=(N1∗∑i=1N(Y^−Y))∗f′(Z1,W2,B2)∂W1∂func=∂Z2∂func∗∂Z1∂Z2∗∂W1∂Z1=(N1∗∑i=1N(Y^−Y))∗(f′(Z1,W2,B2)⋅W2T)∗(XT⋅f′(X,W1,B1))∂B1∂func=∂Z2∂func∗∂Z1∂Z2∗∂B1∂Z1=(N1∗∑i=1N(Y^−Y))∗(f′(Z1,W2,B2)⋅W2T)∗f′(X,W1,B1)(5)
根据梯度下降法,我们在求完梯度以后,需要更新我们的参数值,这里以
W1为例:
W1=W1−η∗∂W1∂func(6)
由公式6可以看出,
W1的梯度矩阵应该与
W1维度相同,即
∂Z2∂func[1×1]∗∂Z1∂Z2[N×1]⋅[3×1]∗∂W1∂Z1[2×N]⋅[N×3]与
W1 [2×3]维度相同,因此
N应该为1。所以我们在编程时应该一个样本一个样本的训练,而不是
N个样本一起训练。当
N=1时,公式5可以简化为:
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂W2∂func=∂Z2∂func∗∂W2∂Z2=(Y^−Y)∗(Z1T∗f′(Z1,W2,B2))∂B2∂func=∂Z2∂func∗∂B2∂Z2=(Y^−Y)∗f′(Z1,W2,B2)∂W1∂func=∂Z2∂func∗∂Z1∂Z2∗∂W1∂Z1=(Y^−Y)∗(f′(Z1,W2,B2)∗W2T)∗(XT⋅f′(X,W1,B1))∂B1∂func=∂Z2∂func∗∂Z1∂Z2∗∂B1∂Z1=(Y^−Y)∗(f′(Z1,W2,B2)∗W2T)∗f′(X,W1,B1)(7)
按照上述思路进行编程,这里隐藏层激活函数选择sigmoid函数,输出层激活函数选择tanh函数,得到分类结果的错误率为0.01~0.06,当隐藏层和输出层激活函数都选择tanh函数时,错误率更低。下图为错误率为0.025时的分类结果图。我们可以看到图中有5个数据点分类错误。

局限性
由于我们是一个样本一个样本训练的,所以我们得到的参数也是和这些样本一一对应的,因此这个模型无法画出决策边界,也无法预测新的数据,预测新的数据好像是应该对训练好的参数进行插值,但是我看别人没有那么做的,可能这样不大好。
附录
神经网络代码
__Author__ = "stubborn vegeta"
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from matplotlib.colors import ListedColormap
class neuralNetwork(object):
def __init__(self, X, Y, inputLayer, outputLayer, hiddenLayer=3,learningRate=0.01, epochs=10):
"""
learningRate:学习率
epochs:训练次数
inputLayer:输入层节点数
hiddenLayer:隐藏层节点数
outputLayer:输出层节点数
"""
self.learningRate = learningRate
self.epochs = epochs
self.inputLayer = inputLayer
self.hiddenLayer = hiddenLayer
self.outputLayer = outputLayer
self.X = X
self.Y = Y
self.lenX,_ = np.shape(self.X)
s=np.random.seed(0)
self.W1 = np.array(np.random.random([self.inputLayer, self.hiddenLayer])*0.5)
self.B1 = np.array(np.random.random([self.lenX,self.hiddenLayer])*0.5)
self.W2 = np.array(np.random.random([self.hiddenLayer, self.outputLayer])*0.5)
self.B2 = np.array(np.random.random([self.lenX,self.outputLayer])*0.5)
def activationFunction(self, funcName:str, X):
"""
激活函数
sigmoid: 1/1+e^(-z)
tanh: [e^z-e^(-z)]/[e^z+e^(-z)]
softmax: e^zi/sum(e^j)
"""
switch = {
"sigmoid": 1/(1+np.exp(-X)),
"tanh": np.tanh(X),
}
return switch[funcName]
def activationFunctionGrad(self, funcName:str, X):
"""
激活函数的导数
"""
switch = {
"sigmoid": np.exp(-X)/(1+np.exp(-X))**2,
"tanh": 1-(np.tanh(X)**2),
}
return switch[funcName]
def train(self, funcNameH:str, funcNameO:str):
"""
funcNameH: 隐藏层激活函数
funcNameO: 输出层激活函数
"""
for i in range(0,self.epochs):
j = np.random.randint(self.lenX)
x = np.array([self.X[j]])
y = np.array([self.Y[j]])
b1 = np.array([self.B1[j]])
b2 = np.array([self.B2[j]])
zHidden = x.dot(self.W1)+b1
z1 = self.activationFunction(funcNameH, zHidden)
zOutput = z1.dot(self.W2)+b2
z2 = self.activationFunction(funcNameO, zOutput)
dW2 = (z2-y)*(z1.T*self.activationFunctionGrad(funcNameO,zOutput))
db2 = (z2-y)*self.activationFunctionGrad(funcNameO,zOutput)
dW1 = (z2-y)*(self.activationFunctionGrad(funcNameO,zOutput)*self.W2.T)*(x.T.dot(self.activationFunctionGrad(funcNameH,zHidden)))
db1 = (z2-y)*(self.activationFunctionGrad(funcNameO,zOutput)*self.W2.T)*self.activationFunctionGrad(funcNameH,zHidden)
self.W2 -= self.learningRate*dW2
self.B2[j] -= self.learningRate*db2[0]
self.W1 -= self.learningRate*dW1
self.B1[j] -= self.learningRate*db1[0]
return 0
def predict(self, xNewData, funcNameH:str, funcNameO:str):
X = xNewData
N,_ = np.shape(X)
yPredict = []
for j in range(0,N):
x = np.array([X[j]])
b1 = np.array([self.B1[j]])
b2 = np.array([self.B2[j]])
zHidden = x.dot(self.W1)+b1
z1 = self.activationFunction(funcNameH, zHidden)
zOutput = z1.dot(self.W2)+b2
z2 = self.activationFunction(funcNameO, zOutput)
z2 = 1 if z2>0.5 else 0
yPredict.append(z2)
return yPredict,N
if __name__ == "__main__":
X,Y = datasets.make_moons(200, noise=0.15)
neural_network = neuralNetwork (X=X, Y=Y, learningRate=0.2, epochs=1000, inputLayer=2, hiddenLayer=3, outputLayer=1)
funcNameH = "sigmoid"
funcNameO = "tanh"
neural_network.train(funcNameH=funcNameH,funcNameO=funcNameO)
yPredict,N = neural_network.predict(xNewData=X,funcNameH=funcNameH,funcNameO=funcNameO)
print("错误率:", sum((Y-yPredict)**2)/N)
colormap = ListedColormap(['royalblue','forestgreen'])
plt.subplot(1,2,1)
plt.scatter(X[:,0],X[:,1],s=40, c=Y, cmap=colormap)
plt.xlabel("x")
plt.ylabel("y")
plt.title("Standard data")
plt.subplot(1,2,2)
plt.scatter(X[:,0],X[:,1],s=40, c=yPredict, cmap=colormap)
plt.xlabel("x")
plt.ylabel("y")
plt.title("Predicted data")
plt.show()
感知机结构图代码
digraph network{
edge[fontname="Monaco"]
node[fontname="Monaco"]
rankdir=LR
b[shape=plaintext]
x1->"z|o"[label=w1]
x2->"z|o"[label=w2]
x3->"z|o"[label=w3]
b->"z|o"
{rank=same;b;"z|o"}
}
神经网络结构图代码
digraph network{
edge[fontname="Monaco"]
node[fontname="Monaco",shape=circle]
rankdir=LR
subgraph cluster_1{
color = white
fontname="Monaco"
x1,x2;
label = "Input Layer";
}
subgraph cluster_2{
color = white
fontname="Monaco"
h3,h1,h2;
label = "Hidden Layer";
}
subgraph cluster_3{
// rank=same
color = white
fontname="Monaco"
o;
label = "Output Layer";
}
x1->h1
x1->h2
x1->h3
x2->h1
x2->h2
x2->h3
rank=same;h1;h2;h3
h1->o
h2->o
h3->o
}
矩阵求导公式
|
Y=A⋅X ⟹ dXdY=AT |
Y=X⋅A ⟹ dXdY=AT |
|
Y=XT⋅A ⟹ dXdY=A |
Y=A⋅X ⟹ dXTdY=A |
|
dXdXT=I |
dXTdX=I |
