文章大纲
0.简介
想象如下一个场景,一个合作伙伴想让你分析一下自己的业务数据,比较慷慨的给出了数据全库。但是对方的IT 人员没有精力去协助我们逐个了解数据怎么办呢,这时候就需要进行一些针对数据库的探索性、描述性的数据分析 帮我们更好的了解对方的数据内涵了。
下面就以Oracle 为例,使用python 进行全库数据描述性及探索性逆向分析。
1. cx_Oracle 简介与数据类型
说到python 链接Oracle ,就不得不提到cx_Oracle ,cx_Oracle is a module that enables access to Oracle Database and conforms to the Python database API specification.
cx_Oracle 目前是oracle 官方 出品的python Oracle链接管理包
cx_Oracle 源代码:https://github.com/oracle/python-cx_Oracle
文档:https://cx-oracle.readthedocs.io/en/latest/index.html
Oracle - cx_Oracle - Python 映射为:
| Oracle | cx_Oracle | Python |
| VARCHAR2 NVARCHAR2 LONG |
cx_Oracle.STRING |
str |
| CHAR |
cx_Oracle.FIXED_CHAR |
|
| NUMBER |
cx_Oracle.NUMBER |
int |
| FLOAT |
float |
|
| DATE |
cx_Oracle.DATETIME |
datetime.datetime |
| TIMESTAMP |
cx_Oracle.TIMESTAMP |
|
| CLOB |
cx_Oracle.CLOB |
cx_Oracle.LOB |
| BLOB |
cx_Oracle.BLOB |
2.Oracle 12c 新特性容器数据库
一般来说对于Oracle 高版本的数据库是向下兼容的,所以我们目前使用Oracle 12c 进行本次说明。
Oracle 12C引入了CDB与PDB的新特性,在ORACLE 12C数据库引入的多租用户环境(Multitenant Environment)中,允许一个数据库容器(CDB)承载多个可插拔数据库(PDB)。CDB全称为Container Database,中文翻译为数据库容器,PDB全称为Pluggable Database,即可插拔数据库。在ORACLE 12C之前,实例与数据库是一对一或多对一关系(RAC):即一个实例只能与一个数据库相关联,数据库可以被多个实例所加载。而实例与数据库不可能是一对多的关系。当进入ORACLE 12C后,实例与数据库可以是一对多的关系。下面是官方文档关于CDB与PDB的关系图。
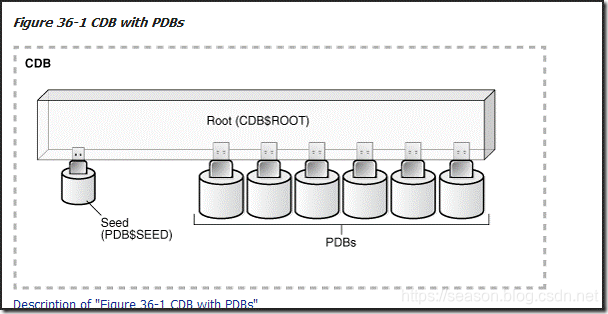
简介详见:
https://www.cnblogs.com/kerrycode/p/3386917.html
及官方文档:
https://docs.oracle.com/en/database/oracle/oracle-database/12.2/index.html
oracle 执行 SQL :
https://docs.oracle.com/en/database/oracle/oracle-database/12.2/cncpt/sql.html#GUID-DA48618A-A6BB-421A-A10A-02859D8ED9AD
3.Oracle 12c 新建表空间、用户、表
在windows 下,我们使用PL/sql 以及sqlplus 进行Oracle 的管理工作,sqlplus 是安装好Oracle 就自带了。
3.0 设置oracle sid 数据库实例名
在cmd 命令行窗口使用sqlplus 之前需要进行数据库实例名 的指定。
set oracle_sid=orcl
3.1 以管理员账户登录
sqlplus sys/sys as sysdba;
3.2 创建表空间
创建用户之前需要创建表空间。
# -- 2.1 创建临时空间
create temporary tablespace test
tempfile 'E:\table\test.dbf'
size 5m
autoextend on
next 10m
extent management local;
# -- 2.2 创建数据表空间
create tablespace test_data
logging
datafile 'E:\table\test_data.dbf'
size 10m
autoextend on
next 10m
maxsize unlimited
extent management local;
3.3 创建用户并指定表空间
有了表空间,我们可以在创建用户的时候给用户指定表空间。
# -- 3.创建用户并指定表空间
-- 刚开始用户名为 ,提示错误ORA-65096:公用用户名或角色名无效,网上查资料,说是取名前缀必须为c##,
--所以用户名也变成了c##test
--首次创建用户时提示test_data表空间不存,重启了服务就创建成功
create user c##test identified by test
default tablespace test_data
temporary tablespace test;
3.4 用户授权
根据需要设置权限
GRANT CREATE ANY VIEW,DROP ANY VIEW,CONNECT,RESOURCE,CREATE SESSION,DBA TO c##test;
3.5 创建样例表格
为了我们后面的分析方便,我们自己创建两个样例表格进行举例,其实真实的情况一般是 参照第6小节数据导入导出,进行原始数据的,导入导出。
注意创建表的时候添加了comment ,这样方便我们DBA 或者逆向探索时候能够理解表格的含义。一般的真实情况是,数据库建表过程中,良好习惯的DBA 会按照一定的命名规范建表,命名字段及编写注释。 这就给我们逆向理解合作伙伴的业务提供了便利条件。
--建立表 DEPT和删除表;
DROP TABLE DEPT cascade constraints;
CREATE TABLE DEPT
(DEPTNO NUMBER(2) CONSTRAINT PK_DEPT PRIMARY KEY,
DNAME VARCHAR2(14) ,
LOC VARCHAR2(13) ) ;
-- 增加表注释
comment on table C##TEST.DEPT
is '部门表';
comment on column C##TEST.DEPT.deptno
is '部门编号';
comment on column C##TEST.DEPT.dname
is '部门名称';
comment on column C##TEST.DEPT.loc
is '部门位置';
--建立表 EMP和删除表;
DROP TABLE EMP;
CREATE TABLE EMP
(EMPNO NUMBER(4) CONSTRAINT PK_EMP PRIMARY KEY,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) CONSTRAINT FK_DEPTNO REFERENCES DEPT);
---插入dept语句块;
INSERT INTO DEPT VALUES
(10,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES (20,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES
(30,'SALES','CHICAGO');
INSERT INTO DEPT VALUES
(40,'OPERATIONS','BOSTON');
---插入EMP语句块;
INSERT INTO EMP VALUES
(7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO EMP VALUES
(7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30);
INSERT INTO EMP VALUES
(7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30);
INSERT INTO EMP VALUES
(7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20);
INSERT INTO EMP VALUES
(7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30);
INSERT INTO EMP VALUES
(7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,NULL,30);
INSERT INTO EMP VALUES
(7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,NULL,10);
INSERT INTO EMP VALUES
(7788,'SCOTT','ANALYST',7566,to_date('12-06-1987','dd-mm-yyyy')-85,3000,NULL,20);
INSERT INTO EMP VALUES
(7839,'KING','PRESIDENT',NULL,to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10);
INSERT INTO EMP VALUES
(7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30);
INSERT INTO EMP VALUES
(7876,'ADAMS','CLERK',7788,to_date('13-06-1987','dd-mm-yyyy')-51,1100,NULL,20);
INSERT INTO EMP VALUES
(7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,NULL,30);
INSERT INTO EMP VALUES
(7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,NULL,20);
INSERT INTO EMP VALUES
(7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,NULL,10);
-- 提交插入
COMMIT;
--查询部分;
select * from emp;
select * from dept;
3.6 数据导入导出
imp/exp ,impdp/expdp需要成对使用
以下分别给出两个导入样例
imp c##test/test@orcl file=D:20190506.DMP full=y log=01.log
impdp c##test/test@orcl directory=dir logfile=p_street_area.log job_name=my_job
4.python 环境准备
参考该文章:1.2.4 小节conda基本环境配置
https://blog.csdn.net/wangyaninglm/article/details/89440922
使用如下 requirements.txt 初始化环境
conda create --name DATABASE --file requirements.txt
# This file may be used to create an environment using:
# $ conda create --name <env> --file <this file>
# platform: win-64
backcall=0.1.0=py37_0
blas=1.0=mkl
ca-certificates=2019.1.23=0
certifi=2019.3.9=py37_0
colorama=0.4.1=py37_0
cx_oracle=7.0.0=py37h62dcd97_0
decorator=4.4.0=py37_1
icc_rt=2019.0.0=h0cc432a_1
intel-openmp=2019.3=203
ipykernel=5.1.0=py37h39e3cac_0
ipython=7.5.0=py37h39e3cac_0
ipython_genutils=0.2.0=py37_0
jedi=0.13.3=py37_0
jupyter_client=5.2.4=py37_0
jupyter_core=4.4.0=py37_0
libsodium=1.0.16=h9d3ae62_0
mkl=2019.3=203
mkl_fft=1.0.12=py37h14836fe_0
mkl_random=1.0.2=py37h343c172_0
numpy=1.16.4=py37h19fb1c0_0
numpy-base=1.16.4=py37hc3f5095_0
openssl=1.1.1c=he774522_1
pandas=0.24.2=py37ha925a31_0
parso=0.4.0=py_0
pickleshare=0.7.5=py37_0
pip=19.1.1=py37_0
prompt_toolkit=2.0.9=py37_0
pygments=2.4.0=py_0
python=3.7.3=h8c8aaf0_1
python-dateutil=2.8.0=py37_0
pytz=2019.1=py_0
pyzmq=18.0.0=py37ha925a31_0
setuptools=41.0.1=py37_0
six=1.12.0=py37_0
sqlite=3.28.0=he774522_0
tornado=6.0.2=py37he774522_0
traitlets=4.3.2=py37_0
vc=14.1=h0510ff6_4
vs2015_runtime=14.15.26706=h3a45250_4
wcwidth=0.1.7=py37_0
wheel=0.33.4=py37_0
wincertstore=0.2=py37_0
zeromq=4.3.1=h33f27b4_3
# 为了能让jupyter 使用这个 kernel
#直接 切换到 需要显示 的 隔离环境
conda install ipykernel
#or
conda install -n python_env ipykernel
5.Oracle SQL 全库全表字段分析
在Oracle 中进行 全库全表字段分析需要用的一个非常重要的表:USER_TABLES
什么是USER_TABLES ?
USER_TABLES describes the relational tables owned by the current user. Its columns (except for OWNER) are the same as those in ALL_TABLES.
USER_TABLES 和ALL_TABLES 字段一样,我们来看看文档里面ALL_TABLES 有哪些有用的字段:
Related Views
-
DBA_TABLES describes all relational tables in the database.
-
USER_TABLES describes the relational tables owned by the current user. This view does not display the OWNER column.
Note:Columns marked with an asterisk (*) are populated only if you collect statistics on the table with the DBMS_STATS package.
对我们有用的字段拿几个先看看:
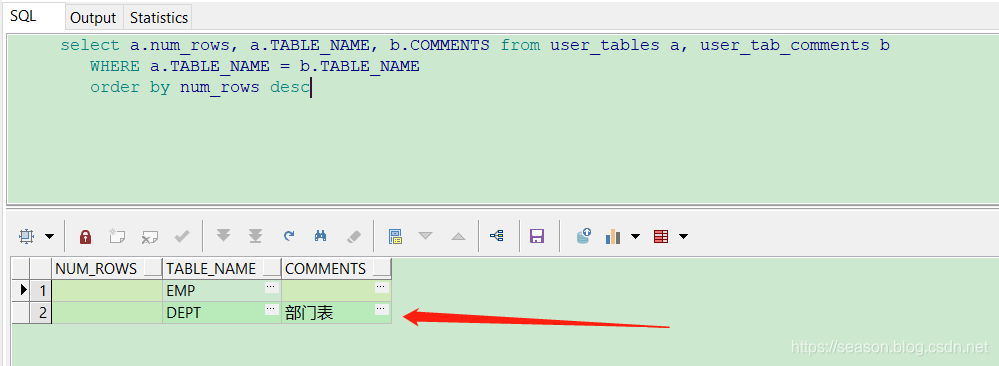
SELECT a.num_rows, a.table_name, b.comments
FROM user_tables a, user_tab_comments b
WHERE a.table_name = b.table_name
ORDER BY num_rows DESC
可以看到 写了注释的表,都展现出来注释了。
可以看到刚刚插入完数据,num_rows 没有更新
隔了一天以后, 数据就有了:

如果想要立即更新USER_TABLES 或者参照下面链接
Oracle manually update statistics on all tables
运行,手动更新:
exec DBMS_STATS.GATHER_DATABASE_STATS;
一般来说,USER_TABLES不会自动更新,oracle 会在闲时或者定时更新这张表。所以入数据以后不一定 多久会看到USER_TABLES 的更新。
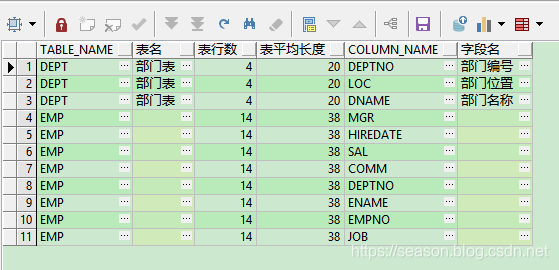
SELECT t_column_comments.table_name,
t_table_comments.comments 表名,
t_table_comments.num_rows 表行数,
t_table_comments.avg_row_len 表平均长度,
t_column_comments.column_name,
t_column_comments.comments 字段名
FROM (SELECT *
FROM all_col_comments
WHERE table_name IN (SELECT table_name FROM user_tables)) t_column_comments,
(SELECT a.num_rows, a.table_name, b.comments, a.avg_row_len
FROM user_tables a, user_tab_comments b
WHERE a.table_name = b.table_name) t_table_comments
WHERE t_table_comments.table_name = t_column_comments.table_name
ORDER BY t_column_comments.table_name
可以看到如下的导出表基本上符合人的观察规范,适合进行Oracle 全库的描述性、探索性数据分析。比如合作伙伴将全库共享,我们如何第一时间通过数据了解合作伙伴的业务情况和设计呢。我想可以通过这样的手段,首先有一个大致的认识,接下来就是进一步看看样例数据的样子了。那么我们用这个导出表作为基础,写点python代码进一步进行数据探索性分析。
6.Oracle python 操作辅助类
通过编写OracleBaseTool, 这个操作辅助类,主要目的是对于以下一些动作进行封装:
- 1.数据库的链接(初始化)
- 2.数据库链接的管理
- 3.数据库的查询管理
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
#-------------------------------------------------------------------------------
'''
@Author : {SEASON}
@License : (C) Copyright 2013-2022, {OLD_IT_WANG}
@Contact : {[email protected]}
@Software: PyCharm
@File : DataBase -- OracleBaseTool
@Time : 2019/5/22 17:10
@Desc :
'''
#-------------------------------------------------------------------------------
import cx_Oracle
class OracleBaseTool():
"""OracleBaseTool"""
def __init__(self,user_name,password,ip,service_name):
self.user_name = user_name
self.password = password
self.ip = ip
self.service_name = service_name
self.connectObj = ""
self.connCnt = 0
self.cursorCnt = 0
def initOracleConnect(self):
oracle_tns = cx_Oracle.makedsn(self.ip, 1521, self.service_name)
if self.connCnt == 0:
self.connectObj = cx_Oracle.connect(self.user_name, self.password, oracle_tns)
self.connCnt += 1
def getConnOracle(self,user_name, password, ip, service_name):
try:
self.connectObj = cx_Oracle.connect(user_name + '/' + password + '@' + ip + '/' + service_name) # 连接数据库
self.connCnt += 1
except Exception:
print(Exception)
def getOracleConnect(self):
self.initOracleConnect()
return self.connectObj
def closeOracleConnect(self, connectObj):
connectObj.close()
self.connCnt -= 1
def getOracleCursor(self):
self.initOracleConnect()
self.cursorCnt += 1
return self.connectObj.cursor()
def closeOracleCursor(self, cursorObj):
cursorObj.close()
self.cursorCnt -= 1
if self.cursorCnt == 0:
print("will close conn")
self.closeOracleConnect(self.connectObj)
def selectFromDbTable(self, sql, argsDict=None):
# 将查询结果由tuple转为list,并返回
queryAnsList = []
selectCursor = self.getOracleCursor()
selectCursor.prepare(sql)
if argsDict==None:
queryAns = selectCursor.execute(sql)
else:
queryAns = selectCursor.execute(None, argsDict)
for ansItem in queryAns:
queryAnsList.append(list(ansItem))
self.closeOracleCursor(selectCursor)
return queryAnsList
def selectFromDbTable_WithTableHead(self, sql, argsDict=None):
# 将查询结果由tuple转为list,并返回,带表头
queryAnsList = []
selectCursor = self.getOracleCursor()
selectCursor.prepare(sql)
if argsDict==None:
queryAns = selectCursor.execute(sql)
else:
queryAns = selectCursor.execute(None, argsDict)
# 获取表的列名
title = [i[0] for i in selectCursor.description]
queryAnsList.append(list(title))
for ansItem in queryAns:
queryAnsList.append(list(ansItem))
self.closeOracleCursor(selectCursor)
return queryAnsList
def selectFromDbTablefor_SampleData(self, sql, argsDict=None,intSampleNumber = 1):
'''获取intSampleNumber 条样例数据,带表头'''
queryAnsList = []
selectCursor = self.getOracleCursor()
selectCursor.prepare(sql)
if argsDict==None:
selectCursor.execute(sql)
queryAns = selectCursor.fetchmany(intSampleNumber)
else:
queryAns = selectCursor.execute(None, argsDict)
queryAns = selectCursor.fetchmany(intSampleNumber)
# 获取表的列名
title = [i[0] for i in selectCursor.description]
queryAnsList.append(list(title))
for ansItem in queryAns:
queryAnsList.append(list(ansItem))
self.closeOracleCursor(selectCursor)
return queryAnsList
7.python 链接Oracle 全库数据采样
本节主要用到了上面的操作类,使用oracle 的user_tables 获取数据的所有表名称,之后按照采样设置进行链接及采样,并根据采样数据计算数据缺失率,以求初步了解数据和业务的紧密关联。最后用pandas 保存为excel 方便查看。
其中采样的功能主要用到了Oracle 中的sample 函数,具体大家可以查看文档:
以下脚本主要有两大功能:
- 各个表中数据列缺失值统计(采样缺失值,如采样10000条)
- 从各个表中获取数据样例
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
#-------------------------------------------------------------------------------
'''
@Author : {SEASON}
@License : (C) Copyright 2013-2022, {OLD_IT_WANG}
@Contact : {[email protected]}
@Software: PyCharm
@File : DataBase -- GetSampleData
@Time : 2019/5/22 15:41
@Desc :
'''
#-------------------------------------------------------------------------------
import pandas as pd
# from __future__ import print_function
import cx_Oracle
import OracleBaseTool
import os
#应对出现 illegal multibyte sequence 问题
os.environ['nls_lang'] = 'AMERICAN_AMERICA.AL32UTF8'
#生成数据库所有表名、表名注释及行数
sql_string_all_tables = '''
SELECT a.num_rows, a.table_name, b.comments
FROM user_tables a, user_tab_comments b
WHERE a.table_name = b.table_name
ORDER BY num_rows DESC
'''
# sql_string2= '''select a.num_rows, a.TABLE_NAME, b.COMMENTS from user_tables a, user_tab_comments b
# WHERE a.TABLE_NAME = b.TABLE_NAME and a.TABLE_NAME = :content
# order by num_rows desc'''
#named_params = {'content': 'MZ_FYMXB'}
# 传参的sql语句写法
# result_list= HIS_oracle_object.selectFromDbTable(sql_string2,named_params)
#生成数据库所有表名、表名注释及行数,字段名,字段注释
sql_string_all_columns = '''
SELECT t_column_comments.table_name,
t_table_comments.comments 表名,
t_table_comments.num_rows 表行数,
t_table_comments.avg_row_len 表平均长度,
t_column_comments.column_name,
t_column_comments.comments 字段名
FROM (SELECT *
FROM all_col_comments
WHERE table_name IN (SELECT table_name FROM user_tables)) t_column_comments,
(SELECT a.num_rows, a.table_name, b.comments, a.avg_row_len
FROM user_tables a, user_tab_comments b
WHERE a.table_name = b.table_name) t_table_comments
WHERE t_table_comments.table_name = t_column_comments.table_name
ORDER BY t_column_comments.table_name
'''
# 链接oracle
test_oracle_obj = OracleBaseTool.OracleBaseTool(
'c##test', 'test', '127.0.0.1', 'orcl')
result_list = test_oracle_obj.selectFromDbTable(sql_string_all_tables)
result_list_schemaDetail = test_oracle_obj.selectFromDbTable_WithTableHead(
sql_string_all_columns)
result_list_schemaDetail_pdf = pd.DataFrame(
result_list_schemaDetail[1:], columns=result_list_schemaDetail[0])
# 设置采样数据组数,即为 从表中读取几条样例数据
sample_number = 10000
result_list_schemaDetail_pdf['缺失值比例'] = None
# 采样5个sample data 作为column name
for i in range(1, 5+1):
result_list_schemaDetail_pdf['sample_data'+str(i)] = None
# 获取5条样例数据,遍历每一张表
for x in result_list:
table_row_number = x[0]
table_name = x[1]
table_comments = x[2]
if table_row_number > sample_number*10:
#大于10000行的表进行采样
#select * from table_name sample(10) where rownum<=5
sql_string_forsampledata = '''select * from ''' + table_name + ''' sample(10) where rownum<=1000'''
else:
#小于10000行的表 随便选
sql_string_forsampledata = '''select * from ''' + table_name
result_list_sampleData = test_oracle_obj.selectFromDbTablefor_SampleData(
sql_string_forsampledata, None, sample_number)
result_list_sampleData_pdf = pd.DataFrame(
result_list_sampleData[1:], columns=result_list_sampleData[0])
# 将 采样的5个样例值写入后面
# 不一定有10000条数据
样例数据条数 = len(result_list_sampleData)-1
列数量 = len(result_list_sampleData[0])
for column_number in range(0, 列数量):
#获取到table_name 及string_column_name 对应的行号
string_column_name = result_list_sampleData[0][column_number]
index_number = result_list_schemaDetail_pdf[
(result_list_schemaDetail_pdf['TABLE_NAME'] == table_name) & (
result_list_schemaDetail_pdf['COLUMN_NAME'] == string_column_name)].index
# 计算该column 的缺失值比例
缺失值比例_dict = dict(result_list_sampleData_pdf.isnull().sum() / 样例数据条数)
result_list_schemaDetail_pdf.loc[index_number,
'缺失值比例'] = 缺失值比例_dict[string_column_name]
if 样例数据条数 > 5:
int_sample = 5
else:
int_sample = 样例数据条数
for x in range(1, int_sample+1):
#对该 column 进行数据采样,并写入pandas 对应位置
str_sample_data_column_name = 'sample_data' + str(x)
sample_data_column_value = result_list_sampleData[x][column_number]
result_list_schemaDetail_pdf.loc[index_number,
str_sample_data_column_name] = sample_data_column_value
最后一步写入excel ,结合excel 的一些筛选统计工作,我们可以让协助的业务部门,架构部门也更好的了解整个合作伙伴的数据
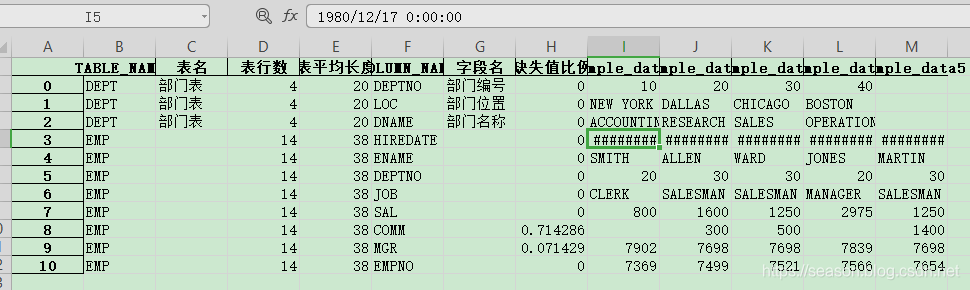
代码如下:使用前记得安装
conda install openpyxl
# pandas to excel 由于是第三方库,写的时候可能报错,如
# "'utf8' codec can't decode byte 0xe9 in position 1: invalid continuation byte"
# 所以一般强制,字符集写成 utf-8
writer = pd.ExcelWriter('output_test.xlsx')
result_list_schemaDetail_pdf.to_excel(writer, 'schema')
writer.save()
8.python missingno 缺失值可视化分析
主要用到missingno 对缺失值进行可视化分析,what is missingno
missingno provides a small toolset of flexible and easy-to-use missing data visualizations and utilities that allows you to get a quick visual summary of the completeness (or lack thereof) of your dataset.
github 链接:https://github.com/ResidentMario/missingno
对于我们的测试库, 以下代码运行在jupyter notebook 中
test_oracle_obj = OracleBaseTool.OracleBaseTool('c##test','test','127.0.0.1','orcl')
sql_string = '''select * from EMP'''
result_list = test_oracle_obj.selectFromDbTable_WithTableHead(sql_string)
%matplotlib inline
import missingno
pdf = pd.DataFrame(result_list[1:], columns = result_list[0] )
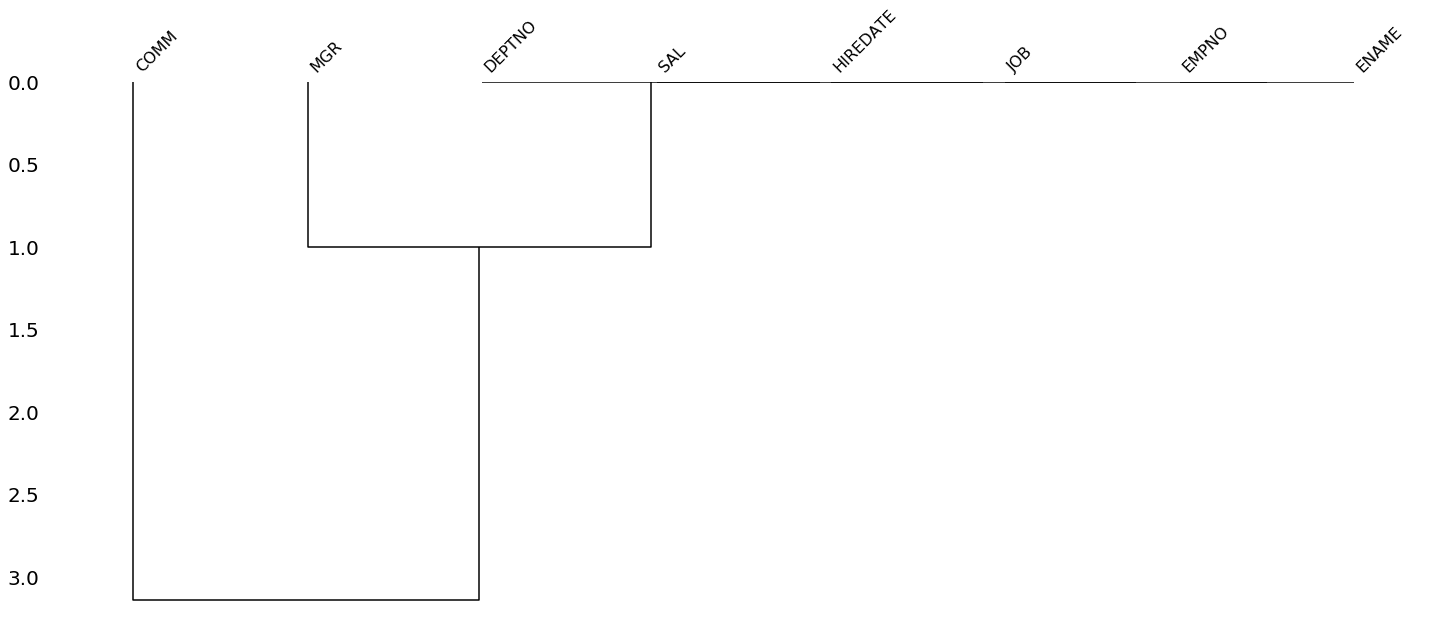
missingno.matrix(pdf, labels=True)
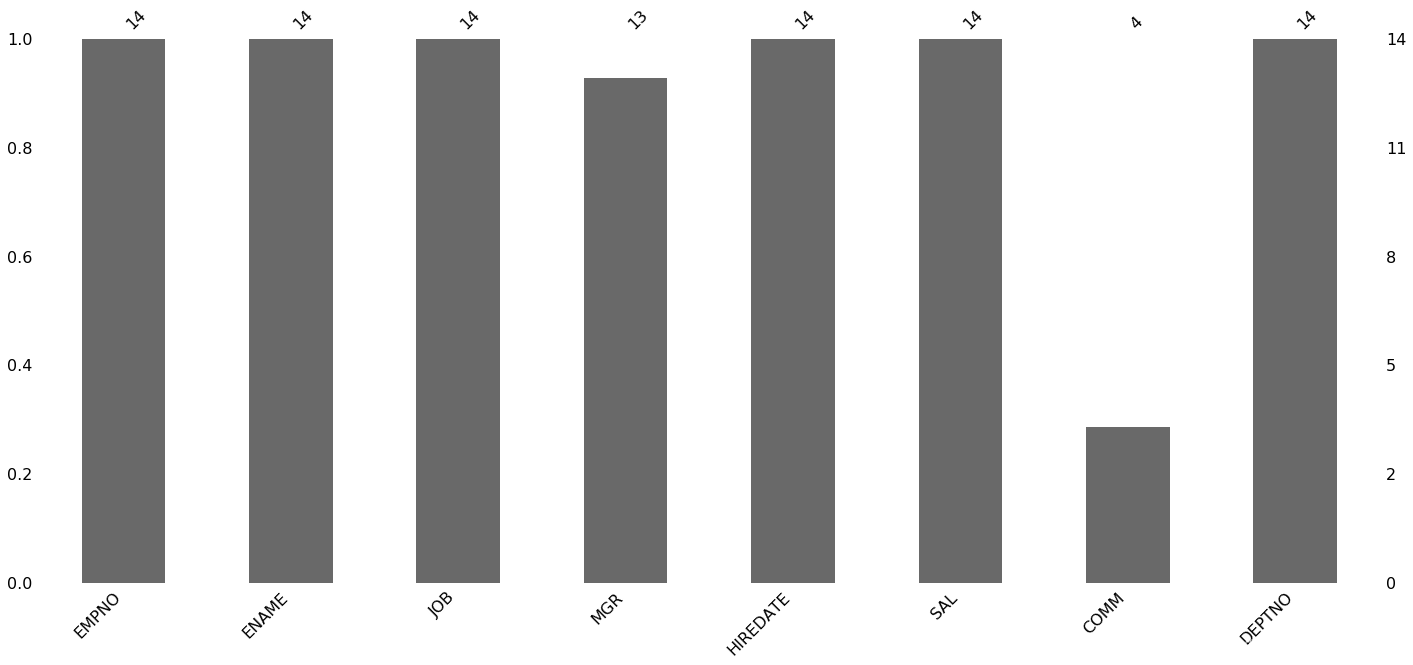
柱状图分析,该图按照数据排序,可视化了数据空缺的空间视图。

条形图, 该图展现缺失值数量对比情况。
missingno.bar(pdf)
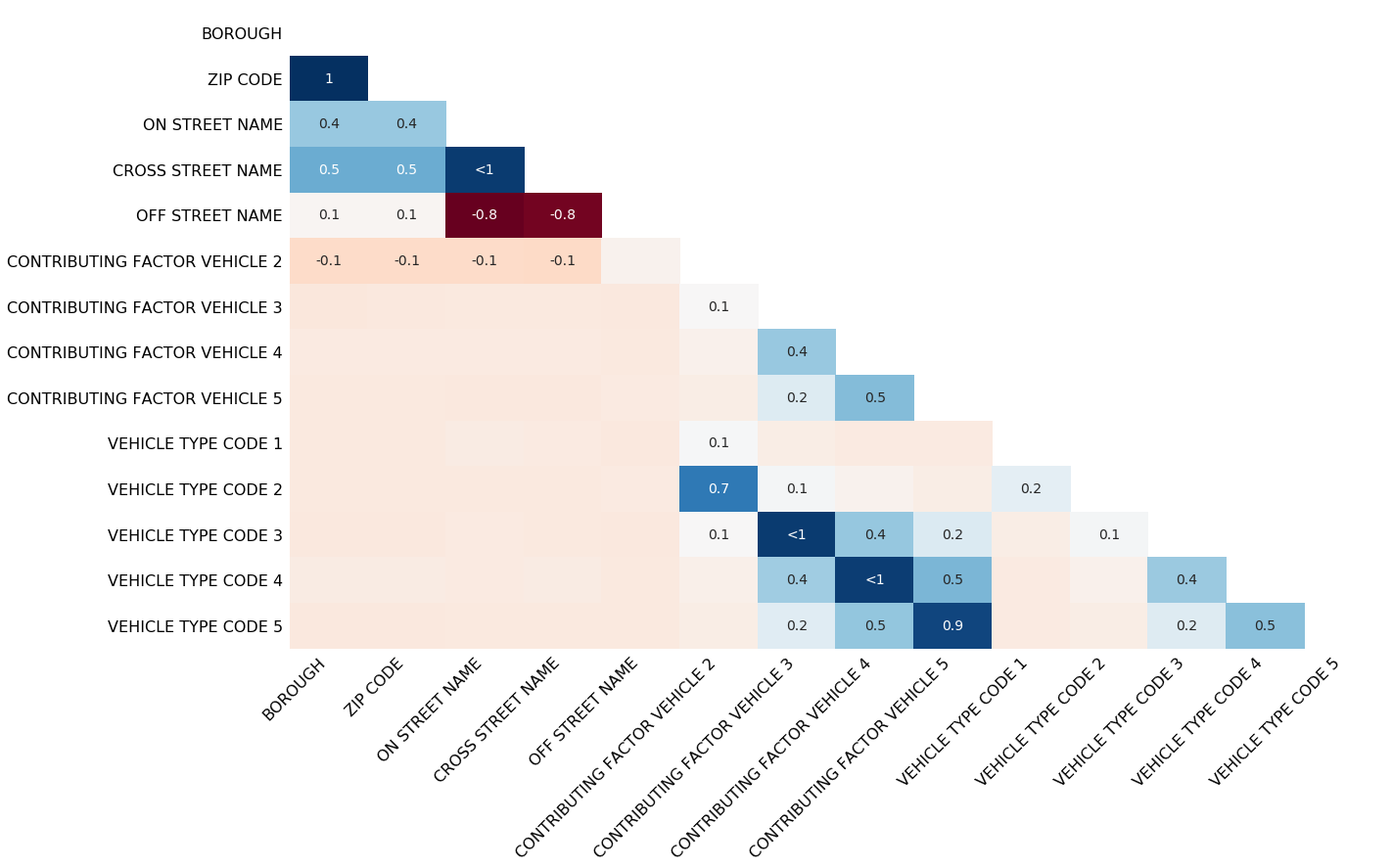
缺失值的相关性分析,既 一个变量的缺失和另一个变量 的关系,由于我们的样例数据较少,所以效果不明显,我们同时看一个官网的例子。
missingno.heatmap(pdf)

缺失值的层次聚类分析,内在逻辑和上面类似,不过是用了不同的算法及展现形式。
missingno.dendrogram(pdf)