分类网络
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
n_data = torch.ones(100, 2)
x0 = torch.normal(3*n_data, 1)
x1 = torch.normal(-3*n_data, 1)
y0 = torch.zeros(100)
y1 = torch.ones(100)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor)
y = torch.cat((y0, y1), 0).type(torch.LongTensor)
x, y = Variable(x).cuda(), Variable(y).cuda()
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden1 = torch.nn.Linear(n_feature, n_hidden)
self.hidden2 = torch.nn.Linear(n_hidden, n_hidden)
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden2(self.hidden1(x)))
x = self.out(x)
return x
net = Net(2, 10, 2)
'''
net = torch.nn.Sequential(
torch.nn.Linear(2, 10),
torch.nn.Linear(10, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 2),
)
'''
net.cuda()
optimizer = torch.optim.SGD(net.parameters(), lr=0.2)
loss_func = torch.nn.CrossEntropyLoss()
plt.ion()
plt.show()
for t in range(300):
print(t)
out = net(x)
loss = loss_func(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0:
plt.cla()
prediction = torch.max(F.softmax(out, dim=0), 1)[1].cuda()
pred_y = prediction.data.cpu().numpy().squeeze()
target_y = y.data.cpu().numpy()
plt.scatter(x.data.cpu().numpy()[:, 0], x.data.cpu().numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlBu')
accuracy = sum(pred_y == target_y) / 200
plt.text(1.5, -4, 'accuracy=%.2f' % accuracy, fontdict={'size':20, 'color':'red'})
plt.pause(0.1)
plt.ioff()
plt.show()

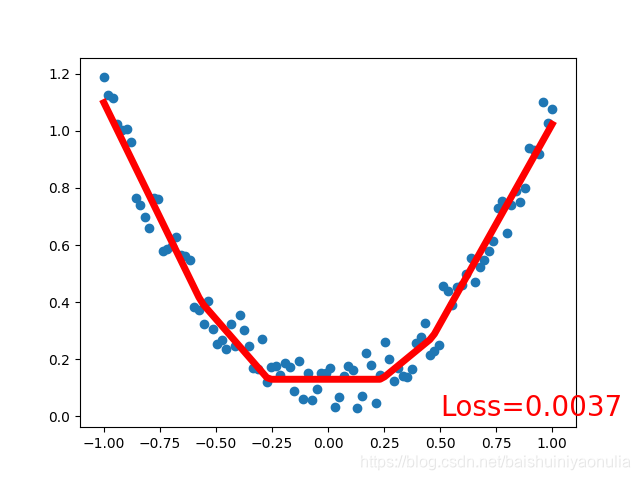
回归网络
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1,1,100), dim=1)
y = x.pow(2) + 0.2*torch.rand(x.size())
x, y = Variable(x).cuda(), Variable(y).cuda()
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(1, 10, 1)
'''
net = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1),
)
'''
net.cuda()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
loss_func = torch.nn.MSELoss()
plt.ion()
plt.show()
for t in range(300):
prediction = net(x)
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0 :
plt.cla()
plt.scatter(x.data.cpu().numpy(), y.data.cpu().numpy())
plt.plot(x.data.cpu().numpy(), prediction.data.cpu().numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.item(), fontdict={'size':20, 'color':'red'})
plt.pause(0.1)
plt.ioff()
plt.show()