最近在看Feature Engineering for Machine Learning。这本书给了我很大的启发。它引入了一些很新颖的观点,比如:
- 所谓Data,是我们对真实世界现象的一种观测。
- 所谓Feature,是我们对raw data的一种数值型表示(也就是说,raw data和feature实际上是不同的)。
这个第二点说得确实有道理,因为如果我们不把哪些text转换为model可以处理的data的话,是不可以继续往下处理的。
另外,当我们看到feature这个词的时候,我们就应该立刻想到pandas里面的Series对象。换而言之,feature既有名字,也有像列表一样的内容。
一. Numerical Features简介
这个专栏的第一篇博客,我打算介绍numerical features, 正如上文所提到的,feature是对row data的一种数值型表示,然而,我的numerical features的,值全都已经是模型可以直接处理的数据,那我们还要不要进行FE呢?这个当然要视具体情况而定。
(1)观察特征的取值范围
进行FE时,一个很重要的一个步骤是观察特征的取值范围。众所周知好的特征取决于具体的数据和模型,所以说特征的取值范围对某些模型有着很大的影响,比如:
- 使用Euclidean distance的模型,如k-means聚类,knn,RBF核的模型,对你特征的取值范围就很敏感。
- 而使用logical function的模型,如基于space-partitioning的树——决策树,GBM,RF;这些模型对这个就不是很敏感。
你当然可以在每次建模之前都使用normalization,不过这在一定程度上牺牲了模型的可解释性,因此在面对space-partitioning树的时候,你可以不进行normalization。
(2)观察特征的分布
在很多notebook中我们经常会看到关于某一个特征的分布。这是因为某些模型确实依赖于你特征的分布。
比如进行LR的时候,我们往往希望residual是normal distribution的。
二. Binarization和Binning
在big data的时代,以count为代表的一类特征,几乎没有范围的上限——比如某个user听某一个特定歌曲的次数。因为现在很多音乐app都设置了无限循环的功能,很多user可能就真的放在那里,让他一直播放,这样我们的次数特征就很高了。通过这个示例我们就能说明,对于某些特征,我们是不能直接处理raw data的,必须要对他进行转换,由此引入了binarization和binning两种方法。
这个Binarization比较简单,一般而言,对于非0的特征直接转化为1,而值为0的特征则保持不变——这个可以代表“是否存在”的含义。我就不具体展开了。
Binning也是一种比较简单,而且我们也使用得较为频繁的一种FE的方法。这种方法的核心思想就是把我们的raw data转化为coarser granularity。下面我来介绍一下两种常见的binning方法。
(1)Fixed-width binning
这个就是我们常见的等宽分箱法。之所以会想到用等宽分箱法,主要的原因是:
- 对于线性模型,你某一个特征的系数是要用到这个特征的所有值上的。而如果你特征中的值差异很大,那我们肯定无法接受。
- 对于使用Euclidean distance的模型,以k-means为例,如果某一个点具有很大的特征值,那将对我们相似性的测量造成巨大的影响。
(2)Quantile binning
分位数分箱,又叫等频分箱法,这个可以直接由pandas里面的qcut完成。
等频分箱法的出现,主要是为了弥补等宽分箱法中,数据之间的间隙过大,很多箱子中可能根本就没有数据的缺陷。
三. log transform和power transform
log transform主要是用来解决heavy tail distribution的。为什么我们要解决heavy tail distribution?这就不得不介绍我们的pareto principle了。所谓的pareto principle就是我们俗称的二八定律。这个定律的核心意义就在于把目光全部放在大部分的情况中,对于一些小的,极端的情况则是直接无视。对于一些分布,如指数分布,确实很有用,但是就是存在一些heavy tail distribution, 它的特殊性质不能让我们忽视所谓的“小的,极端的”情况。这是我们就可以使用log transform将其转化为非heavy tail distribution了。
使用log transfrom还有一点要注意,定义域的问题自然不用说,为了防止负数的出现,以及处理负无穷这种极端的情况,我们一般都是先加一,再进行log transform的。
power transform则是用来解决另一个问题,以poission distribution为例,它的期望和方差是相同的。这就导致了,你期望越大,方差也就越大,这个是无法忍受的,因此我们需要让期望和方差脱离相互之间的依赖, 最简单的方法就是将输入变量开一个根号。当然我们有更加正规的做法,如下图所示:
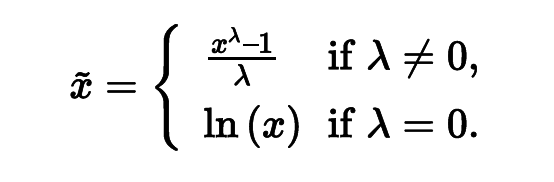
这种方法叫做Box-Cox transform, 用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。
四. Feature scaling或者Normalization
这个方法也是比较常见的,主要用于不同的特征范围差异较大的情况。所谓的scaling其实就是乘了一个constant。乘了一个常数以后,分布本身没有发生改变,只是范围发生了变化而已。接下来我要介绍的三种分法,都叫做feature scaling或者normalization。
(1)Min-max scaling
(2)Standardization
(3)l2 normalization
(P.S. 对于稀疏特征而言,最好不使用前两种方法,这是因为,减去一个非0的数,反而会使一个稀疏的特征变成不稀疏的,从而加大了计算量)
五. Feature interaction
这里的interaction指的是使用原来的特征创建新的特征。这种做法增加了模型的复杂度,所以也随之增加了模型的计算量。
一开始看到这里的时候我也很疑惑,按理来说使用多个子特征创造新的特征的时候,原来的子特征完全可以被丢弃了,但是这里并不是这个意思。
比如以线性模型为例,大家都知道现实世界中的target都很难用observation线性表示。所以说为了提高线性模型的准确度,我们需要对特征进行feature interaction:
这里x之间相连,并不是代表着乘法,还可以代表别的,比如AND操作,如此看来,确实增加了模型的复杂度, 从原来的O(n)提高到了O(n^2)。
六. Feature selection
原来我们的Feature interaction导致我们的模型复杂度太高了,所以我们就得想办法降低这个复杂度,一个简单的方法就是进行feature selection。
在我看来,这个feature selection并没有减少训练的时间,只是减少了过拟合的风险。之所以得出这样的结论,是考虑到我们的训练过程是offline的,因此,考虑训练时间应该考虑总体上的训练时间(包括多次训练的时间)。实际上,我们确实得经过多次训练才能得到最正确的特征,因此,训练时间不减反增,减少的只是测试的时间。
Feature selection有很多种方法,常见的有这三种:
(1) Filter方法
这种方法比较简单,就是通过预处理的方法提前过滤掉一些特征,比如:
- 直接过滤掉方差较小的一些特征。
- 研究自变量与因变量之间的相关系数,设置一个threshold,低于这个threshold,直接去掉。
这个方法的缺陷就在于,他只考虑了数据,没有考虑到具体的模型,一个好的FE,应该不仅仅考虑到数据,还要兼顾模型;我们之前提到的那些方法,都与具体的模型进行了呼应。所以说,在使用filter方法时候,应该稍微保守一点,以免删去了重要的信息。
(2)Wrapper方法
这个方法就比较复杂了,它的流程主要是:把你的特征分为多个重叠的子集,对每个特征子集和目标,分别进行训练,由此得到重要性最低的特征。这样一来,我们就可以得到最不重要的特征了,这样我们就可以把它直接删去。
(3)Embedding方法
这个Embedding方法更加简单了。他就是在你的object function中添加一些正则化项,通过正则化抑制的作用降低部分特征权重,以达到特征筛选,降低模型复杂度,最后防止过拟合的特性。最常见的正则化项就是增加l1 norm和l2 norm两类。
其中l1 norm又叫做sparsity constraint。能有效地进行特征选择。
