选择排序和冒泡排序
学习了选择排序与冒泡排序后,以我目前的水平认为,选择排序和冒泡排序的结果上,其实都是将整数型或浮点型的数排成有序数列的算法,即将数从大到小或从小到大排列。
但是,它们使数排成有序数列的过程,是有不同的,于是我就有个疑问,它们实现排序的效率有何不同呢。
以下分别是是关于选择排序与冒泡排序的代码
选择排序
#include <iostream>
using namespace std;
int main(void)
{
int nums[] = { 5,8,7,2,9,16,54,20,31,0 };//定义一个若干整数的数组
int nums_size = sizeof(nums) / sizeof(int);//算出有nums数组有多少个数
int min = nums[0];//假设最小值就是数组的第一位次
int index;
int temp;
for (int i = 0; i < nums_size; i++)
{
index = i;
min = nums[i];
for (int j = i + 1; j < nums_size ; j++)
{
if (nums[j] < min)//将nums数组中的数由小到大排列,检索nums数组中的所有数,若找到该数列中最小的数,即j位次与i位次交换,实现排序
{
min = nums[j];//记录第i小的最小值
index = j;//记录最小值所在的位次
}
}//交换位置
temp = nums[i];
nums[i] = min;
nums[index] = temp;
}
for (int i = 0; i < nums_size; i++)
{
cout << nums[i] << "\t";//输出最终结果
}
return 0;
}
冒泡排序
#include <iostream>
using namespace std;
int main(void)
{
int nums[] = { 5,8,7,2,9,16,54,20,31,0 };//定义一个若干整数的数组
int nums_size = sizeof(nums) / sizeof(int);//算出有nums数组有多少个数
int temp;
for (int i = 0; i < nums_size; i++)
{
for (int j = 0; j < nums_size - i - 1; j++)
{
if (nums[j] > nums[j + 1])//如果前面那位比后面那位的值大,那么前后互换
{
temp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = temp;
}
}//交换位置
}
for (int i = 0; i < nums_size; i++)
{
cout << nums[i] << "\t";//输出最终结果
}
return 0;
}
由两种方式排序的代码可以清楚的得出,选择排序比较专一,一心只想找到第i个最小的数,找到了第i次最小的数,就进入下一轮了。而冒泡排序比较拐弯抹角,它排序的过程与它的算法的名字一致,数组中的数是通过逐一的交换位置,实现的过程像水中的泡泡浮出水面一样,过程很美丽,但这样所耗费的时间较选择排序来说应该是更长的。
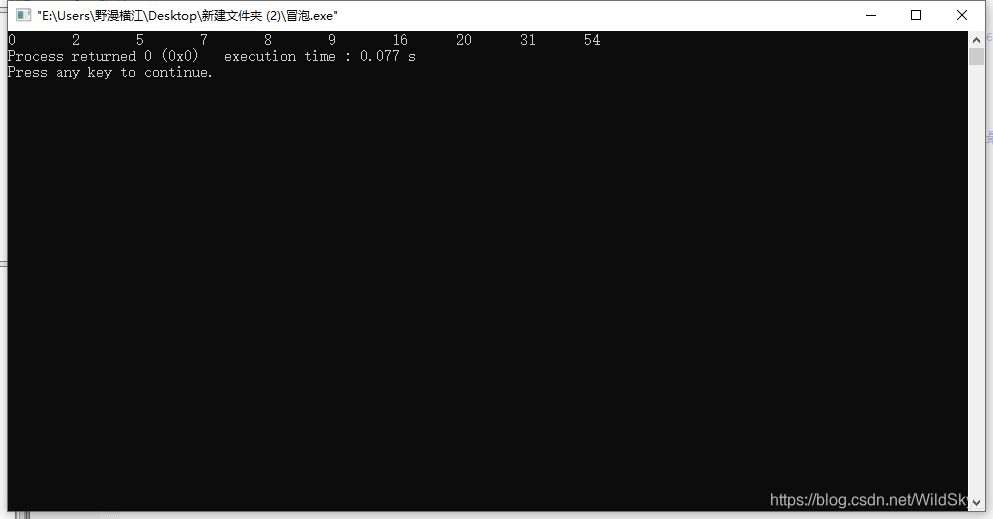
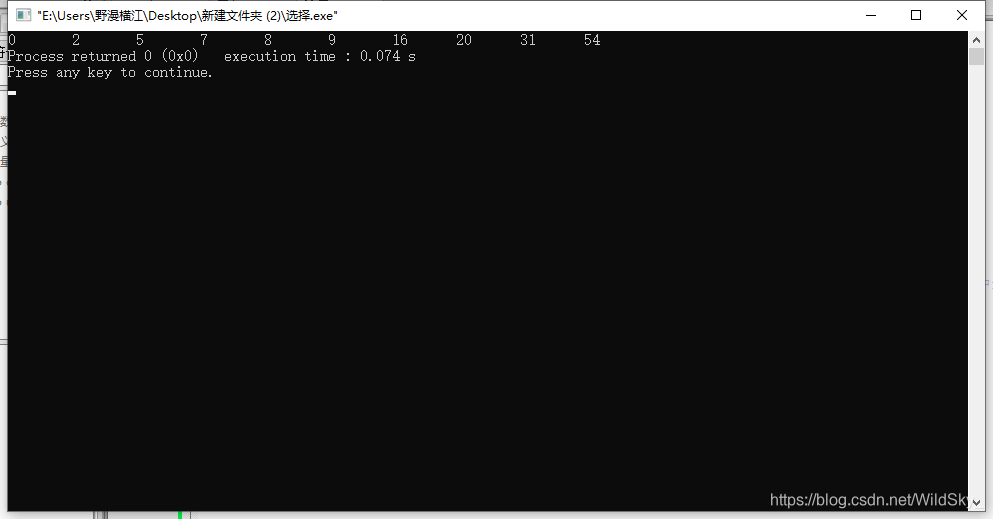
经过N次测试,发现冒泡排序在相同情况下实现排序所耗费的时间确实要比选择排序多些。
在这里仅放一次对比图进行比较吧(小伙伴们可以自行测试)
所耗费时间如图所示