引言
单链表结点中只有一个指向其后继的指针,这使得单链表只能从头结点依次顺序地向后遍历。若要访问某个结点的前驱结点(插入、删除操作时),只能从头开始遍历 ,访问后继结点的时间复杂度为 0(1),访问前驱结点的时间复杂度为 O(n)。
为了克服单链表的上述缺点,引入了双链表,双链表结点中有两个指针 prior 和 next, 分别
指向其前驱结点和后继结点。如下图:

双链表的结点结构体
typedef struct DNode{ //定义单链表结点类型
ElemType data; //数据域
struct DNode *prior,*next; //前驱和后继指针
}DNode, *DLinkList;
双链表的操作
1.插入(方式不唯一)
① s->next=p->next;
② p->next->prior=s;
③ s->prior=p;
④ p->next=s;
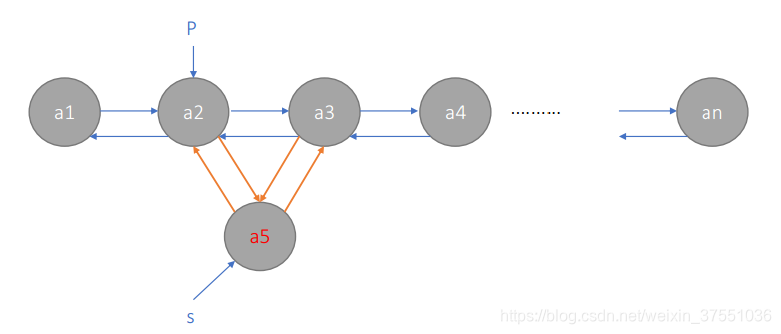
注意:顺序不唯一,可自行分析。但不能过早执行④ ,如果过早修改p的后继,就会丢失a3,就无法建立a3和a5的关系
2.删除
① p->next=q->next;
② q->next->prior=p;
③ free(q);
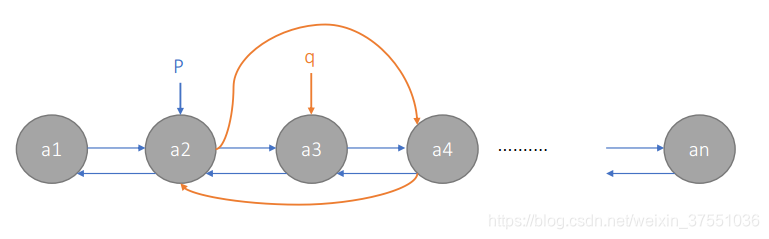
双向链表的特点是节点可以可以轻易的访问当前元素的前节点或后节点,相对单向链表每个节点多了一个前指针,因此相对要多一些空间的开销。用空间换时间。
参考资料
王道数据结构
