序列化
将内存中的对象转换成字节序列用于存储或者网络传输
反序列化
把从磁盘或者网络拿到的字节序列还原对象,提供给程序使用
为什么使用自己的序列化
Jdk本身提供了serializable接口实现序列化操作,但是它序列化的结果太笨重,不适用于在集群网络中有大量对象传输的场景。hadoop提供了Writable接口实现序列化。hadoop2.x里面包含了avro和protocol buffer。
几种序列化框架比较
1.概述
thrift和avro都提供rpc服务和序列化,而protocol buffer只是提供序列化功能。
thrift是一个跨语言的轻量级RPC消息和数据交换框架,Thrift能生成的语言有: C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk, and OCaml。
Avro是强调一种高效的序列化,标准性的云计算的数据交换和存储的Protocol,Avro的创新之处在于融合了显式,declarative的Schema和高效二进制的数据表达,强调数据的自我描述,克服了以往单纯XML或二进制系统的缺陷。
Avro对Schema动态加载功能,是Thrift编程接口所不具备的,符合了Hadoop上的Hive/Pig及NOSQL 等既属于ad hoc,又追求性能的应用需求。
2.protobuf
一条消息数据,用protobuf序列化后的大小是json的10分之一,xml格式的20分之一,是二进制序列化的10分之一,总体看来ProtoBuf的优势还是很明显的。
protobuf是google提供的一个开源序列化框架,类似于XML,JSON这样的数据表示语言,详情访问protobuf的google官方网站。
protobuf在google中是一个比较核心的基础库,作为分布式运算涉及到大量的不同业务消息的传递,如何高效简洁的表示、操作这些业务消息在google这样的大规模应用中是至关重要的。而protobuf这样的库正好是在效率、数据大小、易用性之间取得了很好的平衡。
2.1.protobuf简单总结
a.灵活(方便接口更新)、高效(效率经过google的优化,传输效率比普通的XML等高很多);
b.易于使用;开发人员通过按照一定的语法定义结构化的消息格式,然后送给命令行工具,工具将自动生成相关的类,可以支持java、c++、python等语言环境。通过将这些类包含在项目中,可以很轻松的调用相关方法来完成业务消息的序列化与反序列化工作。
c.语言支持;原生支持c++,java,python
22.个人总结的适用protobuf的场合
a.需要和其它系统做消息交换的,对消息大小很敏感的。那么protobuf适合了,它语言无关,消息空间相对xml和json等节省很多。
b.小数据的场合。如果你是大数据,用它并不适合。
c.项目语言是c++,java,python的,因为它们可以使用google的源生类库,序列化和反序列化的效率非常高。其它的语言需要第三方或者自己写,序列化和反序列化的效率不保证。
d.总体而言,protobuf还是非常好用的,被很多开源系统用于数据通信的工具,在google也是核心的基础库。
3.Thrift和avro比较
3.1.Schema处理
a.thrift依赖IDL-->代码的生成,静态的。走代码生成,编译载入的流程。
b.可以生成代码,后编译执行,但是还必须依赖IDL(meta元数据描述);也可以走动态解释执行IDL
3.2.序列化的方式
a.thrift提供多种序列化实现,TCompactProtocol,TBinaryProtocol,每个Field前面都是带Tag的,这个Tag用于标识这个域的类型和顺序ID(IDL中定义,用于Versioning)。在同一批数据里面,这些Tag的信息是完全相同的,当数据条数大的时候这显然就浪费了。

b.Avro,格式包括--》文件头中有schema+数据records(自描述)

只对感兴趣的部分反序列化
schema允许定义数据的排序order
采用block链表结构,突破了用单一整型表示大小的限制。比如Array或Map由一系列Block组成,每个Block包含计数器和对应的元 素,计数器为0标识结束。
3.3.RPC的服务
a.Avro提供了
HttpServer : 缺省,基于Jetty内核的服务
NettyServer: 新的基于Netty的服务
b.Thrift提供了:
TThreadPolServer: 多线程服务
TNonBlockingServer: 单线程 non blocking的服务
THsHaServer: 多线程 non blocking的服务
4.总结
Thrift适用于程序对程序静态的数据交换,要求schema预知并相对固定;
Avro在Thrift基础上增加了对schema动态的支持且性能上不输于Thrift;
Avro显式schema设计使它更适用于搭建数据交换及存储的通用工具和平台,特别是在后台;
目前Thrift的优势在于更多的语言支持和相对成熟;
PB具有跨平台、解析速度快、序列化数据体积小、扩展性高、使用简单的特点,但是内嵌并没有提供RPC的通讯
举例
场景描述:统计文件中年龄最大的人
文件内容:
Messi 35 Havi 36 Ibrahimović 37
实现逻辑:在Mapper阶段,使用字符1作为所有Person对象的Key,在Reducer阶段就可以拿到所有Person对象做统计
package com.jv.hadoop.mr.serial;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
/*
* 找出文件中年龄最大的人,并输出此人的信息
*
* 自定义的JavaBean要在Hadoop中使用,则需要实现Writable序列化接口
*/
public class Person implements Writable{
private String name;
private int age;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/*
*(non-Javadoc)
* @see org.apache.hadoop.io.Writable#write(java.io.DataOutput)
* 重写序列化方法
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(age);
}
/*
* (non-Javadoc)
* @see org.apache.hadoop.io.Writable#readFields(java.io.DataInput)
* 重写反序列化方法
*/
@Override
public void readFields(DataInput in) throws IOException {
//反序列的顺序必须和序列化顺序一直,否则可能编译不出错,但是运行时出问题
this.name = in.readUTF();
this.age = in.readInt();
}
}
package com.jv.hadoop.mr.serial;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*
* LongWritable:输入Key类型
* Text:输入Value类型
* Text:输出Key类型
* Person:输出Value类型
*
* 针对Mapper的输出可以使用Hadoop原生的类型或者自定义类型
* 如:BooleanWritable ByteWritable IntWritable FloatWritable LongWritable DoubleWritable Text MapWritable ArrayWritable
*/
public class PersonMapper extends Mapper<LongWritable, Text, Text, Person>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Person>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] info = line.split(" ");
Person p = new Person();
p.setName(info[0]);
p.setAge(Integer.parseInt(info[1]));
//将所有的Person对应到同一个Key上,以便Reducer进行处理
context.write(new Text("1"), p);
}
}
package com.jv.hadoop.mr.serial;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.log4j.Logger;
/*
* LongWritable:输入Key类型
* Text:输入Value类型
* Text:输出Key类型
* Person:输出Value类型
*
* 针对Reducer的输入\输出可以使用Hadoop原生的类型或者自定义类型
* 如:BooleanWritable ByteWritable IntWritable FloatWritable LongWritable DoubleWritable Text MapWritable ArrayWritable
*/
public class PersonReducer extends Reducer<Text, Person, Person, NullWritable>{
Logger logger = Logger.getLogger(PersonReducer.class);
@Override
protected void reduce(Text key, Iterable<Person> values, Reducer<Text, Person, Person, NullWritable>.Context context)
throws IOException, InterruptedException {
Person rlt = new Person();
//找出最大值
for (Person person : values) {
if(rlt == null || rlt.getAge() < person.getAge()) {
rlt.setName(person.getName());
rlt.setAge(person.getAge());
}
}
context.write(rlt, NullWritable.get());
}
}
package com.jv.hadoop.mr.serial;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PersonDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置MR调度程序类
job.setJarByClass(Person.class);
//设置Mapper类
job.setMapperClass(PersonMapper.class);
//设置Reducer类
job.setReducerClass(PersonReducer.class);
//设置Mapper输出Key和Value类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Person.class);
//设置Reducer输出Key和Value类
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(NullWritable.class);
//设置输入文件或目录路径
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.245.150:9000/serial"));
//设置输出文件目录路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.245.150:9000/serial/result"));
//提交Job执行
boolean flag = job.waitForCompletion(true);
System.exit(flag ? 0 : 1);
}
}
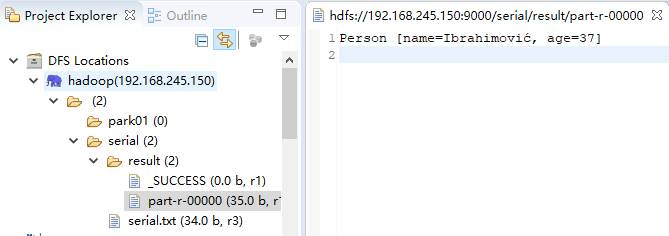
输出结果为: