LevelDB基本介绍
LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values.
Authors: Sanjay Ghemawat ([email protected]) and Jeff Dean ([email protected])
Features
- Keys and values are arbitrary byte arrays.
- Data is stored sorted by key.
- Callers can provide a custom comparison function to override the sort order.
- The basic operations are
Put(key,value),Get(key),Delete(key). - Multiple changes can be made in one atomic batch.
- Users can create a transient snapshot to get a consistent view of data.
- Forward and backward iteration is supported over the data.
- Data is automatically compressed using the Snappy compression library.
- External activity (file system operations etc.) is relayed through a virtual interface so users can customize the operating system interactions.
Documentation
LevelDB library documentation is online and bundled with the source code.
Limitations
- This is not a SQL database. It does not have a relational data model, it does not support SQL queries, and it has no support for indexes.
- Only a single process (possibly multi-threaded) can access a particular database at a time.
- There is no client-server support builtin to the library. An application that needs such support will have to wrap their own server around the library.
源代码地址:https://github.com/google/leveldb
LevelDB是Google开源的持久化KV单机数据库,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,也就是说,LevelDB很适合应用在查询较少,而写很多的场景。
LevelDB是一个功能上类Redis的key/value存储引擎。Redis是一个基于纯内存的存储系统,而LevelDB是基于内存 + SSD的架构,内存存储最新的修改和热数据(可理解为缓存),SSD作为全量数据的持久化存储,所以LevelDB具备比redis更高的存储量,且具备良好的写入性能,读性能就略差了,主要原因是由于冷数据需要进行磁盘IO。Facebook在levelDB的基础上优化了 RocksDB。
LevelDB一般采用 proxy + 多机主备 的形式搭建集群,常见的兼容Redis协议,可通过Redis客户端访问。
LevelDB应用了LSM (Log Structured Merge) 策略,lsm_tree对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式高效地将更新迁移到磁盘,降低索引插入开销。
LevelDB的架构
LevelDB 有点类似于建筑,分为地基和地面两部分,也就是磁盘和内存,而地基又好比地壳结构分了很多层级,不同层级的数据还会定期从上往下移动 —— 沉积作用。如果磁盘底层的冷数据被修改了,它又会再次进入内存,一段时间后又会被持久化刷回到磁盘文件的浅层,然后再慢慢往下移动到底层。
内存结构
LevelDB 的内存中维护了 2 个跳跃列表,一个是只读的 rtable,一个是可修改的 wtable。简单理解,跳跃列表就是一个 Key 有序的 Set 集合,key通过分层连接的方式,提高链表的查找速率。跳跃列表的查找和更新操作时间复杂度都是 Log(n)。
跳跃列表是由多个层次的链表构成,其中最底层的链表存储了所有的 Key,它们是有序的。普通链表并不支持快速二分查找,但是跳跃链表的特殊结构可以让最底层的链表以近似二分查找算法的效率定位到指定节点。简单理解就是跳跃列表同时具备了有序数组的快速定位能力和链表的高效增删能力。但是它会付出一定的代价,在实现上有一定的复杂度。
rtable和wtable的数据结构
其中 sequence 为全局自增序列号,LevelDB 遇到一个修改操作,全局序列号自动加一。LevelDB 中的 Key 存储了多个版本的 Value。LevelDB 使用序列号来标记键值对的版本,序列号越大,对应的键值对越新。
type 为数据类型,标记是 Put 还是 Delete 操作,只有两个取值,0 表示 Delete,1 表示 Put。
如果是删除操作,后面的 value_size 字段值 为 0,value 字段值是空的。我们要将 Delete 操作等价看成 Put 操作。同时为了节省存储空间,internal_key_size 和 value_size 都要采用 varint 整数编码。
如果跳跃列表中同一个 key 存在多个修改操作,也就是说有多个「复合 Key」,那么这几个「复合 Key」 肯定会挨在一起按照 sequence 值排序的。当 Get 操作到来时,它会在跳跃列表中定位到 key 所在的位置,选择这几个同样的 key 中 seq 最大的「复合 Key」,提取出其中的 value 值返回。
待 Put 和 Delete 操作日志写到日志文件后,其键值对合并成「复合 Key」插入到 wtable 的指定位置中。
待 wtable 的大小达到一个阈值,LevelDB 将它凝固成只读的 rtable,同时生成一个新的 wtable 继续接受写操作。rtable 将会被异步线程刷到磁盘中。Get 操作会优先查询 wtable,如果找不到就去 rtable 中去找,rtable 如果还找不到,再去磁盘文件里去找。
因为 wtable 要支持多线程读写,所以访问它是需要加锁控制。而 rtable 是只读的,它就不需要,但是它的存在时间很短,rtable 一旦生成,很快就会被异步线程序列化到磁盘上,然后就会被置空。但是异步线程序列化也需要耗费一定的时间,如果 wtable 增长过快,很快就被写满了,这时候 rtable 还没有完成序列化,而wtable 急需变身怎么办?这时写线程就会阻塞等待异步线程序列化完成,这是 LevelDB 的卡顿点之一,也是未来 RocksDB 的优化点。
图中还有个日志文件,记录了近期的写操作日志。如果 LevelDB 遇到突发停机事故,没有持久化的 wtable 和 rtable 数据就会丢失。这时就必须通过重放日志文件中的指令数据来恢复丢失的数据。注意到日志文件也是有两份的,它和内存的跳跃列表正好对应起来。当 wtable 要变身时,日志文件也会跟着变身。待 rtable 落盘成功之后,只读日志文件就可以被删除了。
磁盘结构
LevelDB 在磁盘上存储了很多 sst 文件,sst 表示 Sorted String Table,文件里所有的 Key 都会有序的。每个文件都会对应一个层级,每个层级都会有多个文件。底层的文件内容来源于上一层,最终它们都会来源于 0 层文件,而 0 层的文件又来源于内存里的 rtable 序列化。一个 rtable 会被序列化为一个完整的 0 层文件。这就是我们前面所说的「下沉作用」。
从内存的 rtable 序列化成 0 层 sst 文件称之为「Minor Compaction」,从 n 层 sst 文件下沉到 n+1 层 sst 文件称之为「Major Compaction」。之所以这样区分是因为 Minor 速度很快耗费资源少,将 rtable 完整地序列化为一个 sst 文件就完事了。而 Major 会涉及到多个文件之间的合并操作,耗费资源多,速度慢。层级越深的文件总容量越大,在 LevelDB 源码里有一个层级容量公式,容量和层级呈指数级关系。而通常每个 sst 文件的大小都差不多,区别就成了每一层的文件数量不一样。
capacity=level>0&&10^(level+1)M
每个文件里面的 Key 都是有序的,也就是说它内部的 Key 取值会有一个确定的范围。0 层文件和其它层文件有一个明显的区别那就是其它层内部的文件之间范围不会重叠,它们按照 Key 的顺序严格做了切分。而 0 层文件的内容是直接从内存 dump 下来的,所以 0 层的多个文件的 Key 取值范围会有重叠。
当内存出现读 miss 要去磁盘搜寻时,会首先从 0 层搜寻,如果搜不到再去更深层次搜寻。
如果是其它层级,搜寻速度会很快,因为可以根据 Key 的范围快速确定它可能会位于哪个文件中。但是对于 0 层,因为文件 Key 范围会重叠,所以它可能存在于多个文件中,那就需要对这多个文件进行搜寻。正因如此,LevelDB 限制了 0 层文件的数量,如果数量超出了默认的 4 个,就需要「下沉」到 1 层,这个「下沉」操作就是 Major Compaction。
所有文件的 Key 取值范围、层级和其它元信息会存储在数据库目录里面的 MANIFEST 文件中。数据库打开时,读取一下这个文件就知道了所有文件的层级和 Key 取值范围。
MANIFEST 文件也有版本号,它的版本号体现在文件名上如 MANIFEST-000361。每一次重新打开数据库,都会生成一个新的 MANIFEST 文件,具有不同的版本号,然后还需要将老的 MANIFEST 文件删除。
数据库目录中还有另外一个文件 CURRENT,它里面的内容很简单,就是当前 MANIFEST 的文件名。LevelDB 首先读取 CURRENT 文件才知道哪个 MANIFEST 文件是有效文件。在遇到断电时,会存在一个小概率中间状态,新旧 MANIFEST 文件共存于数据库目录中。
我们知道 LevelDB 的数据库目录不允许多进程同时访问,那它是如何防止其它进程意外对这个目录文件进行读写操作呢?仔细观察数据库目录,你还会发现一个名称为 LOCK 的文件,它就是控制多进程访问数据库的关键。当一个进程打开了数据库时,会在这个文件上加上互斥文件锁,进程结束时,锁就会自动释放。
还有最后一个不那么重要的操作日志文件 LOG,它记录了数据库的一系列关键性操作日志,例如每一次 Minor 和 Major Compaction 的相关信息。
多路归并
Compaction 是比较耗费资源的操作,为了不影响线上的读写操作,LevelDB 将 Compaction 工作交给一个单一的异步线程来完成。如果工作量巨大,这个单一的异步线程也会有点吃不消。当异步线程吃不消的时候,线上内存的读写操作也会收到影响。因为只有 rtable 沉到磁盘里了,wtable 才可以变身。只有 wtable 变身了,才会有新的 wtable 被创建来容纳后续更多的键值对。总之就是一环套一环,环环相扣。
下面我们来研究一下 Compaction 。Minor Compaction 很好理解,就是内容空间有限,所以需要将 rtable 中的数据 dump 到磁盘 0 层文件。那为什么需要从 0 层文件 Compact 下沉到 1 层文件呢?因为 0 层文件如果过多,就会影响查找效率。前面我们提到 0 层文件之间的 Key 范围会有重叠,所以单个 Key 可能存在于多个文件中,IO 读次数将会被文件的数量放大。通过 Major Compaction 可以减少 0 层文件的数量,提升读效率。那是不是只需要下沉到 1 层文件就可以了呢?那 LevelDB 究竟是什么原因需要这么多层级呢?
假设 LevelDB 只有 2 层( 0 层和 1 层),那么时间一长,1 层肯定会累计大量的文件。当 0 层的文件需要下沉时,也就是 Major Compaction 要来了,假设只下沉一个 0 层文件,它不是简简单单地将文件元信息的层数从 0 改成 1 就可以了。它需要继续保持 1 层文件的有序性,每个文件中的 Key 取值范围要保持没有重叠。它不能直接将 0 层文件中的键值对分散插入或者追加到 1 层的所有文件中,因为 sst 文件是紧凑存储的,插入操作肯定涉及到磁盘块的移动。再说还有删除操作,它需要干掉 1 层文件中的某些已删除的键值对,避免它们持续占用空间。
那 LevelDB 究竟是怎么做的呢?它采用多路归并算法,将相关的 0 层文件和 1 层 sst 文件作为输入,进行多路归并,生成多个新的 1 层 sst 文件,再将老的 sst 文件干掉,同时还会生成新的 MANIFEST 文件。对于每个 0 层文件,它会根据 Key 的取值范围搜寻 1 层文件中和它的范围有重叠部分的 sst 文件。如果 1 层文件数量过多,每次多路归并涉及到的文件数量太多,归并算法就会非常耗费资源。所以 LevelDB 同样也需要控制 1 层文件的数量,当 1 层容量满时,就会继续下沉到 2 层、3 层、4 层等。
非 0 层的多路归并资源消耗要少一些,因为单个文件的 Key 取值范围有限,能覆盖到下一层的文件数量有限,参与多路归并的输入文件就少了很多。但是这个逻辑有个漏洞,那就是上下层的文件数量有 10 倍的差距,按照平均范围间隔来算,意味着上层平均一个文件的取值范围会覆盖到下一层的 10 个文件。所以说非 0 层的多路归并资源消耗其实也不低,Major Compaction 就是一个比较消耗资源的操作。
LevelDB的整体架构
LevelDb本质上是一套存储系统以及在这套存储系统上提供的一些操作接口。为了便于理解整个系统及其处理流程,我们可以从两个不同的角度来看待LevleDb:静态角度和动态角度。从静态角度,可以假想整个系统正在运行过程中(不断插入删除读取数据),此时我们给LevelDb照相,从照片可以看到之前系统的数据在内存和磁盘中是如何分布的,处于什么状态等;从动态的角度,主要是了解系统是如何写入一条记录,读出一条记录,删除一条记录的,同时也包括除了这些接口操作外的内部操作比如compaction,系统运行时崩溃后如何恢复系统等等方面。
LevelDb作为存储系统,数据记录的存储介质包括内存以及磁盘文件,如果像上面说的,当LevelDb运行了一段时间,此时我们给LevelDb进行透视拍照,那么您会看到如下一番景象:
leveldb包含六个部分:内存中的MemTable和Immutalbe MemTable及磁盘上的Current文件, Manifest文件, log文件, SSTable文件。
当应用写入一条Key:Value记录的时候,LevelDb会先往log文件里写入,成功后将记录插进Memtable中,这样基本就算完成了写入操作,因为一次写入操作只涉及一次磁盘顺序写和一次内存写入,所以这是为何说LevelDb写入速度极快的主要原因。
Log文件在系统中的作用主要是用于系统崩溃恢复而不丢失数据,假如没有Log文件,因为写入的记录刚开始是保存在内存中的,此时如果系统崩溃,内存中的数据还没有来得及Dump到磁盘,所以会丢失数据(Redis就存在这个问题)。为了避免这种情况,LevelDb在写入内存前先将操作记录到Log文件中,然后再记入内存中,这样即使系统崩溃,也可以从Log文件中恢复内存中的Memtable,不会造成数据的丢失。
当Memtable插入的数据占用内存到了一个界限后,需要将内存的记录导出到外存文件中,LevleDb会生成新的Log文件和Memtable,原先的Memtable就成为Immutable Memtable,顾名思义,就是说这个Memtable的内容是不可更改的,只能读不能写入或者删除。新到来的数据被记入新的Log文件和Memtable,LevelDb后台调度会将Immutable Memtable的数据导出到磁盘,形成一个新的SSTable文件。SSTable就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称之为LevelDb的原因。
SSTable中的文件是Key有序的,就是说在文件中小key记录排在大Key记录之前,各个Level的SSTable都是如此,但是这里需要注意的一点是:Level 0的SSTable文件(后缀为.sst)和其它Level的文件相比有特殊性:这个层级内的.sst文件,两个文件可能存在key重叠,比如有两个level 0的sst文件,文件A和文件B,文件A的key范围是:{bar, car},文件B的Key范围是{blue,samecity},那么很可能两个文件都存在key=”blood”的记录。对于其它Level的SSTable文件来说,则不会出现同一层级内.sst文件的key重叠现象,就是说Level L中任意两个.sst文件,那么可以保证它们的key值是不会重叠的。这点需要特别注意,后面您会看到很多操作的差异都是由于这个原因造成的。
SSTable中的某个文件属于特定层级,而且其存储的记录是key有序的,那么必然有文件中的最小key和最大key,这是非常重要的信息,LevelDb应该记下这些信息。Manifest就是干这个的,它记载了SSTable各个文件的管理信息,比如属于哪个Level,文件名称叫啥,最小key和最大key各自是多少。下图是Manifest所存储内容的示意:
图中只显示了两个文件(manifest会记载所有SSTable文件的这些信息),即Level 0的test.sst1和test.sst2文件,同时记载了这些文件各自对应的key范围,比如test.sstt1的key范围是“an”到 “banana”,而文件test.sst2的key范围是“baby”到“samecity”,可以看出两者的key范围是有重叠的。
Current文件是干什么的呢?这个文件的内容只有一个信息,就是记载当前的manifest文件名。因为在LevleDb的运行过程中,随着Compaction的进行,SSTable文件会发生变化,会有新的文件产生,老的文件被废弃,Manifest也会跟着反映这种变化,此时往往会新生成Manifest文件来记载这种变化,而Current则用来指出哪个Manifest文件才是我们关心的那个Manifest文件。
以上介绍的内容就构成了LevelDb的整体静态结构,在LevelDb日知录接下来的内容中,我们会首先介绍重要文件或者内存数据的具体数据布局与结构。
log文件
LevelDb对于一个log文件,会把它切割成以32K为单位的物理Block,每次读取的单位以一个Block作为基本读取单位,下图展示的log文件由3个Block构成,所以从物理布局来讲,一个log文件就是由连续的32K大小Block构成的。

在应用的视野里是看不到这些Block的,应用看到的是一系列的Key:Value对,在LevelDb内部,会将一个Key:Value对看做一条记录的数据,另外在这个数据前增加一个记录头,用来记载一些管理信息,以方便内部处理,下图显示了一个记录在LevelDb内部是如何表示的。
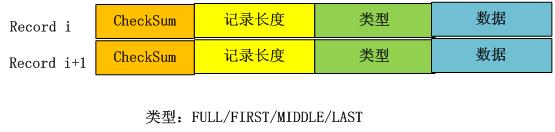
记录头包含三个字段,ChechSum是对“类型”和“数据”字段的校验码,为了避免处理不完整或者是被破坏的数据,当LevelDb读取记录数据时候会对数据进行校验,如果发现和存储的CheckSum相同,说明数据完整无破坏,可以继续后续流程。“记录长度”记载了数据的大小,“数据”则是上面讲的Key:Value数值对,“类型”字段则指出了每条记录的逻辑结构和log文件物理分块结构之间的关系,具体而言,主要有以下四种类型:FULL/FIRST/MIDDLE/LAST。
如果记录类型是FULL,代表了当前记录内容完整地存储在一个物理Block里,没有被不同的物理Block切割开;如果记录被相邻的物理Block切割开,则类型会是其他三种类型中的一种。
假设目前存在三条记录,Record A,Record B和Record C,其中Record A大小为10K,Record B 大小为80K,Record C大小为12K,那么其在log文件中的逻辑布局会如上图所示。Record A是图中蓝色区域所示,因为大小为10K<32K,能够放在一个物理Block中,所以其类型为FULL;Record B 大小为80K,而Block 1因为放入了Record A,所以还剩下22K,不足以放下Record B,所以在Block 1的剩余部分放入Record B的开头一部分,类型标识为FIRST,代表了是一个记录的起始部分;Record B还有58K没有存储,这些只能依次放在后续的物理Block里面,因为Block 2大小只有32K,仍然放不下Record B的剩余部分,所以Block 2全部用来放Record B,且标识类型为MIDDLE,意思是这是Record B中间一段数据;Record B剩下的部分可以完全放在Block 3中,类型标识为LAST,代表了这是Record B的末尾数据;图中黄色的Record C因为大小为12K,Block 3剩下的空间足以全部放下它,所以其类型标识为FULL。
从这个小例子可以看出逻辑记录和物理Block之间的关系,LevelDb一次物理读取为一个Block,然后根据类型情况拼接出逻辑记录,供后续流程处理。
SSTable文件
Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块,但是两者逻辑布局大不相同,根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,而.sst文件内部则是根据记录的Key由小到大排列的,从下面介绍的SSTable布局可以体会到Key有序是为何如此设计.sst文件结构的关键。

上图展示了一个.sst文件的物理划分结构,同Log文件一样,也是划分为固定大小的存储块,每个Block分为三个部分,Block部分是数据存储区, 蓝色的Type区用于标识数据存储区是否采用了数据压缩算法(Snappy压缩或者无压缩两种),CRC部分则是数据校验码,用于判别数据是否在生成和传输中出错。
以上是.sst的物理布局,下面介绍.sst文件的逻辑布局,所谓逻辑布局,就是说尽管大家都是物理块,但是每一块存储什么内容,内部又有什么结构等。下图展示了.sst文件的内部逻辑解释。

可以看出,从大的方面,可以将.sst文件划分为数据存储区和数据管理区,数据存储区存放实际的Key:Value数据,数据管理区则提供一些索引指针等管理数据,目的是更快速便捷的查找相应的记录。两个区域都是在上述的分块基础上的,就是说文件的前面若干块实际存储KV数据,后面数据管理区存储管理数据。管理数据又分为四种不同类型:紫色的Meta Block,红色的MetaBlock 索引和蓝色的数据索引块以及一个文件尾部块。
LevelDb 1.2版对于Meta Block尚无实际使用,只是保留了一个接口,估计会在后续版本中加入内容,下面我们看看数据索引区和文件尾部Footer的内部结构。

上图是数据索引的内部结构示意图。再次强调一下,Data Block内的KV记录是按照Key由小到大排列的,数据索引区的每条记录是对某个Data Block建立的索引信息,每条索引信息包含三个内容,以上图所示的数据块i的索引Index i来说:红色部分的第一个字段记载大于等于数据块i中最大的Key值的那个Key,第二个字段指出数据块i在.sst文件中的起始位置,第三个字段指出Data Block i的大小(有时候是有数据压缩的)。后面两个字段好理解,是用于定位数据块在文件中的位置的,第一个字段需要详细解释一下,在索引里保存的这个Key值未必一定是某条记录的Key,以上图的例子来说,假设数据块i 的最小Key=“samecity”,最大Key=“the best”;数据块i+1的最小Key=“the fox”,最大Key=“zoo”,那么对于数据块i的索引Index i来说,其第一个字段记载大于等于数据块i的最大Key(“the best”)同时要小于数据块i+1的最小Key(“the fox”),所以例子中Index i的第一个字段是:“the c”,这个是满足要求的;而Index i+1的第一个字段则是“zoo”,即数据块i+1的最大Key。
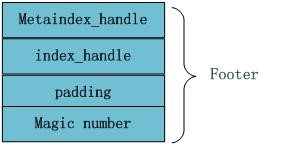
文件末尾Footer块的内部结构见下图,metaindex_handle指出了metaindex block的起始位置和大小;inex_handle指出了index Block的起始地址和大小;这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数。
上面主要介绍的是数据管理区的内部结构,下面我们看看数据区的一个Block的数据部分内部是如何布局的.下图是其内部布局示意图。

从图中可以看出,其内部也分为两个部分,前面是一个个KV记录,其顺序是根据Key值由小到大排列的,在Block尾部则是一些“重启点”(Restart Point),其实是一些指针,指出Block内容中的一些记录位置。
“重启点”是干什么的呢?我们一再强调,Block内容里的KV记录是按照Key大小有序的,这样的话,相邻的两条记录很可能Key部分存在重叠,比如key i=“the Car”,Key i+1=“the color”,那么两者存在重叠部分“the c”,为了减少Key的存储量,Key i+1可以只存储和上一条Key不同的部分“olor”,两者的共同部分从Key i中可以获得。记录的Key在Block内容部分就是这么存储的,主要目的是减少存储开销。“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新记录所有的Key值,假设Key i+1是一个重启点,那么Key里面会完整存储“the color”,而不是采用简略的“olor”方式。Block尾部就是指出哪些记录是这些重启点的。

在Block内容区,每个KV记录的内部结构是怎样的?上图给出了其详细结构,每个记录包含5个字段:key共享长度,比如上面的“olor”记录, 其key和上一条记录共享的Key部分长度是“the c”的长度,即5;key非共享长度,对于“olor”来说,是4;value长度指出Key:Value中Value的长度,在后面的Value内容字段中存储实际的Value值;而key非共享内容则实际存储“olor”这个Key字符串。
MemTable详解
内存中的数据结构Memtable,Memtable在整个体系中的重要地位也不言而喻。总体而言,所有KV数据都是存储在Memtable,Immutable Memtable和SSTable中的,Immutable Memtable从结构上讲和Memtable是完全一样的,区别仅仅在于其是只读的,不允许写入操作,而Memtable则是允许写入和读取的。当Memtable写入的数据占用内存到达指定数量,则自动转换为Immutable Memtable,等待Dump到磁盘中,系统会自动生成新的Memtable供写操作写入新数据,理解了Memtable,那么Immutable Memtable自然不在话下。
LevelDb的MemTable提供了将KV数据写入,删除以及读取KV记录的操作接口,但是事实上Memtable并不存在真正的删除操作,删除某个Key的Value在Memtable内是作为插入一条记录实施的,但是会打上一个Key的删除标记,真正的删除操作是Lazy的,会在以后的Compaction过程中去掉这个KV。
需要注意的是,LevelDb的Memtable中KV对是根据Key大小有序存储的,在系统插入新的KV时,LevelDb要把这个KV插到合适的位置上以保持这种Key有序性。其实,LevelDb的Memtable类只是一个接口类,真正的操作是通过背后的SkipList来做的,包括插入操作和读取操作等,所以Memtable的核心数据结构是一个SkipList。
SkipList是由William Pugh发明。他在Communications of the ACM June 1990, 33(6) 668-676 发表了Skip lists: a probabilistic alternative to balanced trees,在该论文中详细解释了SkipList的数据结构和插入删除操作。
SkipList是平衡树的一种替代数据结构,但是和红黑树不相同的是,SkipList对于树的平衡的实现是基于一种随机化的算法的,这样也就是说SkipList的插入和删除的工作是比较简单的。
关于SkipList的详细介绍可以参考这篇文章:http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html,讲述的很清楚,LevelDb的SkipList基本上是一个具体实现,并无特殊之处。
SkipList不仅是维护有序数据的一个简单实现,而且相比较平衡树来说,在插入数据的时候可以避免频繁的树节点调整操作,所以写入效率是很高的,LevelDb整体而言是个高写入系统,SkipList在其中应该也起到了很重要的作用。Redis为了加快插入操作,也使用了SkipList来作为内部实现数据结构。
LevelDB的读写数据操作
写操作流程:
1、顺序写入磁盘log文件;
2、写入内存memtable(采用skiplist结构实现);
3、写入磁盘SST文件(sorted string table files),这步是数据归档的过程(永久化存储)。
注意:
- log文件的作用是是用于系统崩溃恢复而不丢失数据,假如没有Log文件,因为写入的记录刚开始是保存在内存中的,此时如果系统崩溃,内存中的数据还没有来得及Dump到磁盘,所以会丢失数据;
- 在写memtable时,如果其达到check point(满员)的话,会将其改成immutable memtable(只读),然后等待dump到磁盘SST文件中,此时也会生成新的memtable供写入新数据;
- memtable和sst文件中的key都是有序的,log文件的key是无序的;
- LevelDB删除操作也是插入,只是标记Key为删除状态,真正的删除要到Compaction的时候才去做真正的操作;
- LevelDB没有更新接口,如果需要更新某个Key的值,只需要插入一条新纪录即可;或者先删除旧记录,再插入也可;
读操作流程:
1、在内存中依次查找memtable、immutable memtable;
2、如果配置了cache,查找cache;
3、根据mainfest索引文件,在磁盘中查找SST文件;
举个例子:我们先往levelDb里面插入一条数据 {key="www.samecity.com" value="我们"},过了几天,samecity网站改名为:69同城,此时我们插入数据{key="www.samecity.com" value="69同城"},同样的key,不同的value;逻辑上理解好像levelDb中只有一个存储记录,即第二个记录,但是在levelDb中很可能存在两条记录,即上面的两个记录都在levelDb中存储了,此时如果用户查询key="www.samecity.com",我们当然希望找到最新的更新记录,也就是第二个记录返回,因此,查找的顺序应该依照数据更新的新鲜度来,对于SSTable文件来说,如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。
LevelDB在以太坊中的应用
初始化
在ethdb/database.go的NewLDBDataBase()函数中,
db, err := leveldb.OpenFile(file, &opt.Options{
OpenFilesCacheCapacity: handles,
BlockCacheCapacity: cache / 2 * opt.MiB,
WriteBuffer: cache / 4 * opt.MiB, // Two of these are used internally
Filter: filter.NewBloomFilter(10),
})
file就是leveldb的路径,以太坊的默认路径是/Users/$Owner/Library/Ethereum/geth/chaindata
OpenFilesCacheCapacity:以太坊设置的是1024,作用应该是可打开的文件数吧,后续代码中再确认一下
BlockCacheCapacity:设置的是cache的一半,是384M
WriteBuffer:设置的是cache的1/4,是192M,这个是memtable的size。为什么是1/4呢,因为cache是设置的leveldb总共使用的大小,一半给了BlockCacheCapacity,另外一半是给memtable的。而leveldb写数据的流程是先写memtable,等写满了把这个memtable forzen,然后启用minor compaction到level 0文件,同时new一个memtable供新写入。所以cache的一半是给memtable和frozon memtable用的,单个memory的大小就是1/4
Filter:bloom filter,每个level文件会建filter,10的意思是每个key hash的次数。bloom的位数需要代码确认下
OpenFile就会直接调用到leveldb的db.go文件中
经过一些列初始化,恢复log文件等,建立了若干个goroutine,看代码
func openDB(s *session) (*DB, error) {
....
// Doesn't need to be included in the wait group.
go db.compactionError()
go db.mpoolDrain()
if readOnly {
db.SetReadOnly()
} else {
db.closeW.Add(2)
go db.tCompaction()
go db.mCompaction()
// go db.jWriter()
}
}
compactionError:看代码是监听一些channel做处理,暂未深究,后续补充
mpoolDrain:启动一个30s的ticker读取mempool chan,具体作用暂未深究,后续补充
mCompaction: minor compaction,就是把memory的内容写入到level 0的文件
tCompaction:major compaction,就是合并不同层级的level文件。比如level 0满了(已经有大于等于4个文件了),此goroutine监听到了,就会将level 0的某个文件和level 1的某些文件合并成新的level 1文件
到这里leveldb的初始化就成功了,新建几个goroutine监听是否compaction,基本流程大值如此了
读写数据
leveldb提供了一些接口来写数据,以太坊做了包装,具体看ethdb/interface.go
// Putter wraps the database write operation supported by both batches and regular databases.
type Putter interface {
Put(key []byte, value []byte) error
}
// Database wraps all database operations. All methods are safe for concurrent use.
type Database interface {
Putter
Get(key []byte) ([]byte, error)
Has(key []byte) (bool, error)
Delete(key []byte) error
Close()
NewBatch() Batch
}
// Batch is a write-only database that commits changes to its host database
// when Write is called. Batch cannot be used concurrently.
type Batch interface {
Putter
ValueSize() int // amount of data in the batch
Write() error
// Reset resets the batch for reuse
Reset()
}
定义了三个interface,Putter,Database和Batch与LevelDB读写交互
写数据
写数据又分为写新数据、更新数据和删除数据
leveldb为了效率考虑(如果删除数据和更新数据用传统的方式做的话,需要查找所有数据库找到原始key,效率比较低),此三种情况统统使用插入数据的方式,删除数据是写一个删除标志,更新数据是写一样key带不同的value
那么问题来了,如果更新或删除数据,整个数据库中有两个或更多个相同的key,什么时候合并,查找的时候怎么确定哪个是正确的
答案:
(1)什么时候合并
如果有两个或多个相同的key(或者是删除,key的v是删除标志),一直到major compaction的时候才会执行合并动作或者删除动作,这样可以提升效率
(2)如何查找到正确的值
因为leveldb的分层概念,读数据的时候先查memory,然后再从level 0到level N逐层查询,查询到了就不再查询,这里有个新鲜度的概念,层级越低,新鲜度越高,memory中新鲜度最高。所以对于更新操作来说,即便是某个时刻数据库中有两个或者更过个相同key的kv,会以新鲜度高的为准。如果查询到了key为删除标志,那么直接返回not found即可
写新数据
为了减少leveldb的交互,写数据的时候一般会以Batch进行,就是先往batch里写一堆数据,然后再统一把这个Batch写到leveldb。
即便是单个kv的写入,leveldb内部也是使用batch来写入的,但是这个batch也会即时写入memory和log
以太坊的core/blockchain.go中写block的时候就是新建Batch,然后把Batch写入leveldb
// WriteBlockWithState writes the block and all associated state to the database.
func (bc *BlockChain) WriteBlockWithState(block *types.Block, receipts ...) {
...
// Write other block data using a batch.
batch := bc.db.NewBatch()
if err := WriteBlock(batch, block); err != nil {
return NonStatTy, err
}
....
if err := batch.Write(); err != nil {
return NonStatTy, err
}
....
}
我们来看看batch.Write的实现,在leveldb的db_write.go代码里:
func (db *DB) Write(batch *Batch, wo *opt.WriteOptions) error {
…
<span style="color:#ff0000;">// 这段代码的意思是当batch的内容长度大于memory table的长度(以太坊是192M),
// 一次性写入memory(当写满的时候会触发minor compaction,然后接着写memory直到把内容全部写完)</span>
if batch.internalLen > db.s.o.GetWriteBuffer() && !db.s.o.GetDisableLargeBatchTransaction() {
tr, err := db.OpenTransaction()
if err != nil {
return err
}
if err := tr.Write(batch, wo); err != nil {
tr.Discard()
return err
}
return tr.Commit()
}
…
return db.writeLocked(batch, nil, merge, sync)
}
接着看writeLocked代码:
func (db *DB) writeLocked(batch, ourBatch *Batch, merge, sync bool) error {
// <span style="color:#ff0000;">flush的功能是看是否触发minor compaction</span>
mdb, mdbFree, err := db.flush(batch.internalLen)
…
// Write journal. <span style="color:#ff0000;">写Log文件</span>
if err := db.writeJournal(batches, seq, sync); err != nil {
db.unlockWrite(overflow, merged, err)
return err
}
// Put batches. <span style="color:#ff0000;">写batch数据到memory</span>
for _, batch := range batches {
if err := batch.putMem(seq, mdb.DB); err != nil {
panic(err)
}
seq += uint64(batch.Len())
}
….
// Rotate memdb if it's reach the threshold.
<span style="color:#ff0000;">// 如果memory不够写batch的内容,调用rotateMem,就是把memory frezon触发minor compaction
</span> if batch.internalLen >= mdbFree {
db.rotateMem(0, false)
}
db.unlockWrite(overflow, merged, nil)
return nil
}
有点没看懂为什么先batch.putMem然后判断batch.internalLen与mdbFree比大小再rotateMem,理应是先判断mdbFree...
还有个merge与一堆channel的交互没看明白,后续接着看
再看rotateMem的实现
func (db *DB) rotateMem(n int, wait bool) (mem *memDB, err error) {
retryLimit := 3
retry:
// Wait for pending memdb compaction.
err = db.compTriggerWait(db.mcompCmdC)
if err != nil {
return
}
retryLimit--
// Create new memdb and journal.
<span style="color:#ff0000;"> // 新建log文件和memory,同时把现在使用的memory指向为frozenMem,minor compaction的时候写入frozenMem到level 0文件</span>
mem, err = db.newMem(n)
if err != nil {
if err == errHasFrozenMem {
if retryLimit <= 0 {
panic("BUG: still has frozen memdb")
}
goto retry
}
return
}
// Schedule memdb compaction.
// <span style="color:#ff0000;">触发minor compaction</span>
if wait {
err = db.compTriggerWait(db.mcompCmdC)
} else {
db.compTrigger(db.mcompCmdC)
}
return
}
至此数据写完,如果memory空间够,直接写入memory
如果memory空间不够,等待执行minor compaction(compTrigger内会等待compaction的结果)再写入新建的memory db(是从mempool中拿的,应该是mempool中就两块儿memory,待写入的memory和frozon memory)中
删除数据/更新数据
先看插入新数据的接口,更新数据也是调用这个一样的接口:
func (db *DB) Put(key, value []byte, wo *opt.WriteOptions) error {
return db.putRec(keyTypeVal, key, value, wo)
}插入数据是插入一个type为keyTypeVal,key/value的数据
再看删除数据的接口
func (db *DB) Delete(key []byte, wo *opt.WriteOptions) error {
return db.putRec(keyTypeDel, key, nil, wo)
}删除数据的代码其实就是插入一个type为keyTypeDel,key/nil的数据,当做一个普通的数据插入到memory中
等后续做major compaction的时候找到原始的key再执行删除动作(更新数据也是在major compaction的时候进行)
具体major compaction的代码还未看明白,后续看明白了再贴上来
读数据
读数据是依次从memtable和各个level文件中查找数据,db.go的接口:
func (db *DB) Get(key []byte, ro *opt.ReadOptions) (value []byte, err error) {
err = db.ok()
if err != nil {
return
}
<span style="color:#ff0000;">// 关于snapshot未做研究,后续有研究再贴一下</span>
se := db.acquireSnapshot()
defer db.releaseSnapshot(se)
return db.get(nil, nil, key, se.seq, ro)
}
func (db *DB) get(auxm *memdb.DB, auxt tFiles, key []byte, seq uint64, ro *opt.ReadOptions) (value []byte, err error) {
ikey := makeInternalKey(nil, key, seq, keyTypeSeek)
if auxm != nil {
if ok, mv, me := memGet(auxm, ikey, db.s.icmp); ok {
return append([]byte{}, mv...), me
}
}
<span style="color:#ff0000;">// 拿到memdb和frozon memdb依次查找</span>
em, fm := db.getMems()
for _, m := range [...]*memDB{em, fm} {
if m == nil {
continue
}
defer m.decref()
if ok, mv, me := memGet(m.DB, ikey, db.s.icmp); ok {
return append([]byte{}, mv...), me
}
}
<span style="color:#ff0000;">// 拿到version后从version中各个level的文件中依次查找</span>
v := db.s.version()
value, cSched, err := v.get(auxt, ikey, ro, false)
v.release()
if cSched {
// Trigger table compaction.
db.compTrigger(db.tcompCmdC)
}
return
}
Compaction
compaction是把数据一级一级的往下写,leveldb实现了minor compaction和major compaction
minor compaction,leveldb里面的mCompaction goroutine做的事情,就是把memory中的数据写入到level 0文件中
major compaction,leveldb里面tCompaction goroutine做的事情,就是把低层的level文件合并写入高层的level文件中
mCompaction
func (db *DB) mCompaction() {
var x cCmd
for {
select {
case x = <-db.mcompCmdC:
switch x.(type) {
case cAuto:
db.memCompaction()
x.ack(nil)
x = nil
default:
panic("leveldb: unknown command")
}
case <-db.closeC:
return
}
}
}
还记得写数据的时候rotateMem中会写channel mcompCmdC吗,这个goroutine起来后一直在监听该channel等待做compaction的事情,所以看memCompaction的实现
func (db *DB) memCompaction() {
<span style="color:#ff0000;">// rotateMem的时候把当前使用的memory指向到frozonMem,这里读出来写入level 0文件</span>
mdb := db.getFrozenMem()
// Pause table compaction.
<span style="color:#ff0000;"> // 这里的作用是minor compaction的时候要先暂停major compaction</span>
resumeC := make(chan struct{})
select {
case db.tcompPauseC <- (chan<- struct{})(resumeC):
case <-db.compPerErrC:
close(resumeC)
resumeC = nil
case <-db.closeC:
db.compactionExitTransact()
}
// Generate tables. <span style="color:#ff0000;">创建level 0文件然后写memory到文件
</span> // <span style="color:#ff0000;">flushMemdb是把memory内容写到新建的level 0文件,然后把level 0文件加入到addedTables record中
</span> // <span style="color:#ff0000;">代码里把level 0~N的文件叫做table</span>
db.compactionTransactFunc("memdb@flush", func(cnt *compactionTransactCounter) (err error) {
stats.startTimer()
flushLevel, err = db.s.flushMemdb(rec, mdb.DB, db.memdbMaxLevel)
stats.stopTimer()
return
}, func() error {
for _, r := range rec.addedTables {
db.logf("memdb@flush revert @%d", r.num)
if err := db.s.stor.Remove(storage.FileDesc{Type: storage.TypeTable, Num: r.num}); err != nil {
return err
}
}
return nil
})
rec.setJournalNum(db.journalFd.Num)
rec.setSeqNum(db.frozenSeq)
// Commit.
<span style="color:#ff0000;"> // 就是最终存储tables,写入到version记录。。。后续深入看下</span>
stats.startTimer()
db.compactionCommit("memdb", rec)
stats.stopTimer()
db.logf("memdb@flush committed F·%d T·%v", len(rec.addedTables), stats.duration)
for _, r := range rec.addedTables {
stats.write += r.size
}
db.compStats.addStat(flushLevel, stats)
// Drop frozen memdb. <span style="color:#ff0000;">
// minor compaction之后把指向frozon的memory重新放回mempool中</span>
db.dropFrozenMem()
// Resume table compaction.
// <span style="color:#ff0000;">恢复major compaction</span>
if resumeC != nil {
select {
case <-resumeC:
close(resumeC)
case <-db.closeC:
db.compactionExitTransact()
}
}
// Trigger table compaction.
<span style="color:#ff0000;"> // tcompCmdC就是major compaction要监听的channel,这里写数据到此channel</span>
db.compTrigger(db.tcompCmdC)
}
后续需要继续完善compactionCommit代码,实现都在这里
tCompaction
func (db *DB) tCompaction() {
for {
if db.tableNeedCompaction() {
select {
case x = <-db.tcompCmdC:
case ch := <-db.tcompPauseC:
db.pauseCompaction(ch)
continue
case <-db.closeC:
return
default:
}
} else {
for i := range ackQ {
ackQ[i].ack(nil)
ackQ[i] = nil
}
ackQ = ackQ[:0]
select {
case x = <-db.tcompCmdC:
case ch := <-db.tcompPauseC:
db.pauseCompaction(ch)
continue
case <-db.closeC:
return
}
}
if x != nil {
switch cmd := x.(type) {
case cAuto:
ackQ = append(ackQ, x)
case cRange:
x.ack(db.tableRangeCompaction(cmd.level, cmd.min, cmd.max))
default:
panic("leveldb: unknown command")
}
x = nil
}
db.tableAutoCompaction()
}
}
计算是否要执行major compaction
func (v *version) computeCompaction() {
for level, tables := range v.levels {
var score float64
size := tables.size()
if level == 0 {
// We treat level-0 specially by bounding the number of files
// instead of number of bytes for two reasons:
//
// (1) With larger write-buffer sizes, it is nice not to do too
// many level-0 compaction.
//
// (2) The files in level-0 are merged on every read and
// therefore we wish to avoid too many files when the individual
// file size is small (perhaps because of a small write-buffer
// setting, or very high compression ratios, or lots of
// overwrites/deletions).
score = float64(len(tables)) / float64(v.s.o.GetCompactionL0Trigger())
} else {
score = float64(size) / float64(v.s.o.GetCompactionTotalSize(level))
}
if score > bestScore {
bestLevel = level
bestScore = score
}
statFiles[level] = len(tables)
statSizes[level] = shortenb(int(size))
statScore[level] = fmt.Sprintf("%.2f", score)
statTotSize += size
}
v.cLevel = bestLevel
v.cScore = bestScore
}
计算是否要compaction是逻辑是:计算一个分数,level 0是文件个数/4,level 0以上就是文件的总大小/预设的每个level的文件大小总量;最后找出算出的值最大的一个赋值到v.cScore,level赋值到v.cLevel
最终使用的时候是判断这个cScore是否>=1来决定是否要进行compaction
func (v *version) needCompaction() bool {
return v.cScore >= 1 || atomic.LoadPointer(&v.cSeek) != nil
}还有一个判断是v.cSeek是否为空,这个是读数据那边用到的。
参考文献
LevelDB源码:https://github.com/google/leveldb
LevelDB 功能与架构:https://www.jianshu.com/p/223f0c73ddc2
LevelDB详解:https://blog.csdn.net/linuxheik/article/details/52768223
LevelDB整体介绍:https://blog.csdn.net/charles1e/article/details/52966776
LevelDB介绍-随笔:https://blog.csdn.net/csds319/article/details/80333187
以太坊之LevelDB源码分析:https://blog.csdn.net/csds319/article/details/80361450
