
地址转换(Address Translation)负责将虚拟地址转换成物理地址,正因为有了这层转换,好多技术才可以发展起来,比如虚拟机、容器、沙盒等,其中的Page Table以及Cache(提高查找效率)的设计思想也被其他路由(查找)系统借鉴着。今天咱们就聊一下地址转换技术,先列举一些地址转换发挥作用的场景,让大家有一个直观感受:
- 虚拟内存,借助于地址转换,操作系统可以给应用程序一种假象,独占整个计算机内存,可以使用超过实际物理大小的内存,应用程序之间互不干扰。
- 进程隔离,地址转换可以用来构建沙盒(sandboxes)技术,让第三方代码在沙盒中运行,限制其对内存的访问,从而避免操作系统内核和应用程序受到病毒或者恶意代码的攻击。
- 进程间通信,地址转换可以将不同进程空间的地址映射到同一段物理内存,从而实现进程间通信。
- 共享代码段,动态加载so库可以在多个程序实例之间进行共享。
- 程序初始化,使用地址转换技术可以让应用程序只加载部分代码和数据就可以运行(后台继续加载剩余部分),若执行到未加载部分,则发生中断挂起应用程序,待操作系统内核将剩余部分加载到内存后再恢复应用程序的执行。
- 缓存管理,操作系统内核通过合理安排程序所在的内存位置来提高缓存效率。
- 内存映射文件,将文件内容映射到应用程序地址空间,这样一来,文件的内容就可以被应用程序直接访问。
先来一张图了解一下地址转换的概念
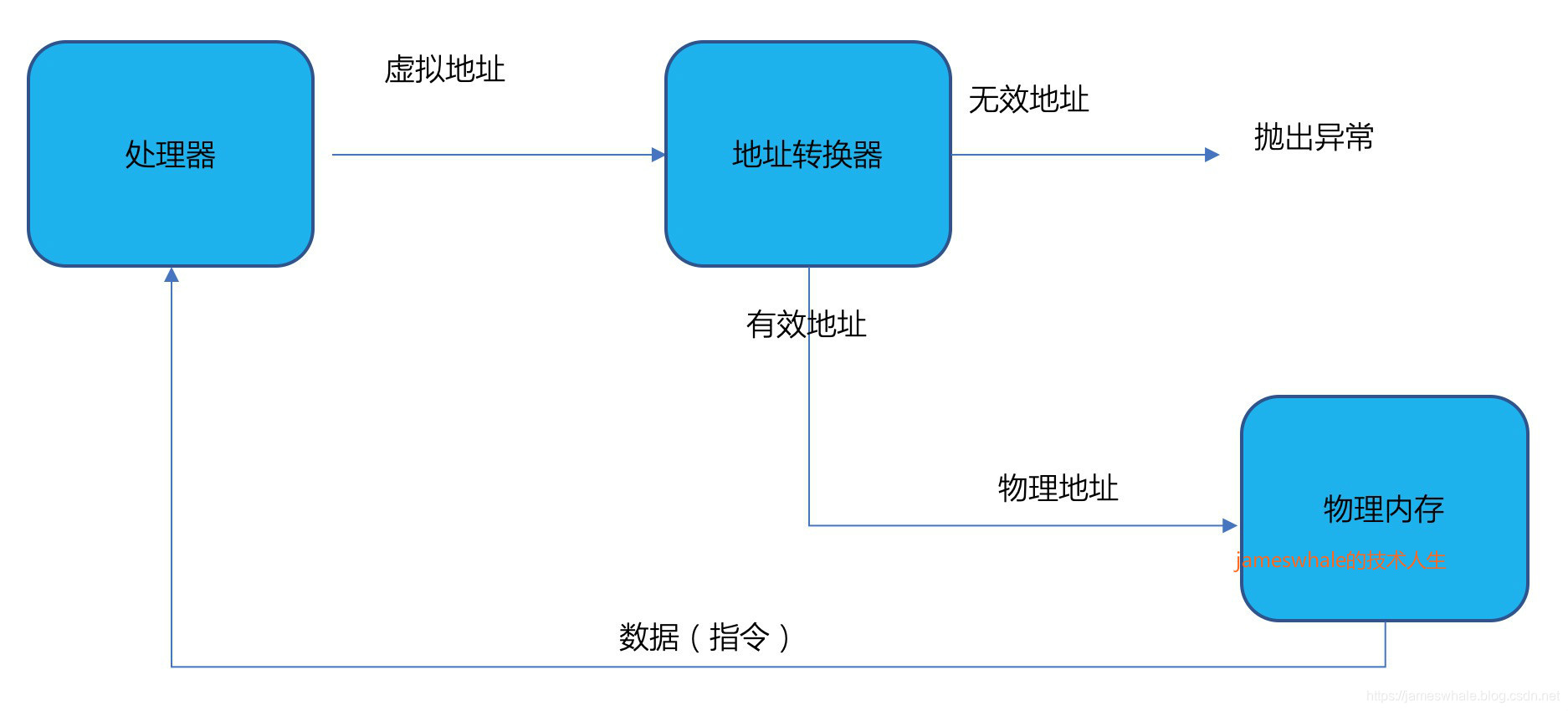
地址转换器需要实现的目标
- 内存保护,限制进程访问某些特定区域的内存,比如阻止进程访问不属于他的内存空间,阻止进程覆写其代码区域。
- 内存共享,允许多个进程共享某段内存区域,例如,同样的代码段或者公共库。
- 柔性内存布局,允许操作系统灵活的将一个进程的各个部分(代码,数据,堆,栈,内存映射文件等)放到内存的任何地方(在权限许可的情况下)。
- 运行时查找效率,若地址转换的耗时比执行指令本身还长,显然是不切实际的,指令提取和数据加载存储过程需要硬件的支持。
- 紧凑的转换表,地址转换需要的空间开销要远小于被管理的内存大小。
- 可移植性,不同的处理器硬件架构在协助实现地址转换的时候采用了不同的选择,操作系统内核需要适应多个处理器硬件架构。
内存的两种视角
- 虚拟地址,进程看到的内存地址为虚拟地址,他们不对应任何物理实体,每个进程有自己的地址空间。
- 物理地址,内存系统看到的地址为物理地址,他们用实际的地址去查找和存储内容。
地址转换器的实现方式
1. 最简单的硬件实现
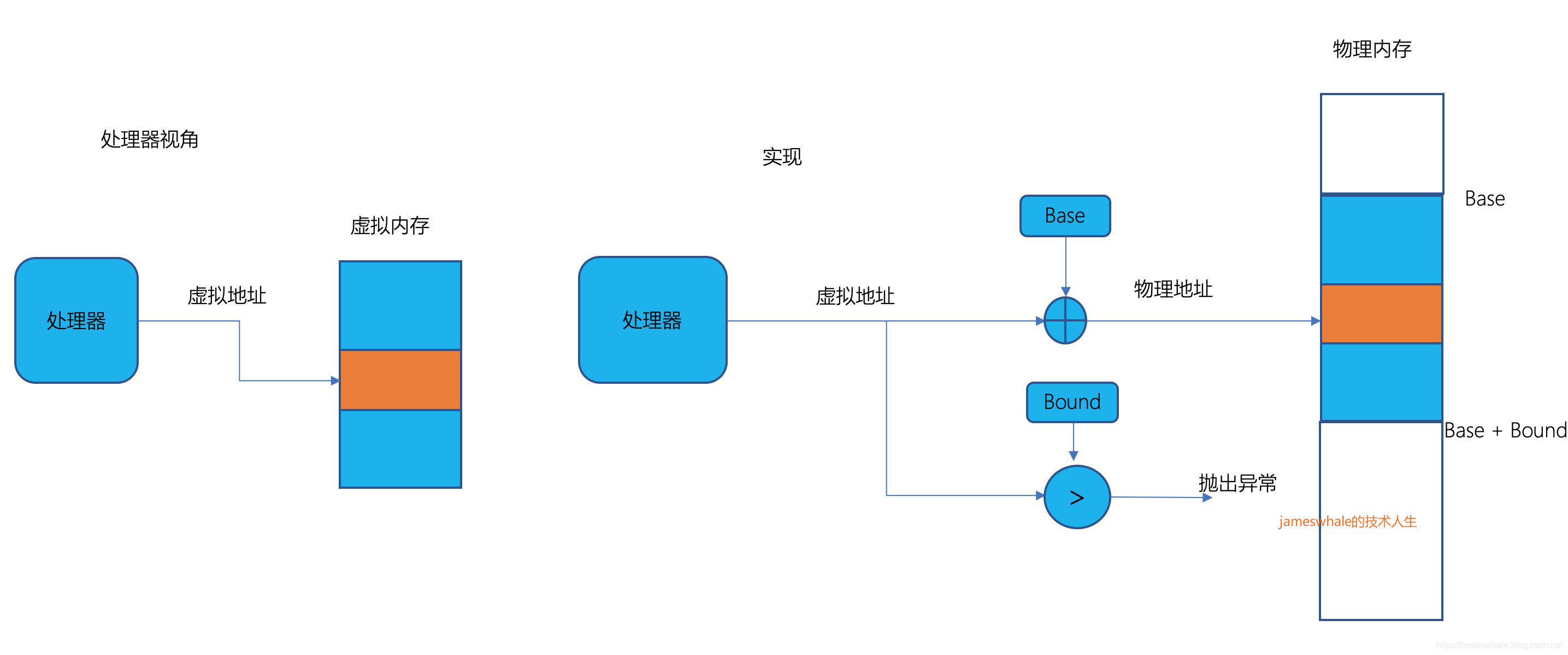
整个进程在一片连续的虚拟地址空间,这样每个进程只要两个寄存器,分别存放进程Base地址和进程Bound地址。
优点:
- 实现简单、地址转换效率高。
缺点:
- 只能提供粗粒度保护。
- 不能阻止程序覆写其代码段。
- 进程的虚拟内存和物理内存需要连续,无法支持实现动态内存管理,例如堆、线程栈、内存映射文件等特性。
2. 以段(Segment)为基础的内存

硬件为每个进程分配一组Base和Bound寄存器,每一对Base和Bound控制虚拟地址空间的一部分内存,称为段。每一段的虚拟地址空间是连续的,转换得到物理地址空间也是连续的,各个段之间不需要连续。
优点:
- 给不同的段设置不同的权限,例如,将代码段设置为只读。
- 进程的虚拟内存空间和物理内存空间可以分为若干段(图中画了四段),段与段之间不再需要连续。
- 两个进程之间可以通过设置相同的Base、Bound来共享代码段。
- copy-on-write,通过fork来创建子进程,一开始只复制父进程的Segment Table,不拷贝任何物理内存内容(除了栈内存),并将父子进程的Setment Table设置为只读,当子进程修改数据的时候产生中断,操作系统内核进行物理内存的实际拷贝。
- zero-on-reference,为防止敏感信息被恶意程序利用(例如,密码),在重新分配内存前,操作系统内核会先将内存清0,为了不必要的清0开销,只将堆的前几个KB清0,并用Bound标志0的边界,当程序不断动态分配堆、超过了Bound的边界,会发生中断挂起程序,操作系统内核将另外一部分的内存清0,然后恢复程序运行。
缺点:
- 因为各个段内存的大小不一样,管理他们的开销很大,且无法估计。
- 剩余内存区域的大小不一,为新进程寻找一块合适的内存较为麻烦,若找了一块小的,随着进程所需内存增长,会不够用,从而需要重新拷贝到一块更大的连续内存;若找了一块大的,则会浪费。
- 整个剩余内存空间很大,但是没有一块连续的空间可以满足新进程的内存分配。虽然操作系统可以进行内存压缩,但是会增加系统的负担。
3. 以页(Page)为基础的内存
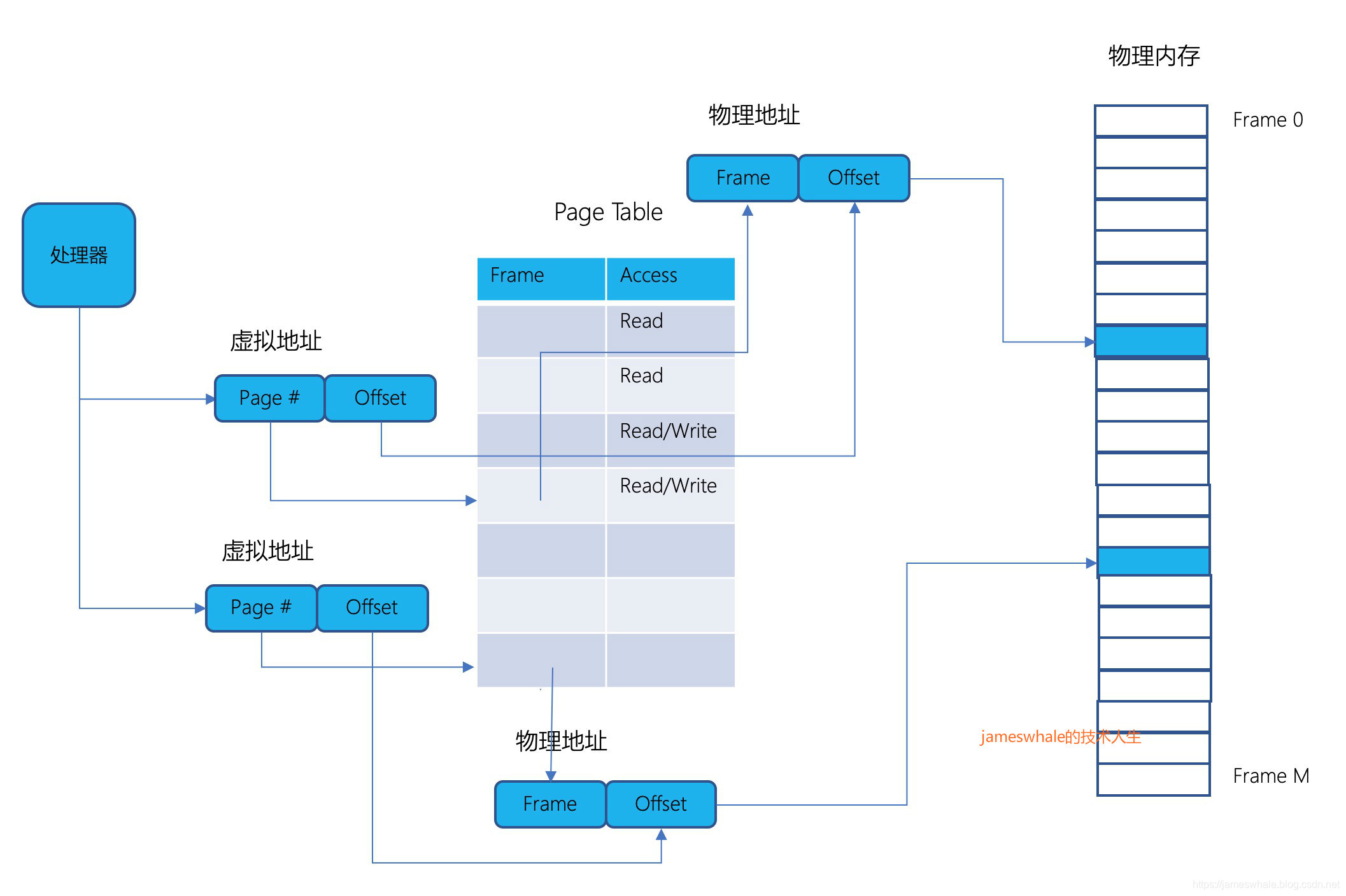
内存以固定大小块作为分配单位,称之为页帧(Page Frame)。Segment Table里的元素指向的是大小不一的段,Page Table里的元素指向的是固定大小的Page Frame,因Page Frame一般是2的指数,所以Page Table里的元素只需提供Page Frame地址的前面一段bit位信息,不需要Bound信息,物理内存以Page Frame作为分配单元。
优点:
- 虚拟地址空间是连续的,物理地址空间可以不用连续(同一个Frame里面的地址是连续的),例如,当前Page的最后一条指令(数据)的地址和下一个Page的第一条指令(数据),其虚拟地址是连续的,但是物理地址可以相隔很远。
- 内存分配方便很多,可以用一个bitmap来表示物理内存的分配情况。
- 可以很方便的在多进程间共享物理内存,只要让Page Table里的元素指向同样的Frame 即可。
- 和Segment分配机制一样,可以实现copy-on-write, zero-on-reference。
- 将程序的部分代码和数据加载进来,就可以让程序运行,然后操作系统内核在后台继续加载程序的其他部分,若程序指令正好跳到未加载的部分,则产生中断挂起程序,待操作系统内加载完成后恢复程序运行。
缺点:
- 虚拟地址空间的管理变得复杂(物理地址空间的管理变得简单)。
- Page Frame的大小选择,若大了,当进程用不完Frame内的内存,则会造成浪费。若小了,则会造成Page Table的开销过大。举例,16KB大小的Page Frame,64位的虚拟地址空间,需要2^50 个Page Table元素,假设每个元素4个字节,累计需要4PB的空间,显然不现实。
4. 多层级转换
单纯通过一层Page Table进行地址转换,开销较大,可以采用多层转换来减少开销。
1) 段表+单层页表
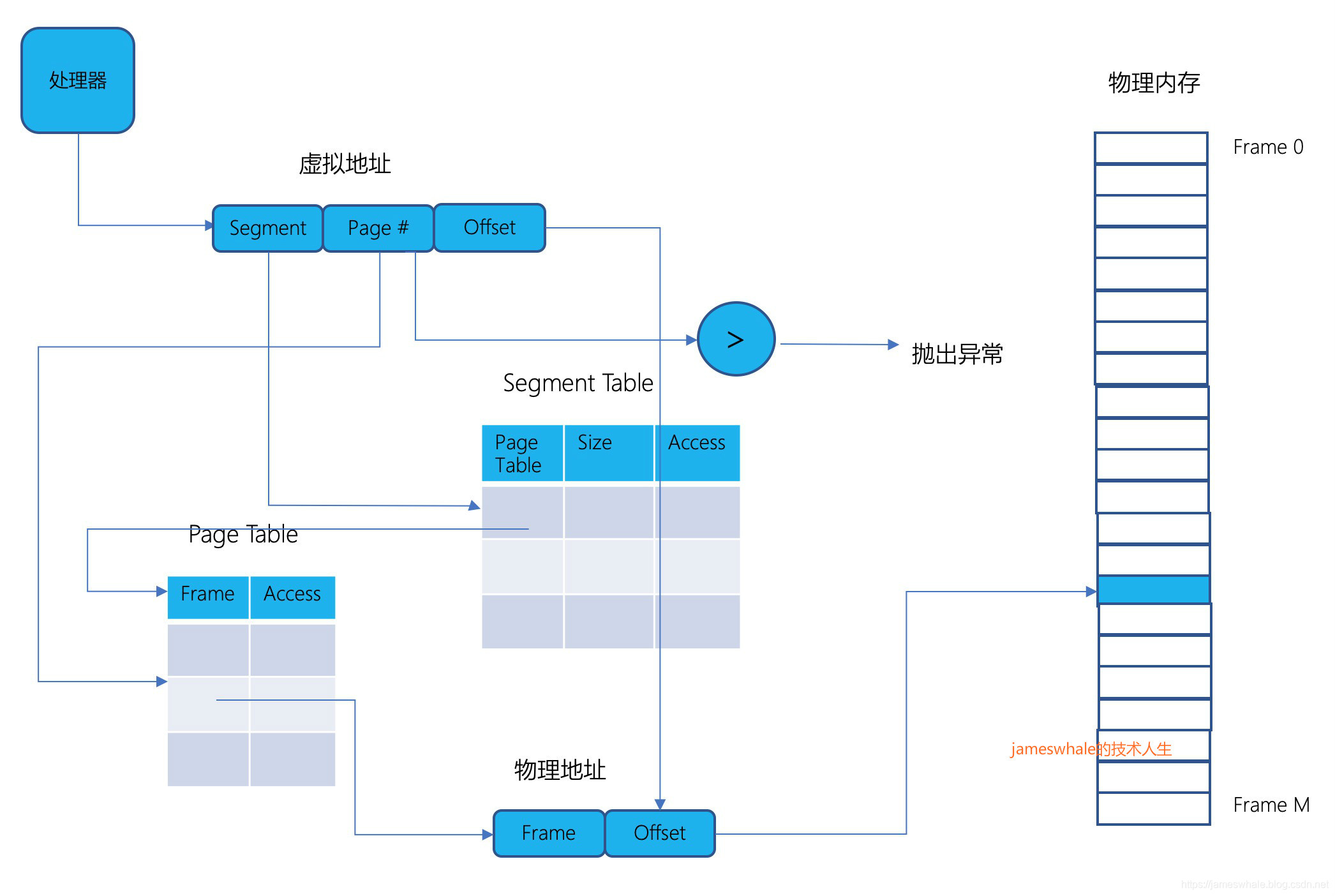
进程的内存,先分成多个段,每个段再按照页来分配。地址分三个部分,段号+页号+页内偏移,根据段号去段表里面找对应的页表地址,得到页表的地址后,根据页号找到对应的物理内存的Page Frame地址,最后再结合页内偏移计算得到实际地址,其中段表中的Size是指某一段对应的页表的长度,即物理页的数目。以32位虚拟地址空间,4KB大小的Page为例,前10bit用于段号,中间10位用于页号,后12位用于页内偏移,假设页表的每一行的大小是4个字节,则一个物理Page Frame正好可以容下每个段的页表。
2)多层页表
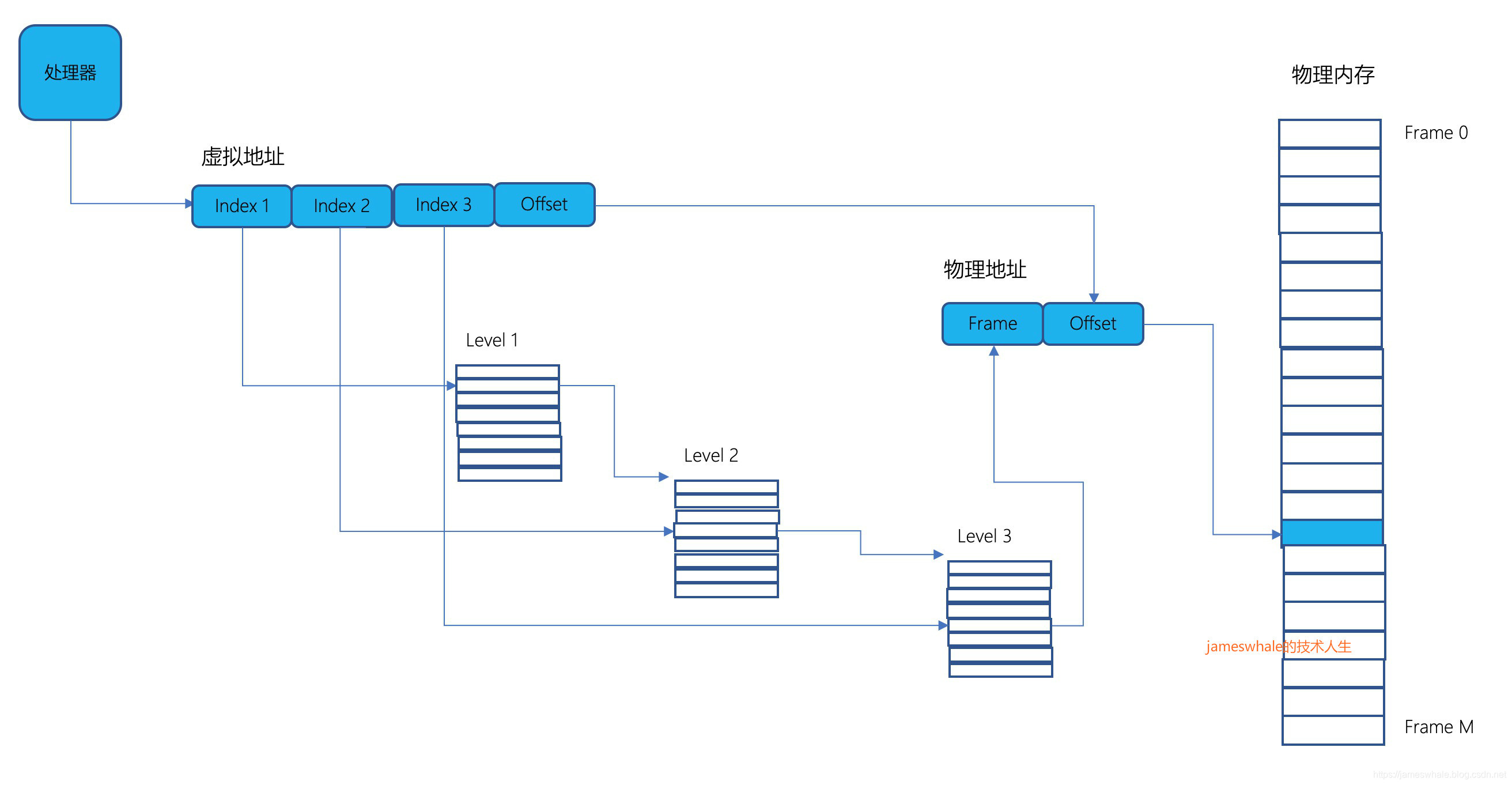
3层页表,虚拟地址由四部分组成:每个层级页表的索引以及物理页内的偏移。Sun Microsystems SPARC处理器采用此种转换结构,每一层页表被设计成可以在一个物理页存放。只有顶层的页表是需要被填满的,其他层级的页表只有用到了才会分配,可以在每一层设置访问和共享情况。
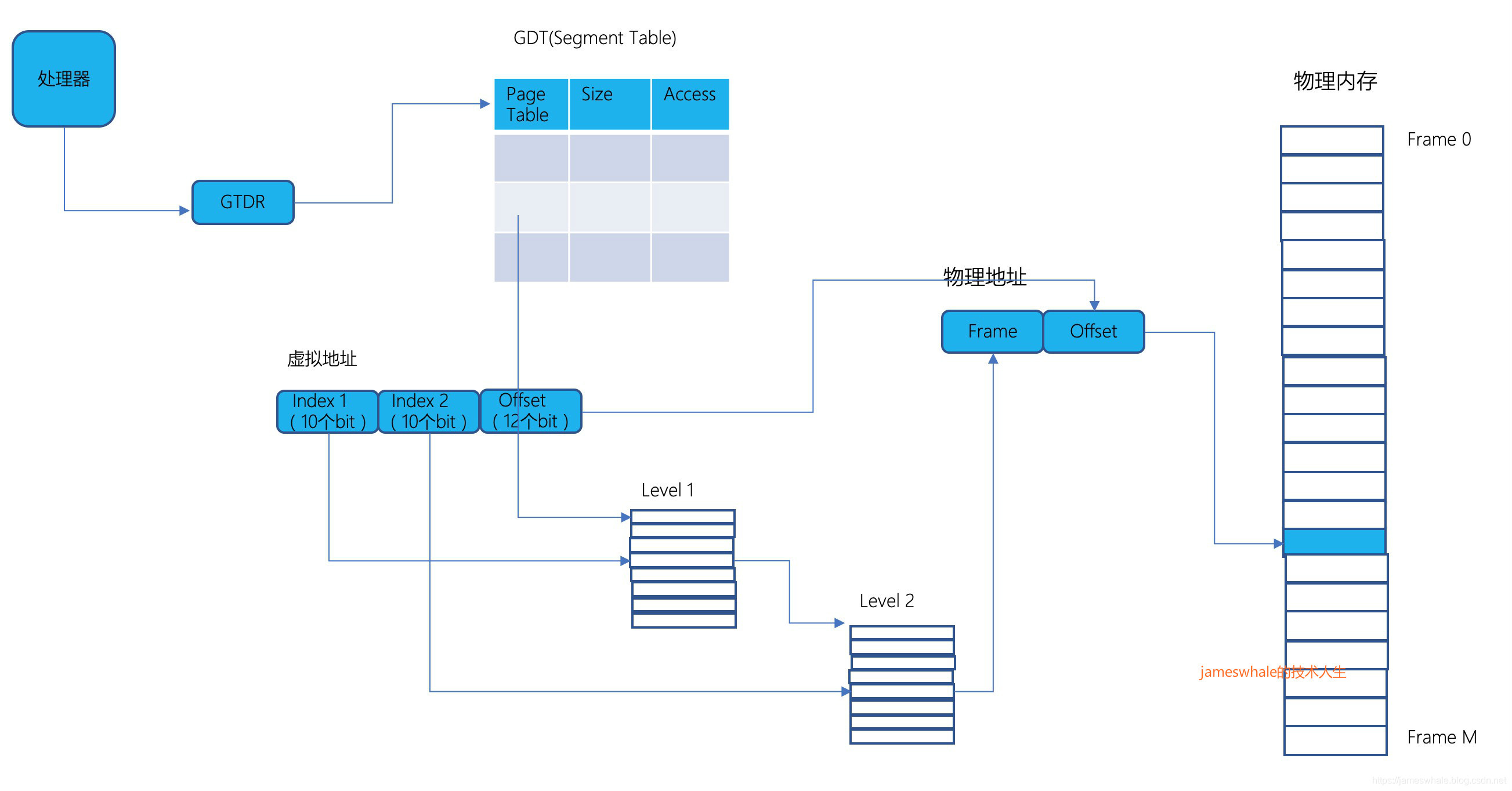
3)段表+多层页表
X86体系处理器采用了此种转换结构,包括32位和64位地址模式。X86给每个进程分配一个GDT(Global Descriptor Table,相当于一个段表),每个元素包含某一个多层页表的地址和对应的长度。每个进程只用少量的段,所以段表会非常小,对段表的索引是隐含在指令里面的,比如push、pop则去栈段,分支指令则对代码段等,不需要bit位去索引。
- 32位X86,虚拟地址空间通过一个段表(段表不需要bit位索引)和2层页表进行转化,前10个bit位用于索引第一层页表,中间10个bit位用于索引第二层页表,后12位是Page Frame内的偏移。每个页表的元素占用4个字节,页大小是4KB,一个物理页可以容纳第1层级页表和第二层级页表,第二层页表的个数取决于所属段的长度(即第一层页表的元素的个数)。
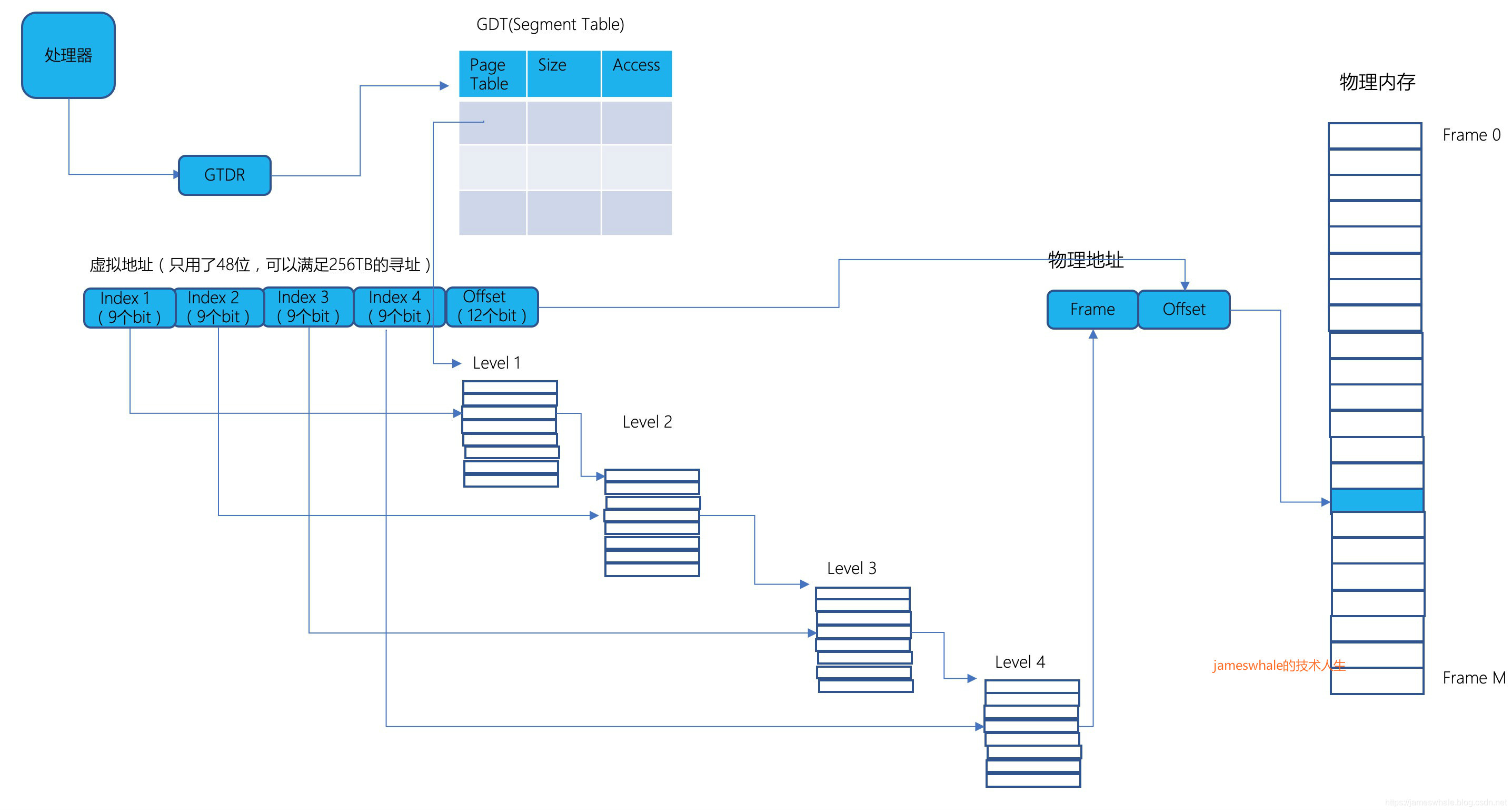
- 64位X86,虚拟地址空间可以延伸到64位,为了简化地址转换,当前很多处理器只用了48位(前16位没有使用),能够满足256TB的内存空间使用,采用段表和4层页表进行转换(9个bit位+9个bit位+9个bit位+9个bit位 + 12个bit位,段表不需要bit位索引,前4个9bit位分别用于4层页表的索引,最后一个12bit用于页内偏移,总计48bit位),只有第一层页表是被填满的,其他三层页表只有对应虚拟空间地址被使用了才会被填充。为了优化,64位X86可以消除1个或者2个层级的页表。每个物理页的大小是4KB,第4层级的页表可以管理2MB,第3层级的页表可以管理1GB的数据,若操作系统分配了连续的2MB物理页,则可以省去第4层级的页表,让第三层的页表元素直接指向2MB的物理页,同样的,若操作系统分配了连续的1GB物理页,则可以省去第3、4层级的页表,让第2层级页表的元素直接指向1GB的物理页。这样做既可以节省页表存储的开销,还可以提高地址转换效率。
提高转换效率的方法
上面提到的多层级页表访问,若都是在内存里面的话,单是将虚拟地址转成物理地址就需要2~4次物理内存访问,这要比执行一条指令的耗时高很多,显然是不切实际的。下面讲一下有哪些措施可以提高转换效率。
1. TLB(Translation lookaside buffer)
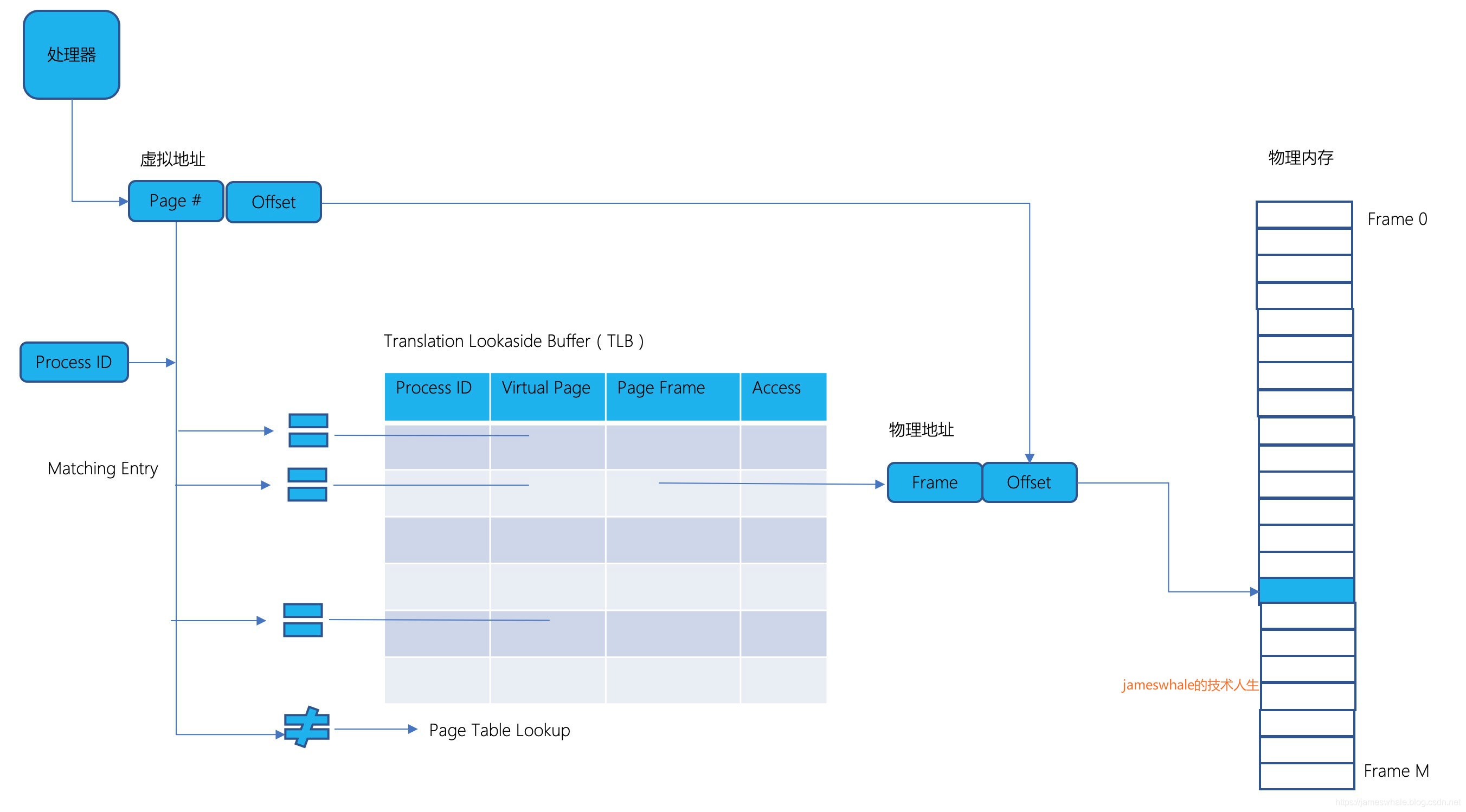
TLB通常和处理器在一起,查找速度非常快,包含多级TLB。Virtual Page Number(以64位X86为例,是36bit位,4层页表的索引)和TLB中所有的元素同时进行比较,若匹配,则得到对应的Physical Page Frame Number以及对应的访问权限,若没有匹配,则按照段表+多层页表的方式去重新查找,找到后将转换结果保存到TLB(若已满,则按照一定策略进行替换)。
tagged TLB entry = {
process ID,
virtual page number,
physical page frame number,
access permissions
}
TLB通常和处理器在一起,查找速度非常快,包含多级TLB,第一级TLB容量小、速度快,第二级TLB容量大、速度相比第一级慢一些。
2. Superpages
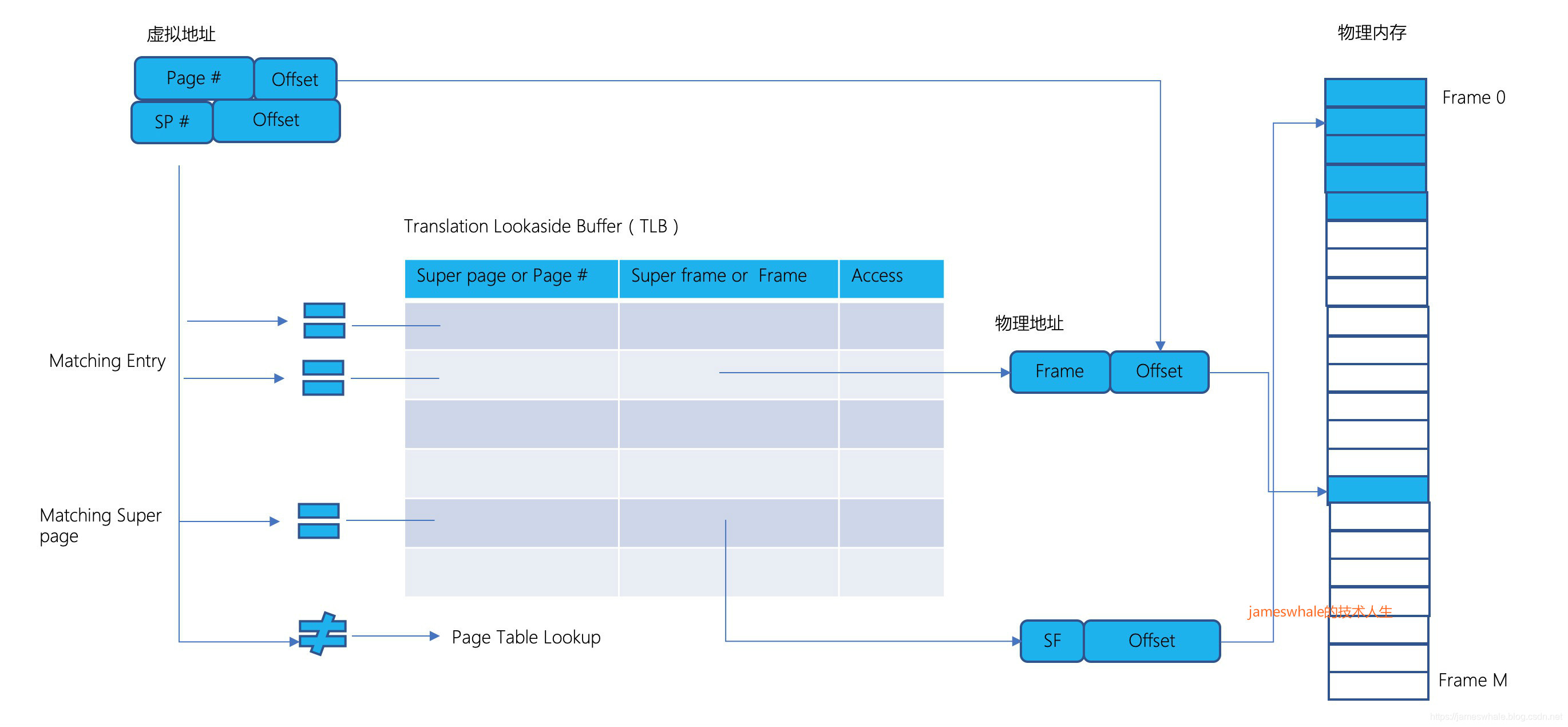
TLB查询速度很快,提高TLB的命中率可以有效的提高地址转换效率。超级页面是物理内存中映射虚拟内存中相邻区域的一组相邻页,例如,一个8 KB的超级页将由两个相邻的4 KB页组成,这两个页位于虚拟和物理内存中的8 KB边界上。超级页面要求系统分配不同大小的内存块,从而使操作系统内存分配复杂化。不过,这样做的好处是,超级页面可以大大减少映射大型连续内存区域所需的TLB条目数量。TLB中的每个条目都有一个标志,表示条目是页面还是超级页面。
举例,以64位X86为例(只用了48位,最高16个bit没有使用),正常的Virtual Page Number是36位(4层级页表索引,各9位),页内Offset是12位。若有一个2MB的超级页,则此超级页的Virtual Page Number 是前面27位(4层级页表变成3层级页表,略掉最后一层级的页表),超级页内Offset是低21位。若有一个1GB的超级页,则此超级页的Virtual Page Number是前面18位(4层级页表变成2层级页表,略掉最后2层级的页表),超级页内Offset是低30位。
超级页的使用场景包括高分辨率视频帧的处理、巨型矩阵的科学计算等等,整个Frame Buffer可以用一个TLB Entry来映射,从而空出更多的TLB Entry给其他地址转换使用。
3. 缓存虚拟地址以及对应的内容
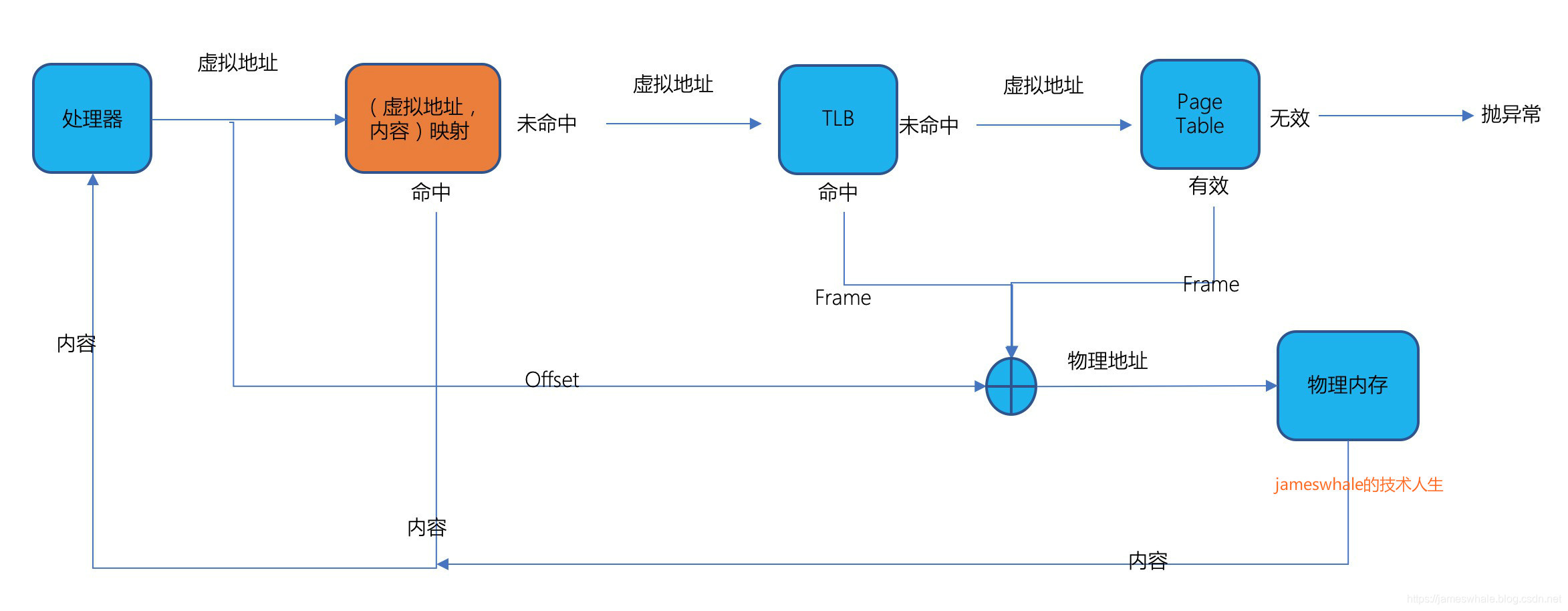
另外一个提高地址转换效率的方法是,将虚拟地址以及对应的物理内存内容缓存起来,在TLB查找之前先去这个缓存进行查看,若匹配的话,则直接将对应的内容给到处理器,省去了很多地址转换以及内容提取的过程。现代多核处理器给每个核都配备了这样一个芯片上缓存,这个缓存分成两部分,一部分用于指令,一部分用于数据。
4. 缓存物理地址以及对应的内容
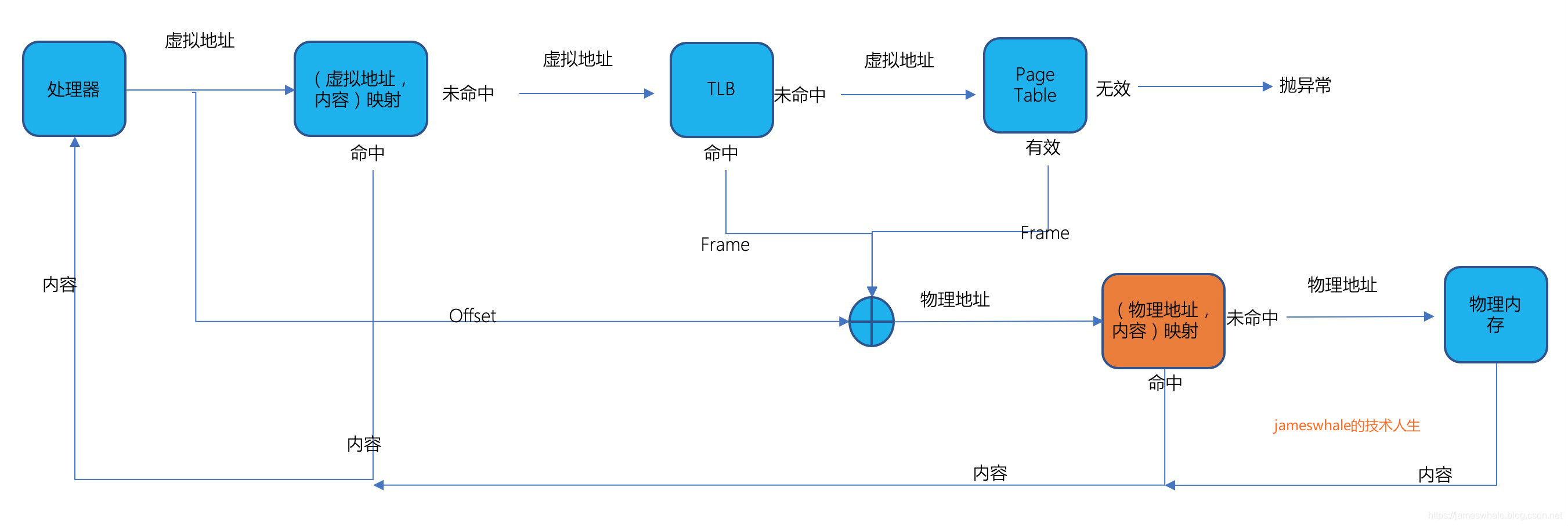
许多处理器架构会在虚拟地址Cache和TLB之后设置一个物理地址Cache,保存物理地址和对应内容的映射,当经过TLB或者硬件Page Table转换后得到对应的物理地址,先去这个Cache查询,若匹配得上,则直接获取其中的内容,免去了一次物理内存的访问,加快了内容的访问速度。现代处理器给每个核配备了一个物理地址Cache,典型的大小是256KB,为整个处理器配备了更大的物理地址Cache,典型大小是2MB,当第一个Cache没有命中,则去第二个Cache去访问,若都没有命中,则去物理内存访问。
总结
上面重点讲了地址转换的实现方式,从最简单的Base+Bound 到X86处理器体系的段表+4层级页表,同时为了提高转换效率,也介绍了各种Cache思想,包括TLB、虚拟地址Cache、物理地址Cache等。有了Cache之后,随之而来的是Cache和源内容一致性问题,后面再单独讨论一下这个问题。
文章首发于微信公众号【jameswhale的技术人生】,因精力有限,会不定期将文章同步到CSDN博客。
