《流畅的Python》学习笔记(4) —— 字典、集合与哈希
摘要:字典是Python中编程中最常用到的数据结构之一,由于其方便的接口和检索的高效性,在NLP编程中常常用来构建和存储词表,完成word2int和int2word等的功能。因此,有必要深入的研究一下字典这个结构。
1. 字典的构建方法:字典推导
和列表推导类似,字典推导的方法格式为:
reduced_dict = {key: value for key, value in ...}
这个方法非常好用,尤其在已知键值各自的数组,例如:
(1)已知两个一一对应的分别代表键和值的的列表,构建一个字典
keys = ['a', 'b', 'c', 'd']
values = list(range(len(keys)))
reduced_dicts = {key: value for key, value in zip(keys, values)}
(2)已知一个字典是一一映射的,如何构建一个反映射,在NLP中为已知word2int,如何知道int2word
word2int = {...}
int2word = {word2int[key], key for key in word2int}
2.字典的增删改查优化
日常业务中,其实使用最多还是增删改查的功能,首先考察Python的内置字典的一些方法,而后在活用或者改造这些方法完成我们所需要的增删改查功能
2.1 三种字典的内置方法
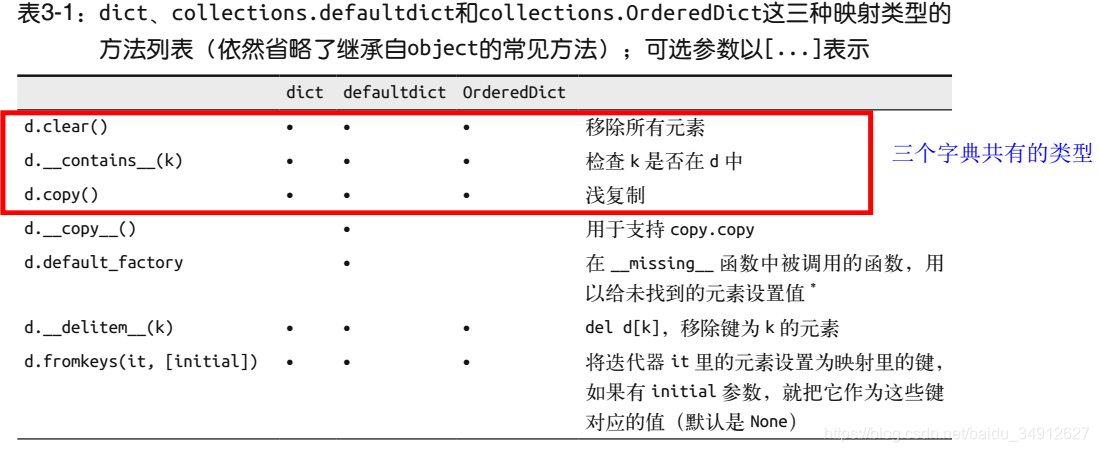

摘自《Fluent Python》
其中比较常用的方法有:
- d.values(), d.keys(),这两个方法以一种内存视图的方式返回键和值的对象,占用资源较少
- d.items()是返回键值对的
- d.setdefault
2.2 可靠的查询、修改
较为熟练的Python程序基本上都知道用d.get(key, default_value)来替换d[key],原因可以减少使用try expect语句,更加简单、高效地解决问题。但是这还不够,d.get()不能够用在修改键值对上。例如:
"""创建一个从单词到其出现情况的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
# 这其实是一种很不好的实现,这样写只是为了证明论点
occurrences = index.get(word, []) #1
occurrences.append(location) #2
index[word] = occurrences #3
# 以字母顺序打印出结果
for word in sorted(index, key=str.upper):
print(word, index[word])
这个方法可以解决修改未出现的键的问题,但是存在两个个问题:
- 需要三行实现修改的功能,过于冗长
- 在修改的过程中访问了两次内存一次是1,一次是3
为解决这些问题我们可以有若干方法:
(1)setdefault方法,默认修改为某值
"""创建从一个单词到其出现情况的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index.setdefault(word, []).append(location) ➊
# 以字母顺序打印出结果
for word in sorted(index, key=str.upper):
print(word, index[word])
这里使用的是setdefault方法来解决,当index不存在word这个键时,将index[word] = default
但这个方法就割裂了查找和删除的接口,会用到setdefault这个不常见的方法。
(2)弹性键查询方法
弹性键查询方法,是指当某个键的映射不存在的时候,我们希望通过这个键获取一个默认的值
目的是获得了一个统一的接口,如index[k].append(value)可以不出现错误的直接使用,有两种方法,一个是使用default_dict,另一个是使用__missing__方法重写
- 利用default_dict的方法是
"""创建从一个单词到其出现情况的映射"""
import sys
import re
import collections
WORD_RE = re.compile(r'\w+')
index = collections.defaultdict(list) ➊
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index[word].append(location) ➋
# 以字母顺序打印出结果
这样就能达到要求,但值得注意的是:defaultdict的方法只会在__getitem__中调用,其他调用,在其他的方法中如d.get()中不会调用。
- __missing__方法发调用
在defaultdict中,其实当出现键值问题时,则调用__missing__方法
class StrKeyDict0(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys()
这是一种继承与dict类的变种类,更好的方式是继承Userdict,这样能够写出更优美的代码。
3 哈希与效率的问题
可以看到,字典这种类型的使用方式一般是:一次建立,多次查询的;所以查询的效率需要重点考察。而为了弄清楚是字典的效率就必须了解背后的算法原理。在Python中字典的实现方法是通过Hash表的方法。
大致的工作流程如:
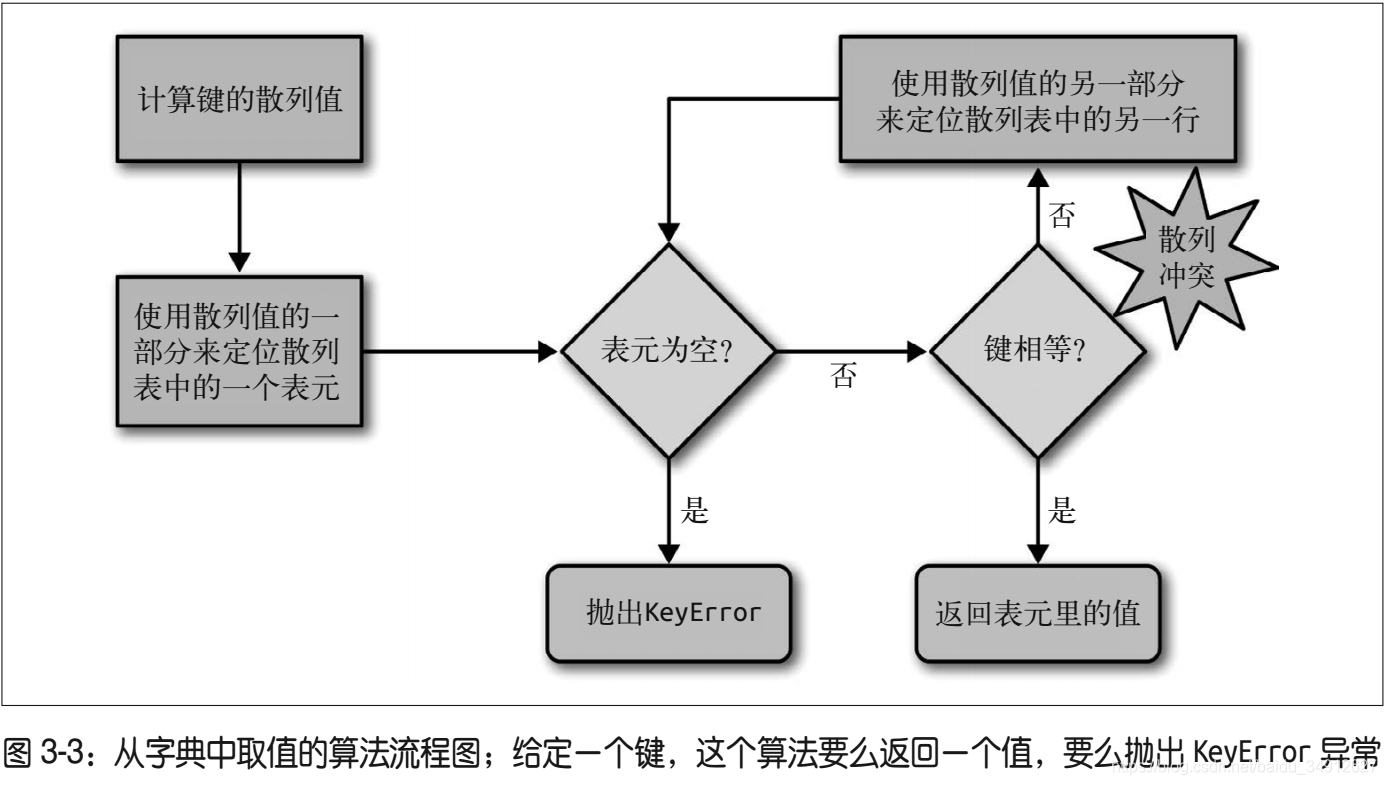
既然使用了Hash算法,则由如下几个特点:
- 键需要是能Hash的类型,基本上要是不可变类型如元组(由不可变的内容组成),字符串,
- 内存资源消耗很大,是实际需要内存的3/2
- 查询速度很快,基本上不随着数据量的增大,是O(1)级别
- 增添和删除字典,可能会导致内存的迁移
