什么是机器学习?
在我们刚出生时,可以说我们对周围的事物一无所知,当我们第一次吃完苹果和梨后,下次吃时并不能分辨出两种水果的种类,但当我们吃过很多次后,再见到苹果和梨我们就能轻易地判断出来。
机器学习简单来说可以理解成计算机认知的过程,但是计算机认知过程和人类认知过程有本质性的区别,人类是通过一次次不断实践来认知事物的,而计算机则是通过把大量无序的数据转换成有用的信息后总结出规律然后得出结论。简单的一句话:机器学习就是让机器从大量的数据集中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好。
k-近邻算法:
k-近邻算法就是采用测量不同特征值之间的距离进行分类,其实本质就是我们初中学的两点间距离
举一个二维的例子:
比如我们用一条小狗每天的摄入量与睡觉时间来判断一条小狗是胖狗还是瘦狗,在判断之前,我们必须要有一定数量的样本来作为依据
设小狗a每天摄入1.5g食物,睡8小时,是瘦狗,即(1.5, 7, ‘yes’)
小狗b每天摄入1.6g食物,睡9小时,是瘦狗,即(1.7,, 9, ‘yes’)
小狗c每天摄入2.3g食物,睡12小时,是胖狗,即(2.3, 12, ‘no’)
小狗d每天摄入2.5g食物,睡10小时,是胖狗,即(2.5, 10. ‘no’)
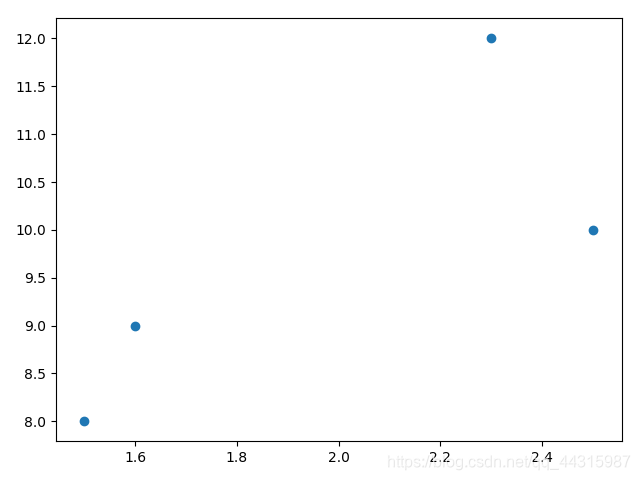 现在我们用k-近邻法来判断小狗e(2.4, 11)是胖狗还是瘦狗
现在我们用k-近邻法来判断小狗e(2.4, 11)是胖狗还是瘦狗
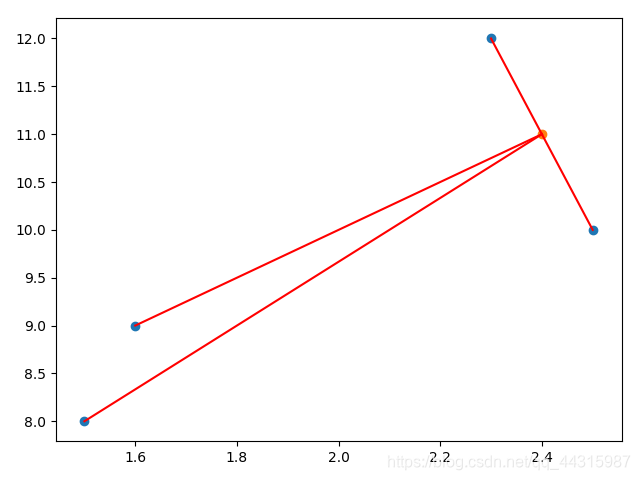 k为离目标点距离最近的点的数目, 这里我们选定k = 2,由图可知,离目标点e最近的两点为c点和d点,而c、d都是胖狗,所以e也是胖狗
k为离目标点距离最近的点的数目, 这里我们选定k = 2,由图可知,离目标点e最近的两点为c点和d点,而c、d都是胖狗,所以e也是胖狗
k-近邻算法的流程
1.此时算法
2.准备数据
3.分析数据
4.测试算法(计算错误率)
5.使用算法
python实现k-近邻算法
import numpy as np
import operator
class kNN():
def createDataSet(self): # 创建数据集
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
lables = ['A', 'A', 'B', 'B']
return group, lables
def classify0(self, inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # 样本数
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 对inX的行重复dataSetSize次,列重复一次
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort() # 返回排序后的下标
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] # 取得距离最短的前k个样本的标签
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 对应标签的样本数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 对标签书倒序排序
return sortedClassCount[0][0]
测试
if __name__ == '__main__':
inX = [0, 0]
c = kNN()
group, lables = c.createDataSet()
print(c.classify0(inX, group, lables, 3))
>>>B
实例:利用k-近邻算法实现约会网站的配对
我们通过三个属性:每年获得的飞行常客里程数, 每天花在游戏和视频上的百分比, 每周消费的冰淇淋公斤数来判断对一个人的好感度’not at all’, ‘in small doses’, ‘in large doses’
数据集:
百度网盘链接
提取码: zkf7
从文本文件中解析数据:
def file2matrix(self, filename): # 文件操作
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 3)) # 初始化矩阵
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3] # 填充矩阵
classLabelVector.append(int(listFromLine[-1])) # 标签向量
index += 1
return returnMat, classLabelVector
分析数据
def dataVisible(self, datingDataMat,datingLabels):
fig = plt.figure(figsize=(5, 4), dpi=500)
ax = fig.add_subplot(111) # 1×1网格的第一个图
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0*np.array(datingLabels), 15.0*np.array(datingLabels)) # 第三个参数是尺寸,第四个参数是色彩
plt.show()
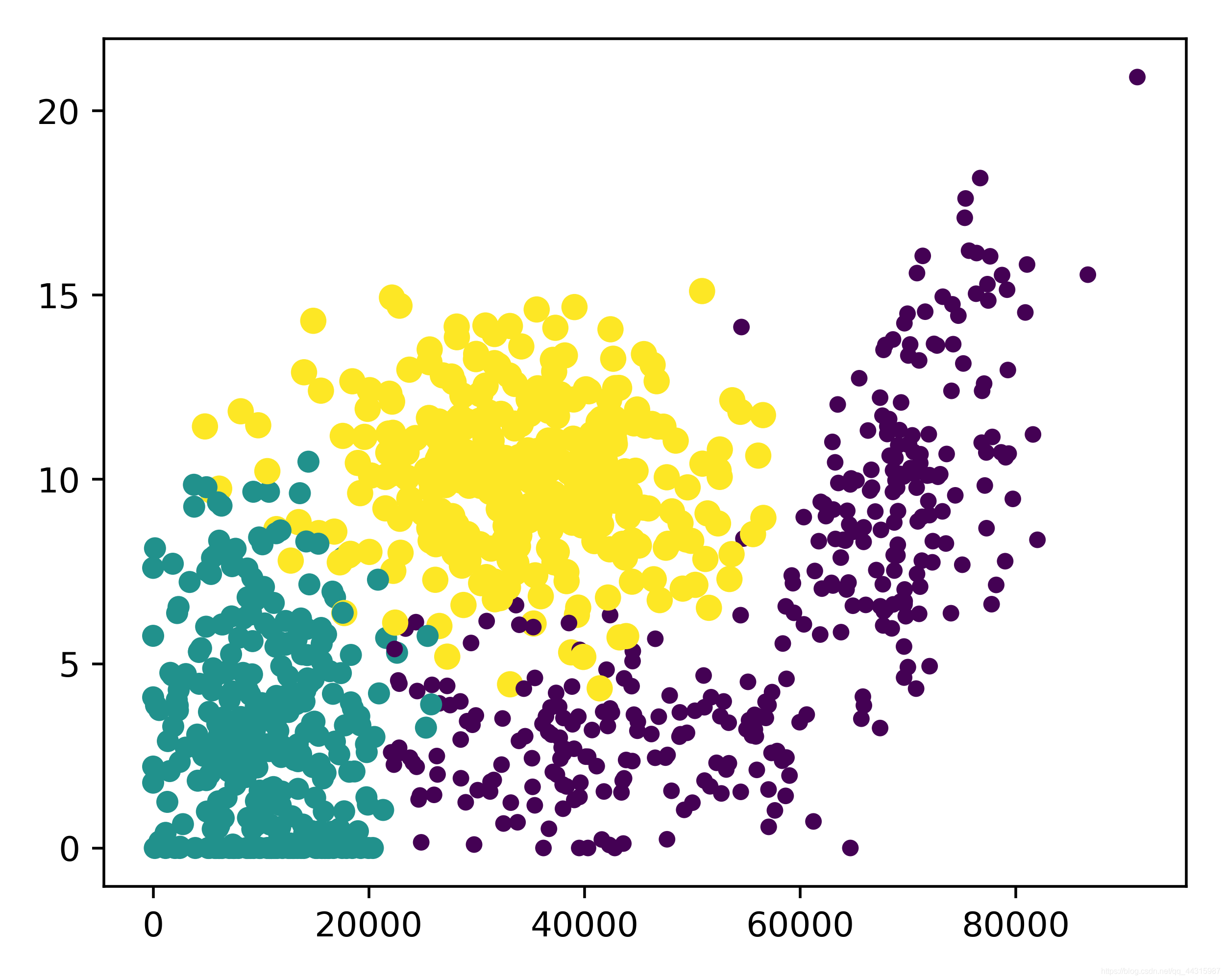 归一化数值
归一化数值
由于数字差直大的属性对计算结果影响大,所以需要将数据归一化
newValue = (oldValue - min)/(max - min)
def autoNorm(self, dataSet): # 归一化new = old - min/max - min
minVals = dataSet.min(0) # 每列最小的元素
maxVals = dataSet.max(0) # 每列最大的元素
ranges = maxVals - minVals
# normDataSet = np.zeros(dataSet.shape) # 初始化矩阵
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (m, 1)) # old - min
normDataSet = normDataSet / np.tile(ranges, (m, 1)) #old - min/max - min
return normDataSet, ranges, minVals
测试算法,计算错误率
def datingClassTest(self): # test
hoRatio = 0.10 # 抽取百分之十的样本作为测试集
datingDataMat, datingLabels = self.file2matrix('/home/cxd/下载/machinelearninginaction/Ch02/datingTestSet2.txt')
normMat, ranges, minVals = self.autoNorm(datingDataMat) # 归一化
m = normMat.shape[0] # m组样本
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = kNN().classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3) # 前百分之十作为测试集
print('分类结果是 %d ,正确答案是 %d ' % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i] : errorCount += 1.0
print('总的错误率是: %f' % (errorCount/float(numTestVecs)))
使用算法
def classifyPerson(self):
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(input('pecentage of time spent playing video games?'))
ffMiles = float(input('frequent flier miles earned per year?'))
iceCream = float(input('liters of ice cream consumed per year?'))
datingDataMat, datingLabels = self.file2matrix('/home/cxd/下载/machinelearninginaction/Ch02/datingTestSet2.txt')
normMat, ranges, minVals = self.autoNorm(datingDataMat)
inArr = np.array([ffMiles, percentTats, iceCream])
classifierResult = kNN().classify0((inArr - minVals)/ranges, normMat, datingLabels, 3)
print('You will probably like this person:', resultList[classifierResult - 1])
结果:
if __name__ == '__main__':
a = Appointment()
a.classifyPerson()
>>>
pecentage of time spent playing video games?10
frequent flier miles earned per year?10000
liters of ice cream consumed per year?0.4
You will probably like this person: in small doses
