刚刚装好一切配置,手头杂活快速清理了来迎接cuda入门的抽打······
pytorch是一个Python科学计算包,它的主要受众是两类人:
- 想找个numpy的替代品,好利用GPU的强大的人
- 找个最灵活最快速的深度学习平台的人
文章目录
查看pytorch和 对应cuda版本
import torch
print(torch.__version__) #注意是双下划线
1.3.1
print(torch.version.cuda)
10.1
查看自己安装 的cuda版本
C:\Users\Administrator>nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Wed_Oct_23_19:32:27_Pacific_Daylight_Time_2019
Cuda compilation tools, release 10.2, V10.2.89
torch.Tensor
tensor, 张量, 和numpy的ndarray很像,不同的是tensor可以用于GPU加速。是一个支持自动梯度操作的多维数组
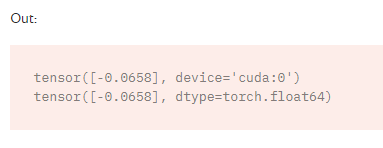
用torch创建张量,在cpu或者gpu,Tensors can be moved onto any device using the .to method.
y = torch.ones_like(x, device=device) # directly create a tensor on GPU
x = x.to(device) # or just use strings ``.to("cuda")``
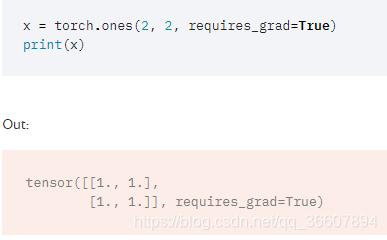
torch.Tensor是pytorch包的核心类。如果把张量的属性.require_grad设置为True(默认False),则所有操作(加减乘除,函数等任何运算)的梯度都会被追踪,只要调用.backward()方法就可以自动计算出所有的梯度。这个张量的梯度会被累加到.grad属性中。
调用.detach()方法就可以阻止张量追踪所有计算历史和将来的计算操作。还可以把代码块包在with torch.no_grad()中,也能阻止张量去追踪历史(毕竟追踪历史是要使用内存的),当验证和评估模型性能的时候这样做特别有用,代码块里面的张量的属性.require_grad是True也不会追踪。
一般追踪操作历史都是为了后面反向传播计算梯度,所以测试阶段不需要反向传播就不用追踪了。
backprop
如果想计算tensor的导数就直接对它调用.backward()方法,但是需要传入一个tensor参数说明shape.(如果tensor是标量则不用传了)

举例
从x计算得到out的过程:

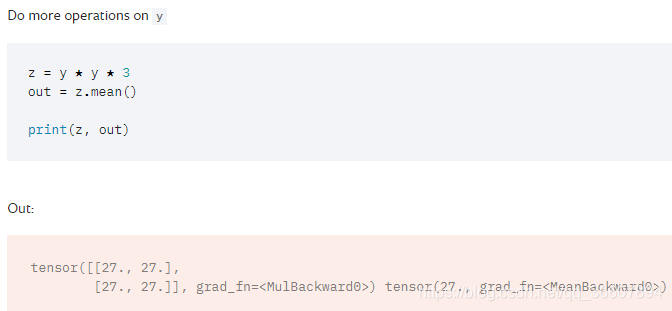
对out执行.backward()方法,求出out关于从x到out的所有中间变量的导数,x.grad就是out关于x的导数

如果函数的输入输出都是向量,则反向求导得到的就是一个雅克比矩阵了
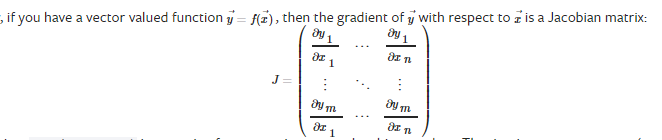
Function类
对于自动梯度autograd的实现,除了torch.Tensor之外的一个很重要的包是Function.
Tensor 和 Function包是有联系的,他们一起组建成了一个不循环的计算图,把完整的计算历史都编码记录了。
每个tensor都有一个属性.grad_fn, 是创建出这个tensor的函数,如果tensor是用户定义的,这个属性则是None.
autograd
pytorch中所有神经网络的核心就是autograd包。它提供了tensor上所有操作的自动求导。
It is a define-by-run framework, which means that your backprop is defined by how your code is run, and that every single iteration can be different.
torch.nn
用这个包构建神经网络
nn依赖于autograd来定义模型和求导。
nn.module()方法包含神经网络所有的层和一个方法forward()。只需要自己写写forward函数,backward函数用autograd实现。
神经网络的典型训练流程:
- 定义一个有可学习参数的网络
- 通过网络处理输入
- 计算损失(how far is the output from being correct)
- 反向传播,计算所有参数的梯度
- 更新参数,典型更新准则(梯度下降)weight = weight - learning_rate * gradient
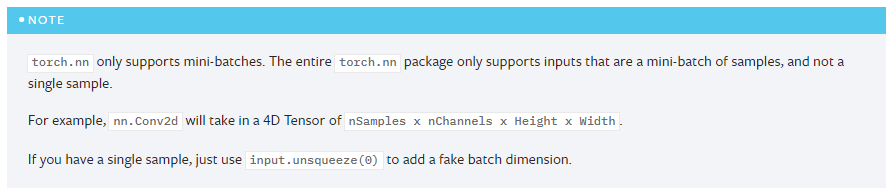
torch.nn只支持mini-batch,不可以用a single sample。
损失函数
损失函数的输入是target,output对,pair,损失函数计算出一个值来估计输出和target的距离
nn.MSELoss
调用loss.backward()则整个计算图都会关于损失求导,实现error的反向传播
torchvision
专为视觉任务设计,里面有常见数据集比如 Imagenet, CIFAR10, MNIST的数据载入器data loader(torchvision.datasets);还有图像的转换器transformer(torch.utils.data.DataLoader.)
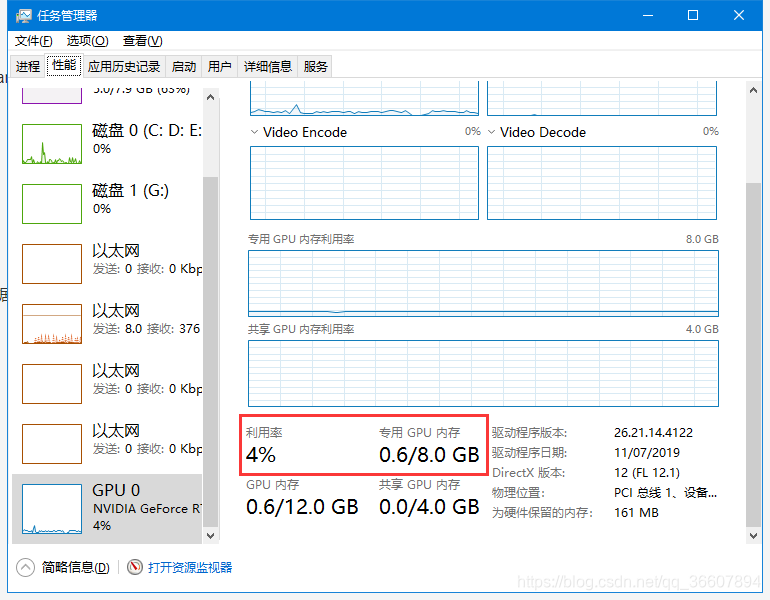
windows监视显卡运行
只能通过显存使用率来判断,Windows下也看不到每个程序单独占用的显存,Linux可以
-
用任务管理器
-
nvidia-smi.exe
用everything找到软件位置,我这里出现三个,大概是因为换过驱动,第一个是真正再用的

进行路径使用命令得到gpu使用情况
C:\Users\Administrator>cd C:\Windows\LastGood.Tmp\system32
C:\Windows\LastGood.Tmp\system32>nvidia-smi
Thu Nov 28 12:59:08 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 432.00 Driver Version: 441.22 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 206... WDDM | 00000000:01:00.0 On | N/A |
| 0% 48C P8 20W / 175W | 742MiB / 8192MiB | 4% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1060 C+G Insufficient Permissions N/A |
| 0 3092 C+G ...dows.Cortana_cw5n1h2txyewy\SearchUI.exe N/A |
| 0 6404 C+G ...9.0_x64__8wekyb3d8bbwe\WinStore.App.exe N/A |
| 0 6688 C+G ...t_cw5n1h2txyewy\ShellExperienceHost.exe N/A |
| 0 7232 C+G ...al\Google\Chrome\Application\chrome.exe N/A |
| 0 7888 C+G C:\Windows\explorer.exe N/A |
| 0 8448 C+G ...mmersiveControlPanel\SystemSettings.exe N/A |
| 0 9736 C+G ...hell.Experiences.TextInput.InputApp.exe N/A |
| 0 14268 C+G ...am\resources\bin\TBC\xlbrowsershell.exe N/A |
| 0 16164 C+G ...ng Biji\印象笔记\EvernoteSubprocess.exe N/A |
+-----------------------------------------------------------------------------+
C:\Windows\LastGood.Tmp\system32>nvidia-smi -l
Thu Nov 28 12:59:14 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 432.00 Driver Version: 441.22 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 206... WDDM | 00000000:01:00.0 On | N/A |
| 0% 48C P8 20W / 175W | 742MiB / 8192MiB | 4% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1060 C+G Insufficient Permissions N/A |
| 0 3092 C+G ...dows.Cortana_cw5n1h2txyewy\SearchUI.exe N/A |
| 0 6404 C+G ...9.0_x64__8wekyb3d8bbwe\WinStore.App.exe N/A |
| 0 6688 C+G ...t_cw5n1h2txyewy\ShellExperienceHost.exe N/A |
| 0 7232 C+G ...al\Google\Chrome\Application\chrome.exe N/A |
| 0 7888 C+G C:\Windows\explorer.exe N/A |
| 0 8448 C+G ...mmersiveControlPanel\SystemSettings.exe N/A |
| 0 9736 C+G ...hell.Experiences.TextInput.InputApp.exe N/A |
| 0 14268 C+G ...am\resources\bin\TBC\xlbrowsershell.exe N/A |
| 0 16164 C+G ...ng Biji\印象笔记\EvernoteSubprocess.exe N/A |
+-----------------------------------------------------------------------------+
Thu Nov 28 12:59:19 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 432.00 Driver Version: 441.22 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 206... WDDM | 00000000:01:00.0 On | N/A |
| 0% 48C P8 20W / 175W | 742MiB / 8192MiB | 3% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1060 C+G Insufficient Permissions N/A |
| 0 3092 C+G ...dows.Cortana_cw5n1h2txyewy\SearchUI.exe N/A |
| 0 6404 C+G ...9.0_x64__8wekyb3d8bbwe\WinStore.App.exe N/A |
| 0 6688 C+G ...t_cw5n1h2txyewy\ShellExperienceHost.exe N/A |
| 0 7232 C+G ...al\Google\Chrome\Application\chrome.exe N/A |
| 0 7888 C+G C:\Windows\explorer.exe N/A |
| 0 8448 C+G ...mmersiveControlPanel\SystemSettings.exe N/A |
| 0 9736 C+G ...hell.Experiences.TextInput.InputApp.exe N/A |
| 0 14268 C+G ...am\resources\bin\TBC\xlbrowsershell.exe N/A |
| 0 16164 C+G ...ng Biji\印象笔记\EvernoteSubprocess.exe N/A |
+-----------------------------------------------------------------------------+
C:\Windows\LastGood.Tmp\system32>^Z
gpu加速时:CPU 和 GPU的分工,如果充分利用CPU 和 GPU
参考这篇博客,讲的很彻底很到位
CPu主要用于加载和传输数据,把线程数增多分担任务,把pin_memory打开,直接映射数据到GPU的专用内存,减少数据传输时间
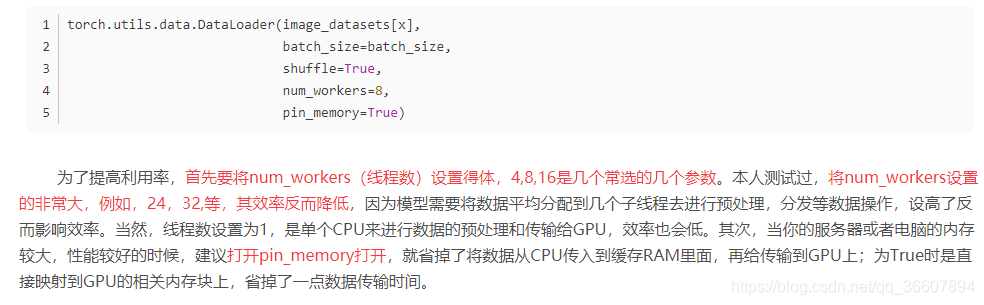
但是经过尝试,单个GPU这两种操作都不支持······
pin_memory=True报错
return data.pin_memory()
RuntimeError: cannot pin 'torch.cuda.FloatTensor' only dense CPU tensors can be pinned
num_workers设置就会报错
File "D:\ProgramData\Anaconda3\envs\pytorch_gpu\lib\site-packages\torch\multiprocessing\reductions.py", line 242, in reduce_tensor event_sync_required) = storage._share_cuda_() RuntimeError: cuda runtime error (801) : operation not supported at C:\w\1\s\tmp_conda_3.7_104508\conda\conda-bld\pytorch_1572950778684\work\torch/csrc/generic/StorageSharing.cpp:245
不知道是为啥,还没解决
GPU做运算
