本人最近在研究语音识别的生成Graph和Lattice的模块,其中用到了WFST这个概念,惊叹于它的神奇也被它的复杂搞得晕头转向。于是决定静下心来仔细研读了Mohri大牛的Speech Recognition with Weighted Finite-state Transducer这篇论文和一些相关资料,算是入门了其中的算法,有些体悟在这里和大家一起探讨,也算是对自己近期学习的一个总结。本系列会先引入WFST的概念,然后介绍它的三大算法:Composition、Determinization和Minimization,最后介绍WFST在语音识别中的应用,即HCLG的操作。
首先先明确几个概念。有限状态转换器FST(finite-state transducer) 和加权有限状态转换器WFST(weighted finite-state transducer)的不同就是后者转移路径上附有权重;而WFST和WFSA(weighted finite-state acceptor)的区别就是前者的状态转移上的label既有输入又有输出而后者只有一个label。我们用WFST来表征ASR中的模型(HCLG),可以更方便的对这些模型进行融合和优化,于是可以作为一个简单而灵活的ASR的解码器(simple and flexible ASR decoder design)。
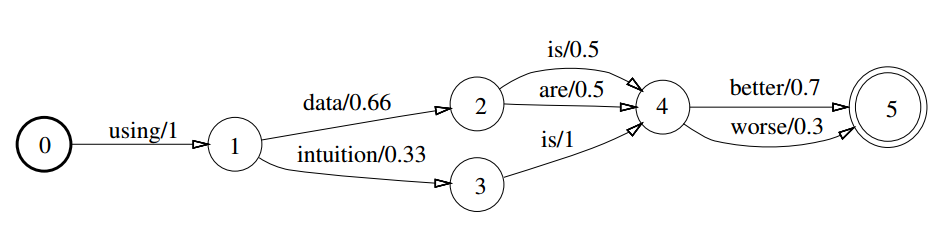
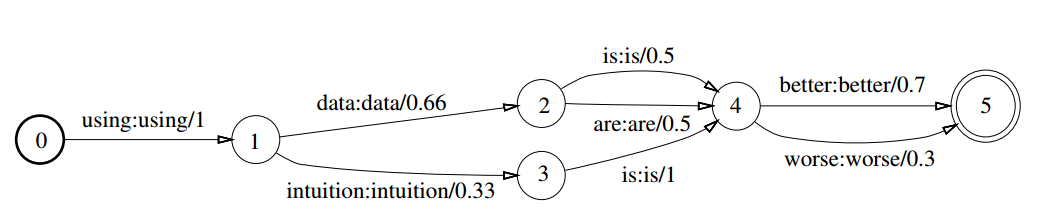
WFST是基于半环代数理论的,在介绍半环之前我先简单的说一下群和半群。
群(Group):G为非空集合,如果在G上定义的二元运算*,满足:
(1)封闭性(Closure):对于任意
(2)结合律(Associativity):对于任意
(3)幺元(Identity):存在幺元e,使得对于任意
(4)逆元:对于任意a
则称(G,*)为群。
半群(Semigroup):仅满足封闭性和结合律群称为半群;如果还包含幺元,则成为幺元半群。
介绍完群和半群,我们就引入半环的概念,半环代数理论始于19世纪末,属于抽象代数的范畴,1934年Vandiver首次对它做了较为系统的研究。
半环(semiring):指具有两个二元运算”+ “和”
(1)(S,+)和(S,
(2)(
半环的表现形式是(K,
在文本和语音处理中最常用的的是后面两个,即log半环和tropical半环,前者是通过-log来映射而后者是在log半环的基础上使用了Viterbi Approximation(有大神能帮忙解释一下这个估计么…)
半环有一些简单的性质(这几个性质不是很好翻译,希望有大神提供~):
(1)weakly left-divisble:对K中任意的x和y,如果
(2)
(3)zero-sum-free:对K中任意的x和y,如果
概率半环,log半环和tropical半环都是zero-sum-free的。
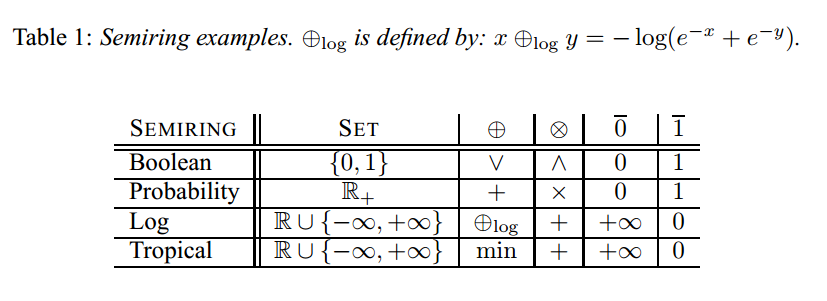
定义了半环结构,就可以利用它来表征一个WFST了。知道这些字母的含义就可以看懂后面的伪代码了。
从状态转移的角度来看,如果一个状态转移
那么,一条路径(path)就是一连串的转移,
定义完半环结构上的集合,那么接下来就是对它们的二元运算了。
一整条路径的权重
那么多个有限路径集合的权重
有了上面的基础,宏观的看一个规范的(regulated)WFST可以表示为:
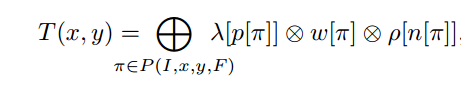
其中,
定义完了一个WFST,下面就准备开始介绍三大算法啦~~~~码了好多字好累…
转自:http://blog.csdn.net/l_b_yuan/article/details/50876340
