rtmp 1
zhangbin 20191202
参考 简书 作者:jerryyyq 链接:https://www.jianshu.com/p/bae4ee898019
rtmp 也是实时的
-
复用 Multiplexing :将独立的音视频数据整合至一个音视频流中,从而使得可以同步传输多个音视频数据
-
分组
-
基于tcp
-
双向
-
消息复用
-
带时间信息都消息
-
按照消息类别有优先级
-
packet 叫做分组
-
分组的头部固定
-
消息流 是一种抽象,抽象的是消息的传输通道
-
消息流以ID区分
-
chunk 是消息碎片 ,chunk能保证跨流的传输时的时间序列
-
- 消息碎片。消息通过网络发送前分解成小块并交错存取。块保证了所有消息在点对点跨流时保持时间序列传输。
-
chunk stream 块流 : 支持快 定向传输的逻辑通道 ,双向
-
AMF
-
• 活动消息格式(Action Message Format, AMF):一种紧凑二进制格式,用于格式化活动脚本对象图(ActionScript object graph)。AMF目前有两个版本:AMF0 和 AMF3
字节对齐和字节序
- 协议里的整型数据,在发送或者接收到的时候,都是大端的
- 对齐是按照字节来的,至少要占用一个字节大小的空间
所有的整型字段都是使用网络字节序(big-endian)进行传输的,
RTMP中所有数据都是字节对齐(byte-aligned)的;举个例子,一个16位的变量可能会处于奇数偏移位置。当需要补齐时,对应字节应当用用0填充。
时间戳
- rtmp分组里的时间戳的相对的,双方要先协商好?
- 需要借助第三方做同步?
- 时间戳是32位的无符号的,所以有回卷问题。
- RTMP中时间戳是一个整型值,单位为毫秒,它是一个相对值,相对未规定的某一时间点。通常,每个流会从时间戳0开始,但也不是必须的,只要流两端能够协商某一起始点即可。
- 同步
- - 注意,这说明任何需要跨流(尤其是不同主机间)同步必须依赖RTMP以外的其他机制。
- - 时间戳增量同样规定为一个无符号整形数,单位毫秒,但相对于时间为上一时间戳。时间戳增量可使用24或32bits长度。
4 chunk stream
- 看起来是一种较为底层的应用协议,作用了复用、分组
- 比如大的分组拆分为更小的分组 ,并且分钟格式可以保证时间戳序列化顺序的
- 为更高层流媒体协议提供了复用和分组服务。
- 虽然RTMP块流设计用于协同RTMP协议工作,但它同样适用于其他发送消息流的协议。每条消息由时间戳和负载类型标识构成。RTMP块流和RTMP广泛适用于各种音视频应用,既支持“一对一”或“一对多”实时广播,也支持为会议交互系统提供视频点播(video-on-demand)服务。
- 当配合可靠传输协议如TCP时,RTMP块流提供了有保证的时间戳序列的对端跨流消息传输。RTMP块流并未提供任何优先级或相关形式的控制,但可被高层协议用于提供类似功能。例如,一个实时视频服务器可能会参考每条消息发送和响应的时间,来决定是否要丢弃部分视频消息以满足较慢客户端能够流畅地接收音频数据。
- RTMP块流集成了带内(in-band)协议控制消息,而且为高层协议提供了嵌入自定义控制消息的机制。
4.1 chunk stream 消息格式
- 区分不同的比chunk stream 更高层的协议
- 按照这个格式创建chunk
- 4 个字节的时间戳 + 3个字节的长度(应包含有头部大小之后的) + 1个字节的类型id ,用于控制协议 + 消息流id ,对chunk stream 做复用和解复用时,可以区分不同的消息流 (这个是小端存的???)
• 时间戳Timestamp:消息时间戳,该字段为4个字节
• 长度Length: 消息负载长度,如果消息头(header)不能被省略,其长度也应计入其中。该字段占用块头中的3个字节
• 类型Id:一些类型ID预留用于协议控制消息,这些传递信息的消息会同时被RTMP块流协议和高层协议处理。所有其他的类型ID则由高层协议使用,RTMP块流会直接忽略这些值。实际上,RTMP块流并不需要类型ID,所有消息都可以是同一类型,有时候应用可以通过该字段来区隔同步轨。该字段占用块头中的1个字节
• 消息流ID:消息流ID可以是任意值,不同的消息流复用到同一块流,然后再根据各自消息流ID进行解复用。除此之外,别无用处。该字段占用块头中的4字节,使用小端法(little-endian)格式。
4.2 握手
- 握手用的块是固定大小的
- 客户端和服务端各有三个同样的块 用来握手
- 客户端发了c0 c1,收到了s1 ,发c2, 然后收到s2 之后才发送其他的数据
- 以客户端发送C0和C1块开始的。
- 客户端必须成功接收到S1后才发送C2,且必须成功接收S2后才可以发送其他数据。
-
服务器必须收到c0,也可以是等收到了c1 之后,发送s0 和s 1, 收了c1之后,才会发送s2 ,之后才会发送其他数据。
-
c0 s0 是八位,1个字节 ,里面是rtmp的版本号,值为3
-
版本 4-31 被预留用于后续产品;版本 32-255(为了区分 RTMP 协议和文本协议,文本协议通常以可打印字符开始)不允许使用。如果服务器无法识别客户端的版本号,应该回复版本 3。客户端可以选择降低到版本 3,或者中止握手过程。
-

-
c1 s1 是1536个字节 , 起始时间戳 在这里包含
-

• Time (4 bytes): 该字段包含一个时间戳,它是所有之后发出块的起始点。它既可以是0值,也可以是其他任意数字。为了同步多个块流,断点可能会希望发送其他块流的当前时间戳。毫秒值的时间戳,这个值可以是 0,或者一些任意值。用于本终端发送的所有后续块的时间起点。
• Zero (4 bytes):必须全 0
• Random data (1528 bytes):本字段可以包含任意数据。由于握手的双方需要区分另一端,此字段填充的数据必须足够随机(以防止与其他握手端混淆)。不过没必要为此使用加密数据或动态数据。
- 服务端必须接收到 C0 消息,才能发送 S0 和 S1 消息。
- c2 s2 也是1536 字节 ,相当于 分别对s1和 c1的 确认应答
- 客户端必须接收到 S1 消息,然后发送 C2 消息。客户端必须接收到 S2 消息,然后发送其他数据。
服务端必须接收到 C1 消息,然后发送 S2 消息。服务端必须接收到 C2 消息,然后发送其他数据。

-
time1: 这个字段必须是对端发送过来的时间戳(C1 或 S1 内的)。
time2: 这个字段值为本机接收到对端发送过来的握手包的时刻。
random echo: 这个字段必须是对端发送过来的随机数据。握手的双方可以使用 time1 和 time2 字段来估算网络连接的带宽和/或延迟,但是不一定有用。 -
上面就是 简单握手
复杂握手
- 握手步骤没有变,但内容完全不一样,数据是加密的。
- 它的步骤是由三个固定大小的块组成,而不是可变大小的块加上头
- 握手开始于客户端发送 C0 + C1 块。
- 在发送 C2 之前客户端必须等待接收 S1
- 在发送任何数据之前客户端必须等待接收 S2。
- 服务端在发送 S0 和 S1 之前必须等待接收 C0,也可以等待接收C1。
- 服务端在发送 S2 之前必须等待接收 C1。
- 服务端在发送任何数据之前必须等待接收 C2。
- C1 / S1 和 C2 / S2 的 1536 字节是:
4 字节的当前时间:(u_int32_t)time(NULL)
4 字节的程序版本:C1 一般是 0x80000702,S1 是 0x04050001
764 字节的 KeyBlock 或者 DigestBlock
764 字节的 KeyBlock 或者 DigestBlock
code
c0 和 s0 都是只有一个字节的
// The C0 and S0 packets are a single octet, treated as a single 8-bit integer field:
//
// 0 1 2 3 4 5 6 7
// +-+-+-+-+-+-+-+-+
// | version |
// +-+-+-+-+-+-+-+-+
//
版本不支持
- rtmp 1.0 ,如果服务端不认识客户端的版本,那么返回3
// In RTMP 1.0, A server that does not recognize the client's requested version SHOULD respond with 3.
func newChunkC0S0() *chunkC0S0 {
return &chunkC0S0{version: 3}
}
c1和s1
- 都是1536个字节
- 4 个字节的时间
- 4 个字节的0
- 1528个随机字节
// The C1 and S1 packets are 1536 (=32*48) octets long, consisting of the following fields:
//
// 0 1 2 3
// 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | time (4 bytes) |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | zero (4 bytes) |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | random bytes |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | random bytes |
// | (cont) |
// | .... |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
//
func newChunkC1S1(time1 uint32) *chunkC1S1 {
randomBytes := make([]byte, 1528)
rand.Read(randomBytes)
return &chunkC1S1{
time: time1,
randomBytes: randomBytes,
}
}
type chunkC1S1 struct {
time uint32 //8个字节都认为是时间???
randomBytes []byte // 1528 bytes
}
func (c *chunkC1S1) Bytes() []byte {
chunk := make([]byte, 1536)
binary.BigEndian.PutUint32(chunk[:4], c.time)
copy(chunk[8:], c.randomBytes)
return chunk
}
func readC1S1(br *bufio.Reader) (*chunkC1S1, error) {
chunk := make([]byte, 1536)
_, err := io.ReadAtLeast(br, chunk, 1536)
if err != nil {
return nil, err
}
return &chunkC1S1{
time: binary.BigEndian.Uint32(chunk[:4]),
randomBytes: chunk[8:],
}, nil
}
c2 和 s2
- 1536 个字节
- 分别是对s1和c1的拷贝
// The C2 and S2 packets are 1536 (=32*48) octets long, and nearly an echo of S1 and C1 (respectively), consisting of the following fields:
//
// 0 1 2 3
// 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | time (4 bytes) |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | time2 (4 bytes) |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | random echo |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
// | random echo |
// | (cont) |
// | .... |
// +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
//
func newChunkC2S2(c *chunkC1S1) *chunkC2S2 {
now := uint32(time.Now().UnixNano() / int64(time.Millisecond))
return &chunkC2S2{
time: c.time,
time2: now,
randomEcho: c.randomBytes,
}
}
type chunkC2S2 struct {
time uint32
time2 uint32
randomEcho []byte // 1528 bytes
}
func (c *chunkC2S2) Bytes() []byte {
chunk := make([]byte, 1536)
binary.BigEndian.PutUint32(chunk[:4], c.time)
binary.BigEndian.PutUint32(chunk[4:8], c.time2)
copy(chunk[8:], c.randomEcho)
return chunk
}
func readC2S2(br *bufio.Reader) (*chunkC2S2, error) {
chunk := make([]byte, 1536)
_, err := io.ReadAtLeast(br, chunk, 1536)
if err != nil {
return nil, err
}
time1 := chunk[:4]
time2 := chunk[4:8]
return &chunkC2S2{
time: binary.BigEndian.Uint32(time1),
time2: binary.BigEndian.Uint32(time2),
randomEcho: chunk[8:],
}, nil
}
握手图
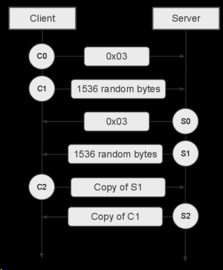
- 可以看到c2是对s1点拷贝
- s2是对c1的拷贝
