GAN是近几年深度学习的一个新秀,并且一直占据着“网红”的地位。因为毕设选择做了GAN相关的课题,因此最近才开始学习李宏毅老师的视频。本文将介绍传统GAN的基本思想及其数学原理,因学识尚浅,不足之处还望各位大佬指正。
GAN的基本思想
GAN的全称是Generative Adversarial Network,即生成对抗网络。顾名思义,GAN是一种生成模型,采用的是博弈的思想。说到博弈,那么一定就有两个对立方,对应GAN的两个结构:一个是生成器(Generator),一个是判别器(Discriminator)。
使用GAN的目的,是用来学习某种特定的数据分布。例如我想通过GAN来产生手写数字图片,那么首先要有mnist一类的数据集,然后通过学习,得到手写体数据集的数据分布,之后才能产生出逼真的手写数字图片。那么如何通过GAN学习到这种数据分布呢?看一下GAN的原理图:
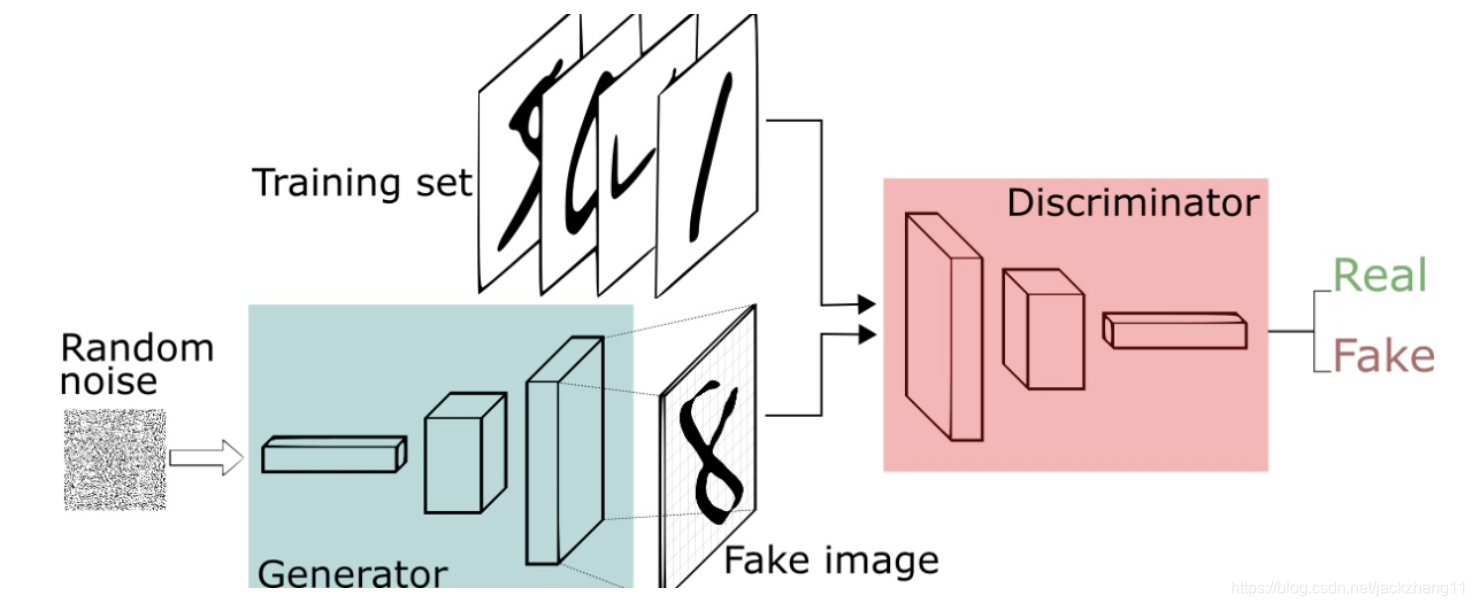
对于Generator,我们希望输入一些随机噪声,输出的是逼真的手写数字图像。但是呢,没经过任何训练的Generator怎么能知道我生成的图像就是很棒(高仿)的呢?这时候需要一个Discriminator来对他批评指正。这个Discriminator负责给训练集的图片高分,给Generator生成的图像低分。
这样Generator就知道自己的不足在哪了,于是生成更逼真的来蒙骗Discriminator;而Discriminator也在不断进步,能够找出这个更逼真的图片与真实数据集之间的差别。反复迭代,Generator不断强大,同时Discriminator也愈发严厉,最终Generator可以达到非常好的效果,即生成非常逼真的图片,让Discriminator鉴别不出来。
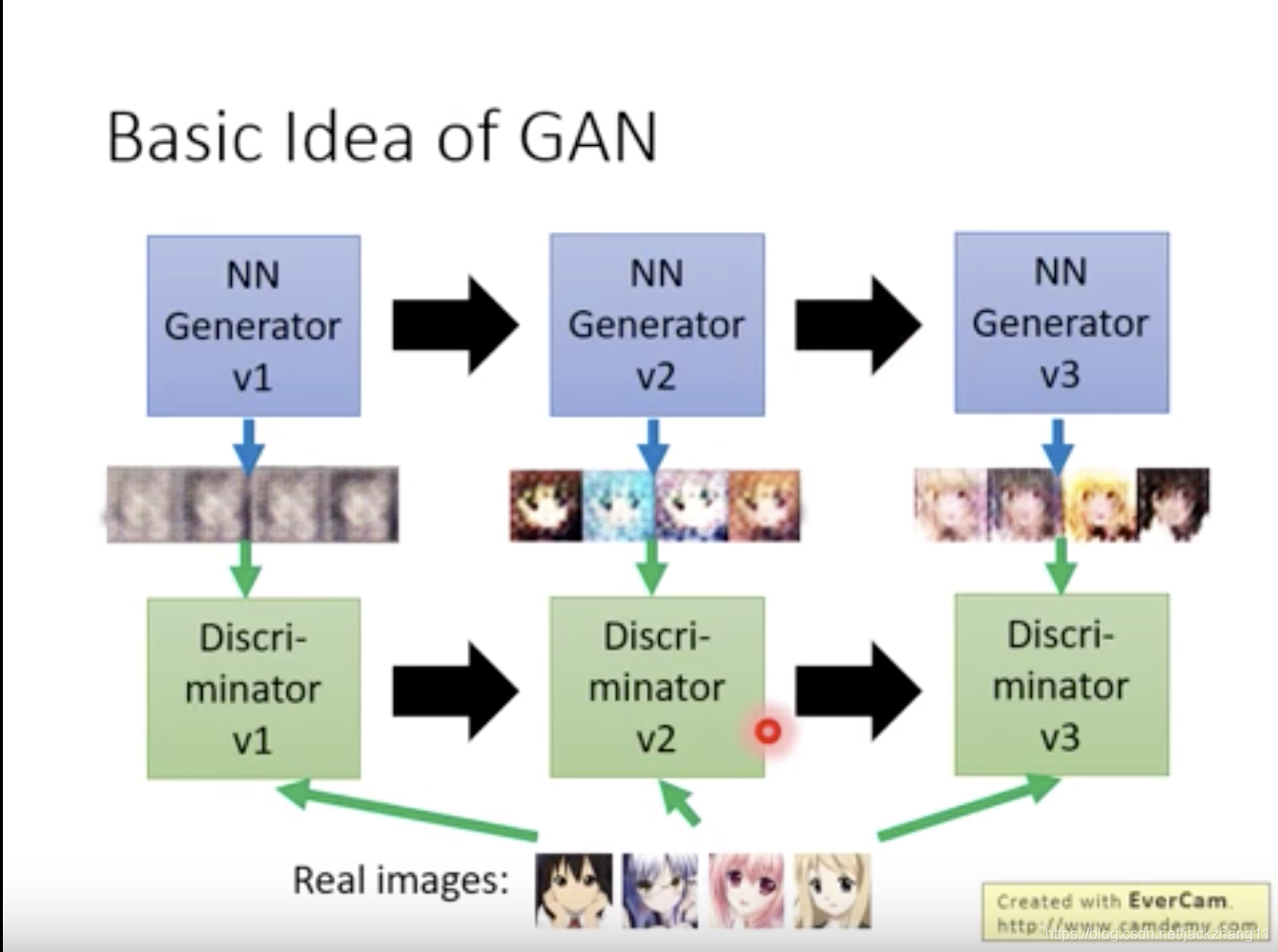
下面举一个李宏毅老师视频中的例子:
假设GAN的目标是要生成动漫头像。那么第一代Generator产生了一些非常模糊的图像,第一代Discriminator通过对比真实动漫头像,学习到了真实的头像是要有眼睛的;于是第二代Generator产生的动漫头有了大大的眼睛,但是第二代Discriminator通过对比真实图像,又发现了真实动漫头像是有嘴巴的;因此第三代Generator产生的图像有了嘴巴。然而第三代Discriminator又发现了balabala…的问题,多次博弈以后,Generator生成的动漫头像就越来越真实了。
我们已经知道了Generator和Discriminator的作用,那么他们本身到底是什么呢?在这里一般都会使用神经网络,而且并不是两个单独的网络,而是将两者拼接在一起,构成一个更加庞大的神经网络。
在Generator中,输入是一个向量(随机噪声),输出是一张image。在Discriminator中,输入是Generator生成的image,输出是一个介于0-1的值,越接近1表明Generator生成的图片越真实,接近0表明生成的图像不真实。因此可见在这个庞大的神经网络中,Generator在较浅的层,Discriminator在较深的层。
应该怎样去训练这个网络呢,下面从文字叙述的角度看下这个算法:
- 固定Generator的参数,去训练Discriminator的参数。我们从真实数据集中取样m个sample,同时用Generator生成m个sample,数据集取样的对应Discriminator最后的输出为1,Generator生成的对应输出为0。对Discriminator的参数进行训练。
- 固定Discriminator的参数,去训练Generator的参数。训练的目的是要让Discriminator的值不断提高,意味着我Generator产生的图像与真实的越来越接近。
- 1和2的步骤交替进行,多次迭代,最终让Generator产生出来的图像,被Discriminator识别不出,即给0.5的评分。
为什么不只用Generator?
到这里,对GAN的基本思想有了一个介绍。但有的小伙伴可能会疑惑,我只用Generator不可以吗?为什么还要用Discriminator?
扫描二维码关注公众号,回复:
8967980 查看本文章

答案是可以直接用Generator生成图像,不过效果不好。
如果我们采用监督学习方法,AutoEncoder,或者是改良的VAE,都存在这样一个问题:即我们衡量生成图像与真实图像的标准,是一幅图中像素之间的差别,以下图为例:

上图中,我们希望产生Target所示的手写数字2.通过VAE算法,我们会认为上面两幅图的效果比下面两幅好,因为上面两幅图与Target只差一个像素,而下面两幅图差6个像素。但是,实际并不是这样的,上面两幅图差的一个像素出现在关键位置,可以很明显的发现这不是人手写的数字;而下面两幅图虽然差了6个像素点,但只是笔画长短略有不同,跟真实的手写图像更为相似。
因此,若只用VAE这样的Generator,得到的图像每个像素之间的关联是考虑不到的,如果产生孤立点也不易检测。但是,如果我们引入Discriminator,在Generator生成一张完整的图像后,Discriminator对于这个完整的生成图像,就能更容易在全局上有更好的把握。
至此,GAN的基本思想就大致介绍完了,下面写一点背后的数学原理。
GAN的数学原理
Generator
在传统的机器学习方法中,我们可以通过极大似然估计,来找一组Generator的参数,让Generator产生的数据分布,与真实数据分布最为接近,即最小化两者的KL散度。但是在实际应用中,我们并不知道真实数据的分布到底是什么?如果真实数据集是一个人脸数据集,那么他的分布远远要比常用的高斯混合模型复杂。
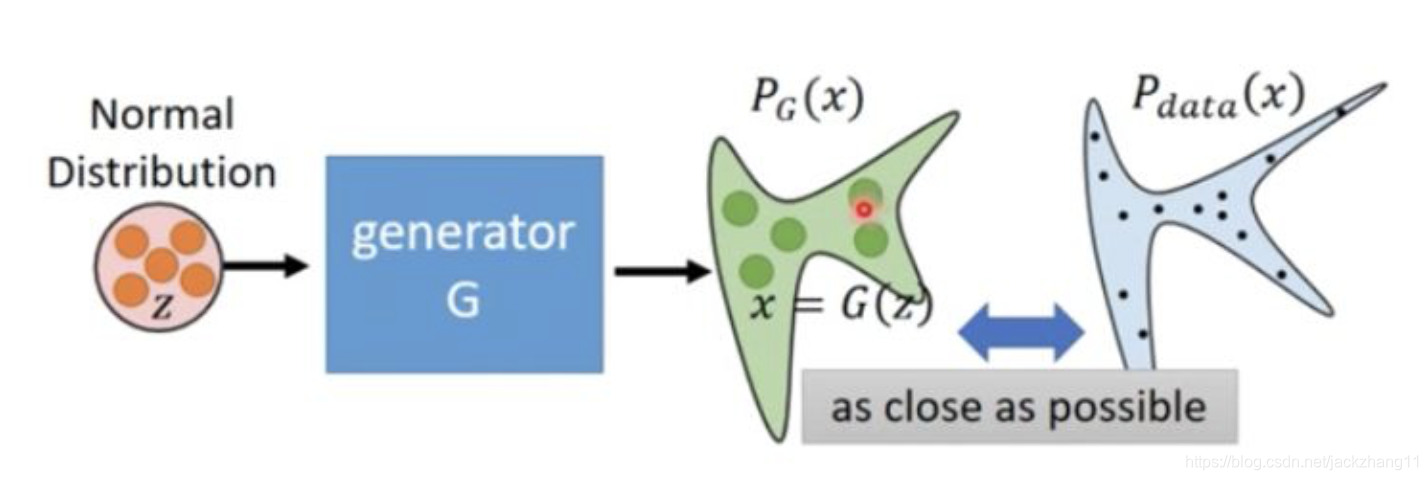
假设通过Generator产生的数据集合的分布为
PG,真实的数据分布为
Pdata。因此,我们希望通过训练Generator,让他生成出来的数据分布
PG,尽量去靠近
Pdata,即最小化两者之间的差异:
G∗=argminGDiv(PG,Pdata)
G∗ 是我们最小化
PG 和
Pdata 时对应的Generator的参数,即我们最终想要得到的Generator参数。那么如何去衡量这个
Div(PG,Pdata) 呢?这个时候就要引出Discriminator了。
Discrinimator
虽然我们不知道
PG 和
Pdata 这两个分布是什么,但是我们可以从这两个分布中进行采样。前面讲过,我们把一些随机噪声向量输入Generator,得到一些输出图片,然后在这些图片中进行采样,这些样本就是在
PG 中采样得到的样本。而对于
Pdata ,我们直接从数据集中选取几个样本即可。有了这些样本,我们就可以去计算Discriminator的目标函数:
V(G,D)=Ex∼Pdata[log(D(x))]+Ex∼PG[1−log(D(x))]上面公式的含义是:假设样本
x 是从真实分布
Pdata 中采样出来的,那么
D(x) 得到的分数越大(接近1),这个目标函数的值越大;反之,如果
x 是从
PG 中采样的,那么
D(x) 得到的分数就越小(接近0),整个目标函数的值也越大。因此,如果这个Discriminator鉴别能力足够强,那么这个目标函数就会变大,即
D∗=agrmaxDV(G,D)
所以Discriminator希望找到最好的参数
D∗,来最大化目标函数,这样Discriminator的鉴别能力很强。
换一种更直观的理解,如果Discriminator不能很好的区分
PG 和
Pdata,那么目标函数
V(G,D) 就不能被调大,这说明了
PG 和
Pdata 的分布比较接近。
下面我们来从数学的角度,看看这个目标函数
V(G,D) 还可以表示什么。
V(G,D)=Ex∼Pdata[log(D(x))]+Ex∼PG[1−log(D(x))]
=∫xPdata(x)logD(x)dx+∫xPG(x)[1−logD(x)]dx
=∫x[Pdata(x)logD(x)+PG(x)[1−logD(x)]]dx
在训练Discriminator的时候,是固定G不动的。因此,虽然我们不知道
PG 和
Pdata 是什么,但是在训练Discriminator时,可以将它们看作常数,用
a 代替
Pdata,用
b 代替
PG ,则上式中的积分部分可重写为:
f(D)=alogD+blog(1−D)
对
f(D) 进行求导,可得:
dDf(D)=a∗D1−b∗1−D1
令导数为0,可得极值点:
D∗=a+ba
那么将
a 和
b 原本的内容带进去,可得:
D∗=Pdata(x)+PG(x)Pdata(x)
得到了这个使目标函数最大的
D∗,我们将它反带到原来的目标函数
V(G,D) 中,通过一些数学变换和化简,神奇的事情出现了:
maxDV(G,D)=V(G,D∗)
=Ex∼Pdata[log(Pdata(x)+PG(x)Pdata(x))]+Ex∼PG[log(Pdata(x)+PG(x)PG(x))]
=∫xPdata(x)logPdata(x)+PG(x)Pdata(x)dx+∫xPG(x)logPdata(x)+PG(x)PG(x)dx
=∫xPdata(x)log21dx+∫xPG(x)log21dx+∫xPdata(x)log(Pdata(x)+PG(x))/2Pdata(x)dx+∫xPG(x)log(Pdata(x)+PG(x))/2PG(x)dx
=−2log2+∫xPdata(x)log(Pdata(x)+PG(x))/2Pdata(x)dx+∫xPG(x)log(Pdata(x)+PG(x))/2PG(x)dx
=−2log2+KL(Pdata∣∣2Pdata+PG)+KL(PG∣∣2Pdata+PG)
=−2log2+JSD(Pdata∣∣PG)
通过上面的化简,我们发现,最大化目标函数
V(G,D),实际上就是求解
Pdata 和
PG 之间的JS散度。因此,我们通过最大化这个目标函数,可以算出
Pdata 和
PG 这两个分布之间的差异。所以训练Discriminator,就是通过从
Pdata 和
PG 两个分布中取样出来的样本,去衡量两个分布之间的差别。
我们回头看一下,在Generator中,我们希望的是生成一个分布
PG,来拟合真实的数据分布
Pdata,因此有公式:
G∗=argminGDiv(PG,Pdata)
但是这个
Div(PG,Pdata) 如何去衡量?这里衡量的标准就用到了上面讲的JS散度,也就是用这个Discriminator来进行两个分布之间的差异的计算:
D∗=agrmaxDV(G,D)
通过找到这个使目标函数最大的
D∗,我们就能将其转化为跟两个分布之间JS散度相关的公式,即衡量两个分布差异的方法。因此,我们的优化目标更新为:
G∗=argminGmaxDV(G,D)
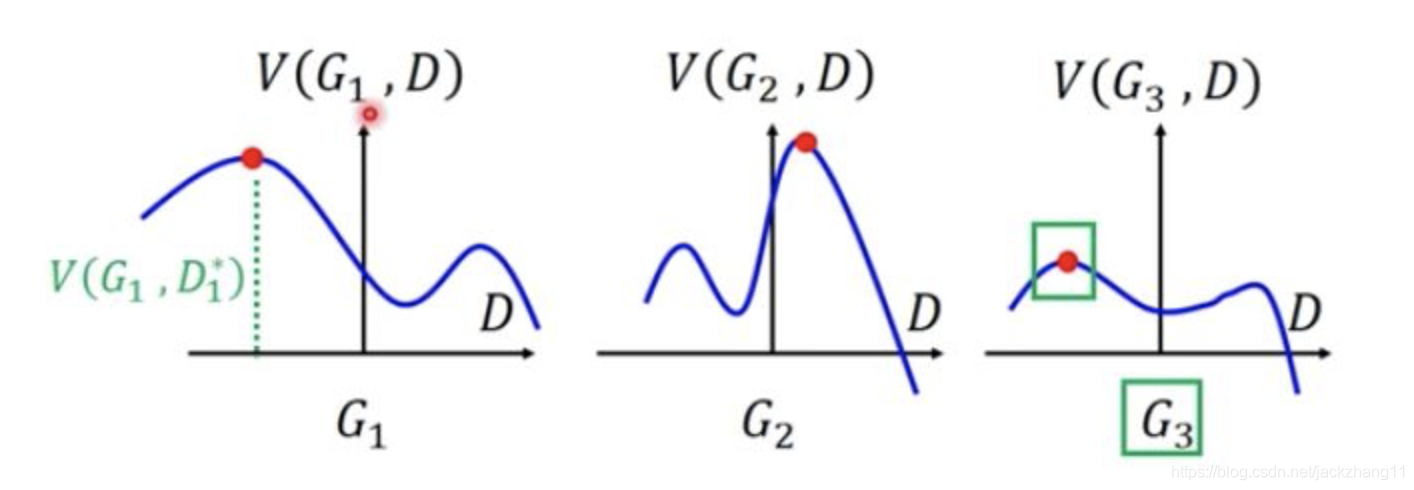
这个公式乍一看有min和max,非常的复杂,但其实不然。首先我们固定G,找到最大的D对应的点,即下图中红色的点。然后固定D,再比较这三个红色点的高度(两个分布之间的差异),选取高度最小的那个作为最佳结果,即图三中的红点,代表着两个分布间的JS散度小(差异小)。
最后给出整个算法的大致流程:
- 初始化一个
G0;
- 找到能使目标函数
V(G0,D) 最大的
D∗,该步骤可用梯度上升法来进行,
θD=θD+η▽V(θD)。找到的这个
D∗ 可带入
V(G0,D∗),即
Pdata 和
PG0 之间的JS散度;
- 固定参数
θD,寻找使目标函数
V(G,D∗) 最小的
G∗,用梯度下降法进行求解,即
θG=θG−η▽V(θG)。该过程可理解为对Generator的修正,让他生成的数据分布于真实数据分布之间的JS散度不断减小(差异变小)。
- 步骤2和3多次迭代,让两个分布不断接近。
注:Generator在训练中应遵循少量多次的原则,让两代之间Generator的差异不算太大,这样可以得到更好的结果。
以上就是个人目前对GAN一些粗糙浅薄的理解,如有不当,敬请指正。
参考:
https://zhuanlan.zhihu.com/p/54096381
https://www.bilibili.com/video/av24011528?p=4
