提示:使用 Java Lambda表达式,开发 Flink 离线任务。我们可以参考:Lambda 表达式编写 Flink 实时任务,开发流程类似于 Flink 开发实时任务。
场景:
我们使用 Lambda 表达式,来开发 Flink 离线任务 WordCunt
1.离线计算代码
离线计算,动态传递参数:args[0] 和 args[1]
/**
* TODO 离线WordCount计算(Lambda表达式)
*
* @author liuzebiao
* @Date 2020-2-4 17:37
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
//1.离线批处理使用的环境:ExecutionEnvironment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//使用 ExecutionEnvironment 创建 DataSet
DataSet<String> lines = env.readTextFile(args[0]);
//2.Transformations 操作
//切分压平
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lines.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
Arrays.stream(line.split(" ")).forEach(word -> out.collect(Tuple2.of(word, 1)));
}).returns(Types.TUPLE(Types.STRING,Types.INT));
//聚合
//离线计算实现的是分组聚合,调用的是groupBy()。实时计算调用的是 keyBy()
AggregateOperator<Tuple2<String, Integer>> sumed = wordAndOne.groupBy(0).sum(1);
//将结果保存成文本(或者保存到 hdfs 等)
//setParallelism(1):设置并行度
sumed.writeAsText(args[1]).setParallelism(1);
//离线计算不用执行 env.execute()
env.execute("BatchWordCount");
}
}
2.创建有界文档 word.txt
有界文档:固定大小的文档,用于离线计算(用于实时计算的为无界文档)
word.txt文档所在路径:C:\Users\a\Desktop\word.txt
word.txt 文档如下:
flink flume hadoop sqoop
java maven spring scala
flink flink spring java
java hadoop sqoop flume
flume spark spark spark
docker flink flink
3.指定结果输出路径
结果输出路径:C:\Users\a\Desktop\out
4.离线任务测试
4.1 参数设置

4.2 开始执行任务
离线任务,会有执行完成的时候。
实时任务,任务执行开始,只有人为取消或者出现异常,任务才会停止。
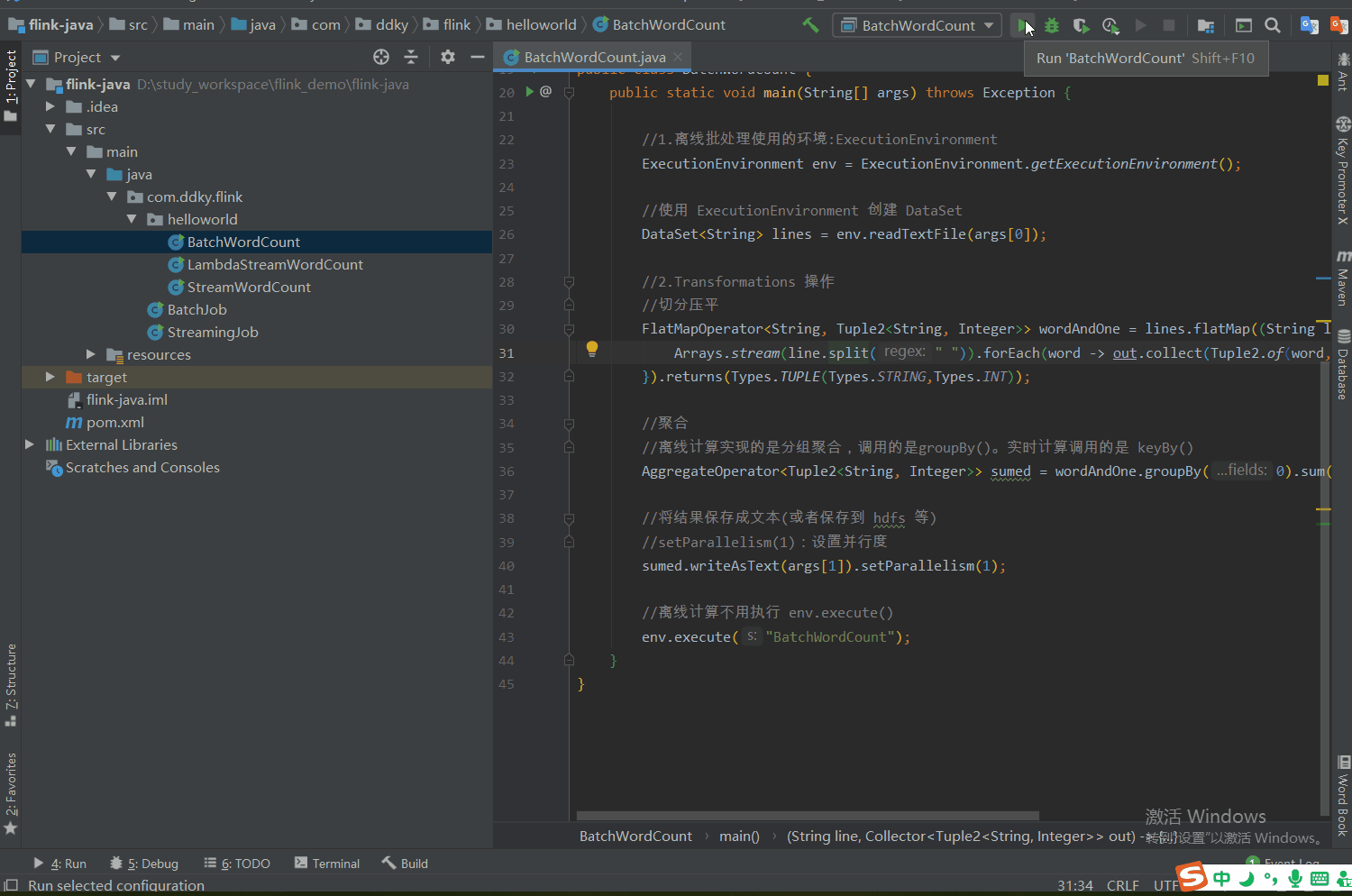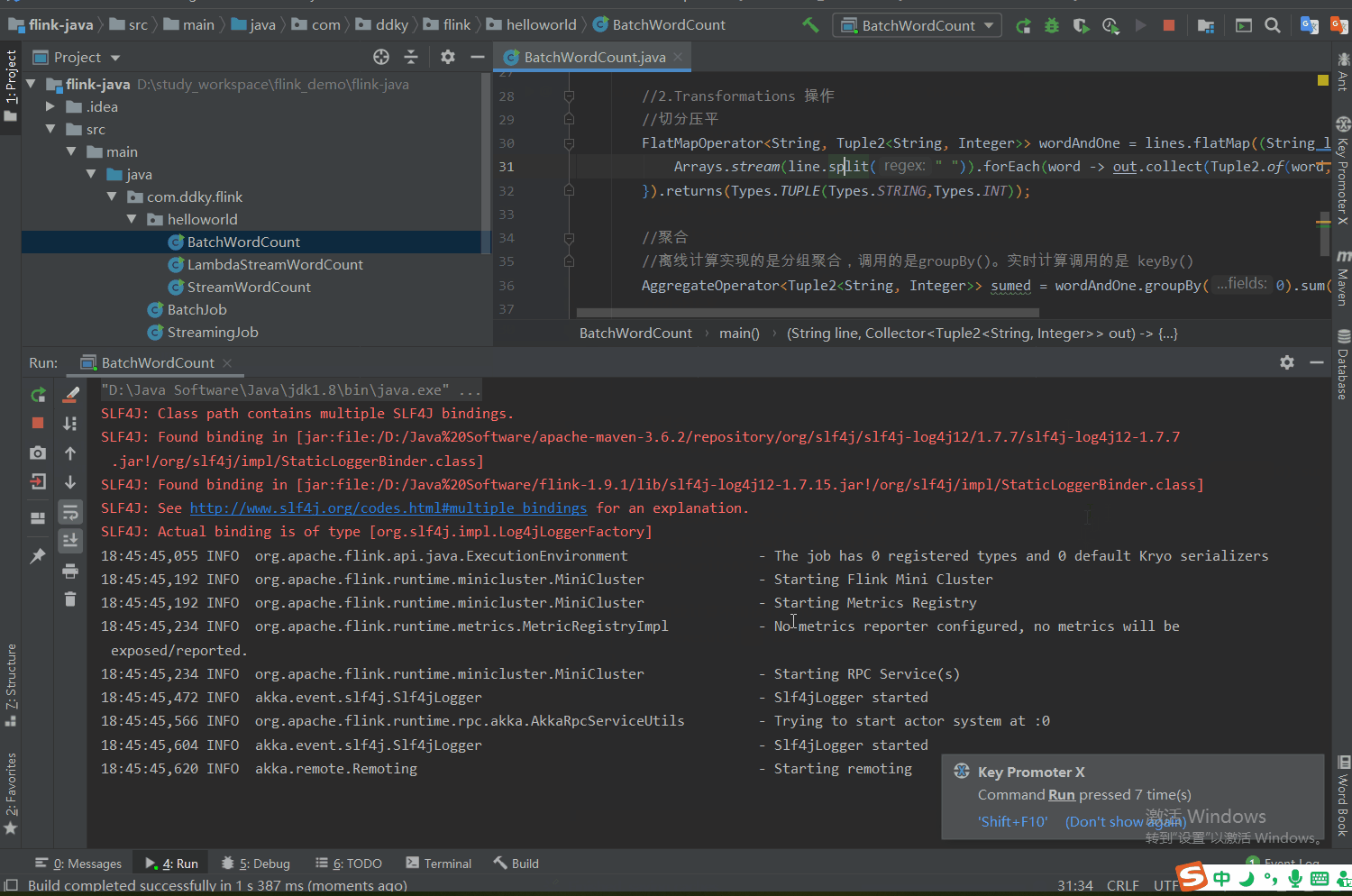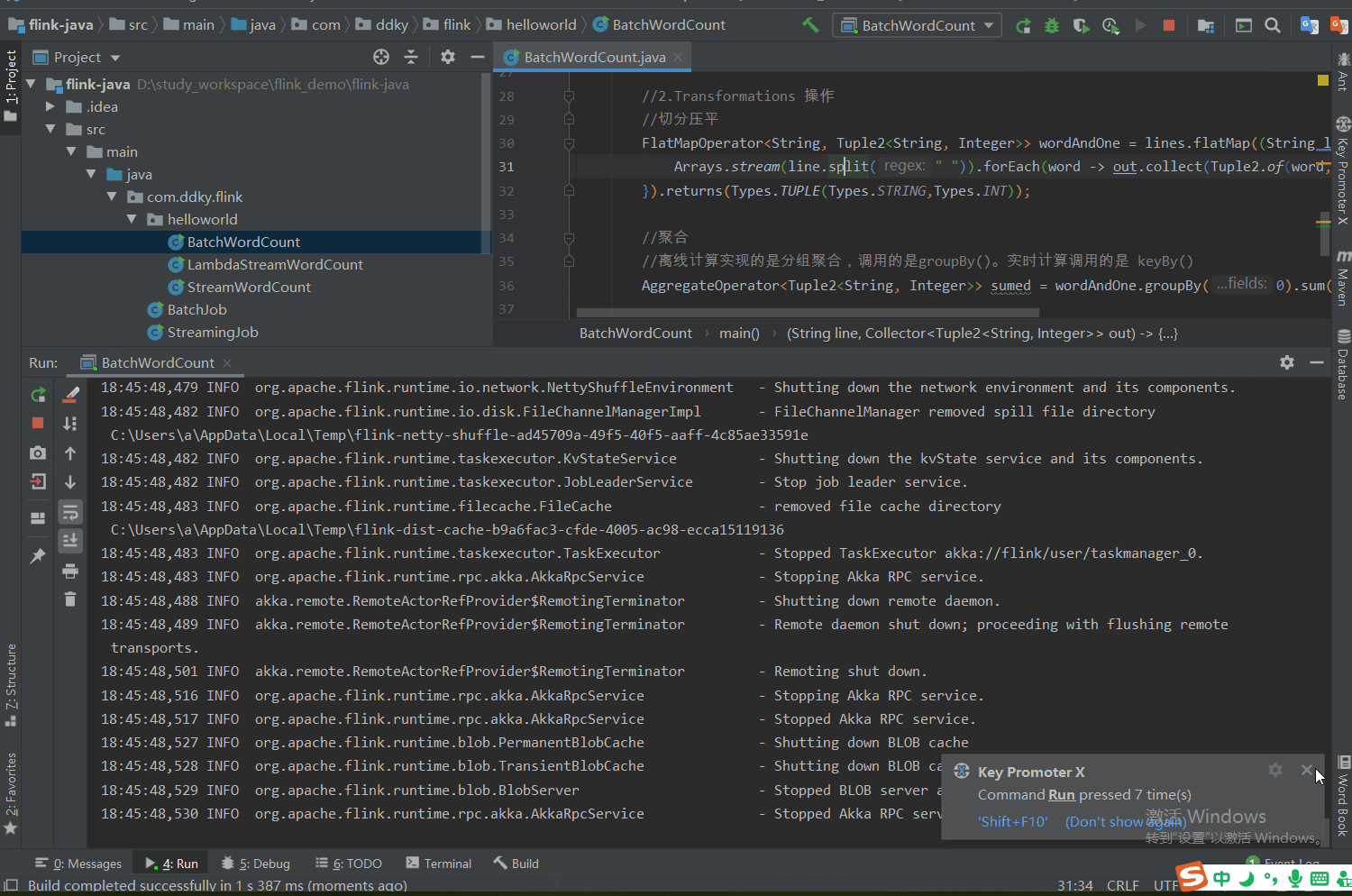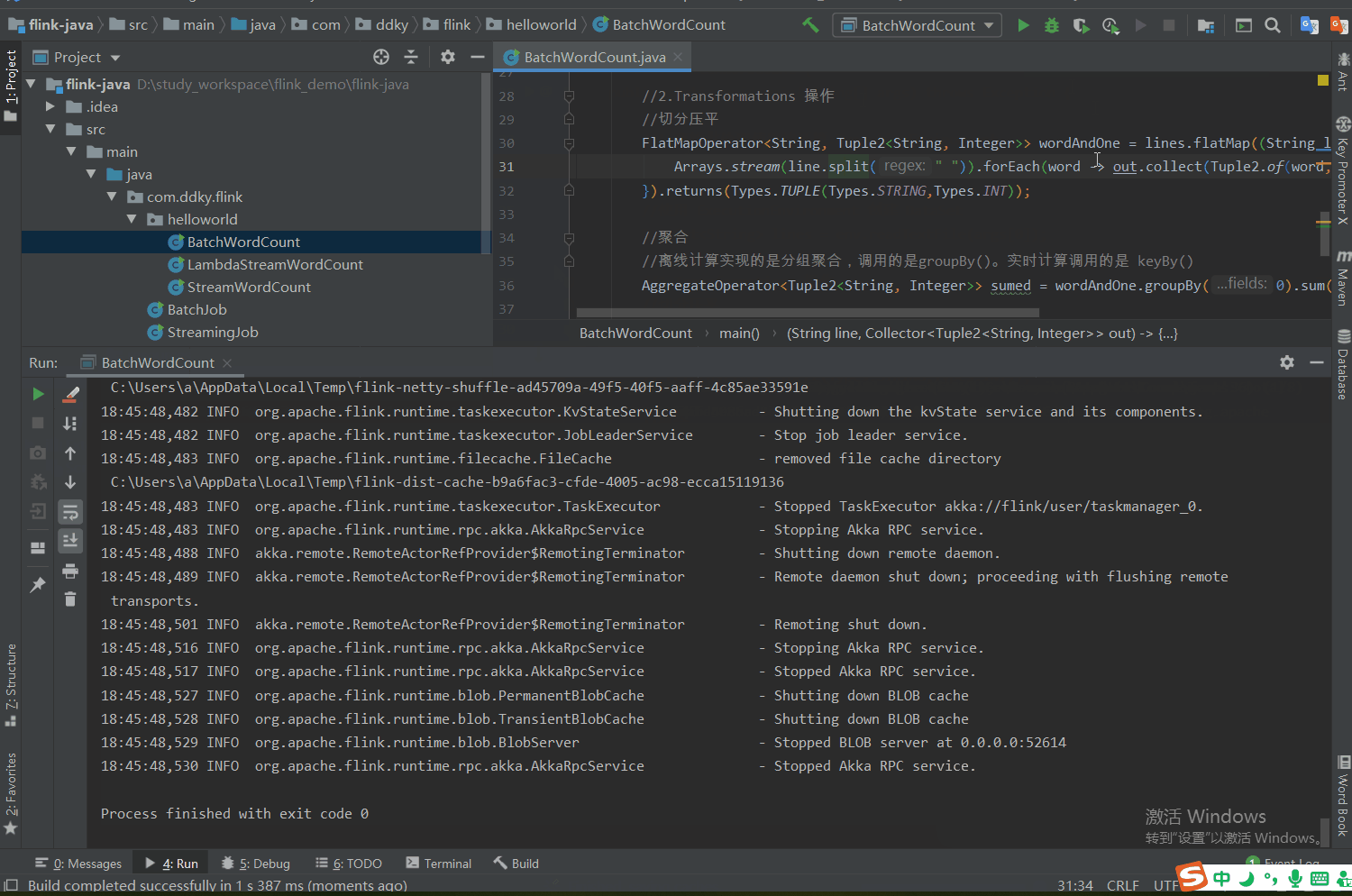
4.3 任务完成返回结果
任务执行完成后,会在指定的结果输出路径:C:\Users\a\Desktop\out生成文件,这就是任务执行完成之后返回的结果。返回结果如下:
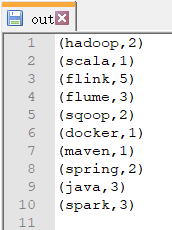
此时说明离线任务 WordCount 已经计算完成。
离线任务提交至Flink集群运行
与实时任务提交一样,请参考:如何将我们编写的Flink任务打包到集群运行
开发 Flink离线任务 WordCount,介绍到此为止
如果本文对你有所帮助,那就给我点个赞呗 O(∩_∩)O
End
