项目简介:抓取电影天堂的数据,xpath解析,存mysql
问题描述:
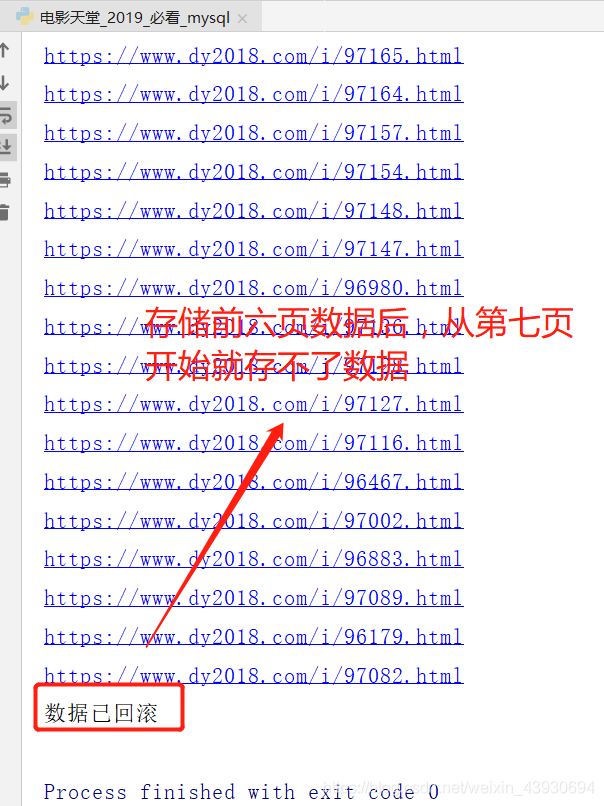
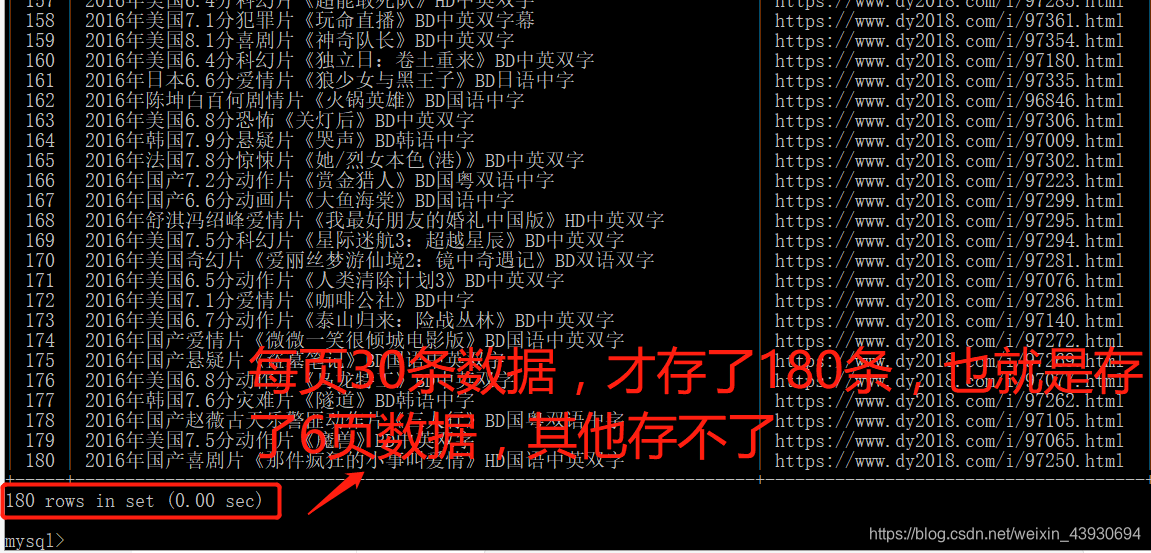
连续抓取并存储六页数据后,从第七页开始就不能存数据库了,直接回滚数 据库,至今仍未解决,请大佬会的麻烦解答一下 已解决
# python
# -*- coding:utf-8 -*-
# author:Only time:2019/8/15
# 爬取电影天堂 2019必看热片 名字、详情页 xpath解析 存mysql
import requests
import pymysql
from lxml import etree
# 获取所有网址
def get_urlpage():
base_url = 'https://www.dy2018.com/html/bikan/'
pagelist = []
pagelist.append(base_url) # 第一页 比较特殊
for i in range(2,23):
url = base_url + 'index_' + str(i) + '.html'
pagelist.append(url)
print(pagelist)
return pagelist
# 解析网页 获取 电影名字、详情页面
def html_parse_save_sql():
# 连接数据库
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123qwe',
database='only',
charset='utf8'
)
# 创建数据库游标
cursor = conn.cursor()
# 创建表
sql_1 = 'create table Dy(id int primary key auto_increment not null ,name varchar(200) not null,info varchar(200))'
cursor.execute(sql_1)
try:
header = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
for page in get_urlpage():
response = requests.get(page,headers = header)
response.encoding = 'gbk' # 解决乱码问题
print(response.status_code) # 查询状态码
responsee = response.text
html = etree.HTML(responsee)
name = html.xpath('//table//tr[2]//b/a[2]/text()') # 注意:坑: tbody千万不能写进xpath 会匹配不出结果
href_1 = html.xpath('//table//tr[2]/td[2]/b/a[2]/@href')
info = [] # 存完整的详情页网址
for i in range(len(href_1)):
info_1 = 'https://www.dy2018.com' + href_1[i]
info.append(info_1)
for i in range(len(info)):
sql_2 = 'insert into Dy(name,info) values ("%s","%s")'
cursor.execute(
sql_2 % (name[i],info[i])
)
print(info[i])
# 从游标中获取结果
cursor.fetchall()
# 提交结果
conn.commit()
print("结果已提交")
except Exception as e:
# 数据回滚
conn.rollback()
print("数据已回滚")
# 关闭数据库
conn.close()
if __name__ == '__main__':
html_parse_save_sql()
更新:
注意!!!
坑1:xpath解析时要避免出现tbody,否则会出现错误,匹配不了数据。
坑2:很奇怪,爬取电影天堂时从第七页开始,名字与链接的数量就不同了,到现在我不知道是什么原因!一开始我是以链接的长度为range的,但是出现错误,因为链接的长度有时会大于名字的长度,要以长度短的为range,即在代码中纠正。
坑3:一定要结合异常处理分析错误。
一、代码展示:
# python
# -*- coding:utf-8 -*-
# author:Only time:2019/8/15
# 爬取电影天堂 2019必看热片 名字、详情页 xpath解析 存mysql
import requests
import pymysql
from lxml import etree
# https://www.dy2018.com/html/bikan/index_7.html
# 获取所有网址
def get_urlpage():
base_url = 'https://www.dy2018.com/html/bikan/'
pagelist = []
pagelist.append(base_url) # 第一页 比较特殊
for i in range(2,23):
url = base_url + 'index_' + str(i) + '.html'
pagelist.append(url)
return pagelist
# 解析网页 获取 电影名字、详情页面
def html_parse_save_sql():
# 连接数据库
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123qwe',
database='only',
charset='utf8'
)
# 创建数据库游标
cursor = conn.cursor()
# 创建表
sql_1 = 'create table Dy(id int primary key auto_increment not null ,name varchar(200) not null,info varchar(200))'
cursor.execute(sql_1)
try:
header = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
for page in get_urlpage():
response = requests.get(page,headers = header)
response.encoding = 'gbk' # 解决乱码问题
print(response.status_code) # 查询状态码
responsee = response.text
html = etree.HTML(responsee)
name = html.xpath('//table//tr[2]//b/a[2]/text()') # 注意:坑1: tbody千万不能写进xpath 会匹配不出结果
href_1 = html.xpath('//table//tr[2]/td[2]/b/a[2]/@href')
info = [] # 存完整的详情页网址
for i in range(len(href_1)):
info_1 = 'https://www.dy2018.com' + href_1[i]
info.append(info_1)
# 测试匹配到的数据为多少
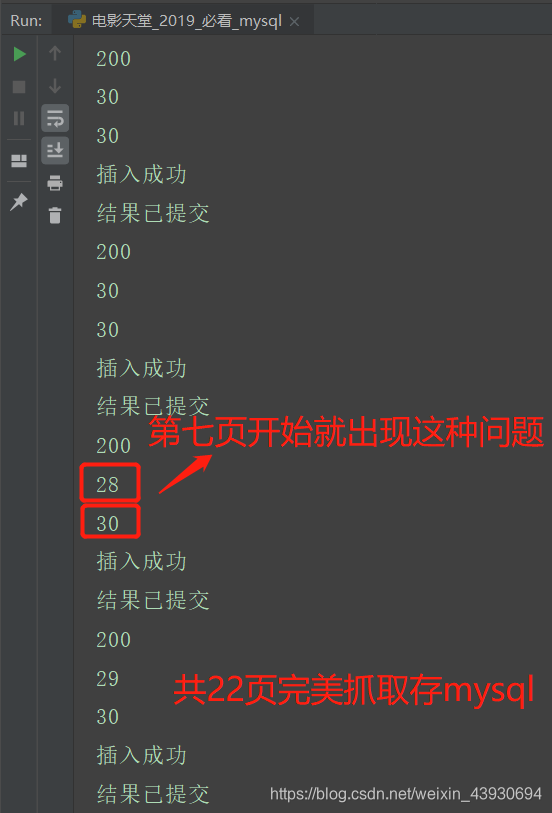
print(len(name))
print(len(info))
for i in range(len(name)): # 注意:坑2:第七页开始匹配的名字与链接数目不同,到现在我也不知道为什么!!
sql_2 = 'insert into Dy(name,info) values ("%s","%s")'
cursor.execute(
sql_2 % (name[i],info[i])
)
print("插入成功")
# 从游标中获取结果
cursor.fetchall()
# 提交结果
conn.commit()
print("结果已提交")
except Exception as e:
# 数据回滚
conn.rollback()
print("数据已回滚")
print(e)
# 关闭数据库
conn.close()
if __name__ == '__main__':
html_parse_save_sql()
二、运行结果:
三、查看数据库:
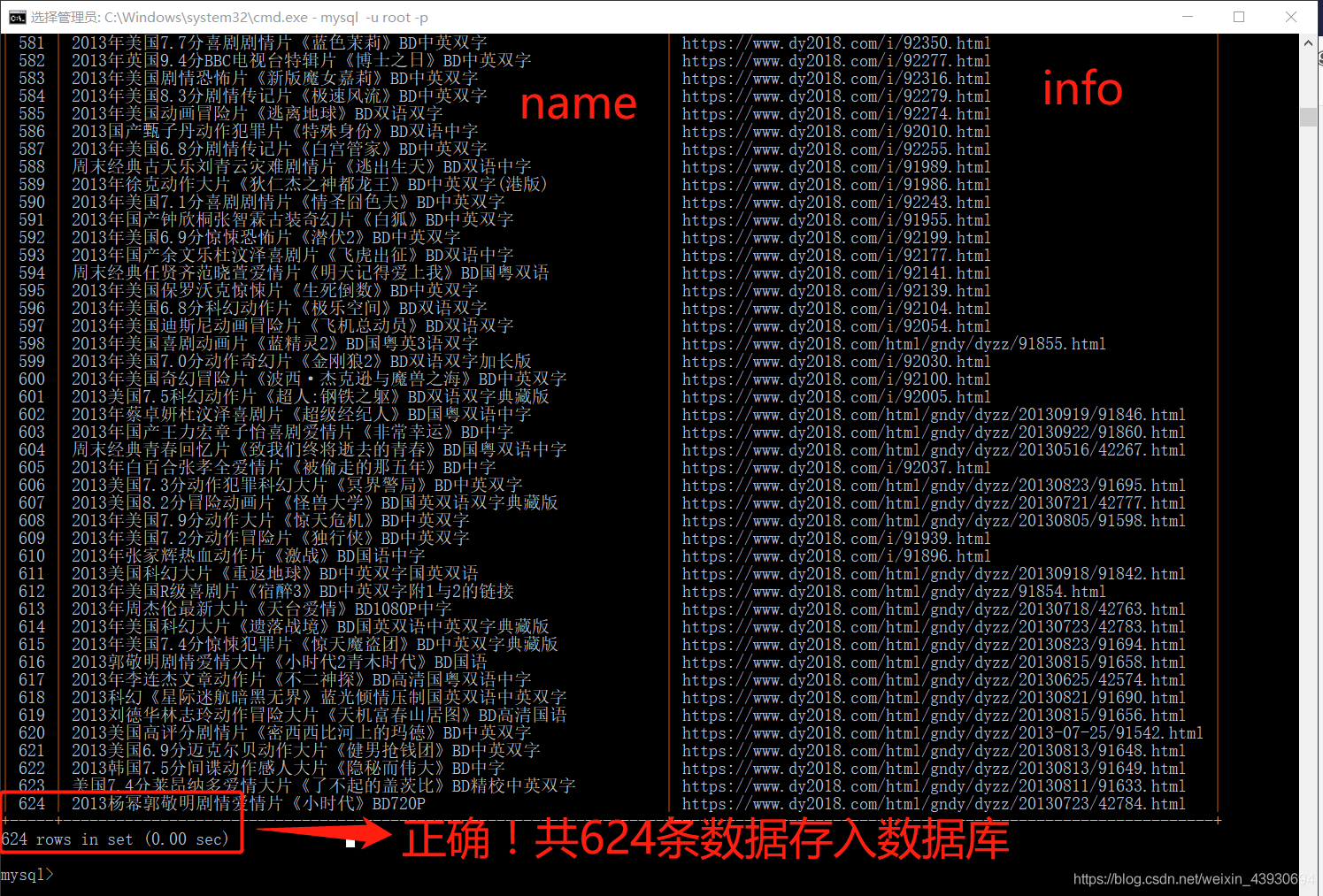
四、解决!
五、总结:
(1) 一定要结合异常处理分析出错,便于你快速知道错误原因。
(2) xpath解析一定不能加入tbody,否则匹配不了
(3)注意range()、len()的使用
