主机字节序与网络字节序
主机字节序(CPU 字节序)
概念
主机字节序又叫 CPU 字节序,其不是由操作系统决定的,而是由 CPU 指令集架构决定的。主机字节序分为两种:
- 大端字节序(Big Endian):高序字节存储在低位地址,低序字节存储在高位地址
- 小端字节序(Little Endian):高序字节存储在高位地址,低序字节存储在低位地址
存储方式
32 位整数 0x12345678 是从起始位置为 0x00 的地址开始存放,则:
| 内存地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 大端 | 12 | 34 | 56 | 78 |
| 小端 | 78 | 56 | 34 | 12 |
大端小端图片
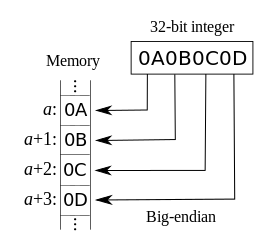
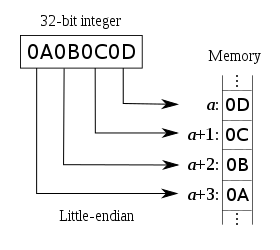
判断大端小端
判断大端小端
可以这样判断自己 CPU 字节序是大端还是小端:
#include <iostream>
using namespace std;
int main()
{
int i = 0x12345678;
if (*((char*)&i) == 0x12)
cout << "大端" << endl;
else
cout << "小端" << endl;
return 0;
}各架构处理器的字节序
- x86(Intel、AMD)、MOS Technology 6502、Z80、VAX、PDP-11 等处理器为小端序;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除 V9 外)等处理器为大端序;
- ARM(默认小端序)、PowerPC(除 PowerPC 970 外)、DEC Alpha、SPARC V9、MIPS、PA-RISC 及 IA64 的字节序是可配置的。
网络字节序
网络字节顺序是 TCP/IP 中规定好的一种数据表示格式,它与具体的 CPU 类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。
网络字节顺序采用:大端(Big Endian)排列方式。
TCP 与 UDP 的区别
- TCP 面向连接,UDP 是无连接的;
- TCP 提供可靠的服务,也就是说,通过 TCP 连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP 尽最大努力交付,即不保证可靠交付
- TCP 的逻辑通信信道是全双工的可靠信道;UDP 则是不可靠信道
- 每一条 TCP 连接只能是点到点的;UDP 支持一对一,一对多,多对一和多对多的交互通信
- TCP 面向字节流(可能出现黏包问题),实际上是 TCP 把数据看成一连串无结构的字节流;UDP 是面向报文的(不会出现黏包问题)
- UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 IP 电话,实时视频会议等)
- TCP 首部开销20字节;UDP 的首部开销小,只有 8 个字节
TCP 黏包问题
原因
TCP 是一个基于字节流的传输服务(UDP 基于报文的),“流” 意味着 TCP 所传输的数据是没有边界的。所以可能会出现两个数据包黏在一起的情况。
1:当连续发送数据时,由于tcp协议的nagle算法,会将较小的内容拼接成大的内容,一次性发送到服务器端,因此造成粘包
2:当发送内容较大时,由于服务器端的recv(buffer_size)方法中的buffer_size较小,不能一次性完全接收全部内容,因此在下一次请求到达时,接收的内容依然是上一次没有完全接收完的内容,因此造成粘包现象。解决
- 发送定长包。如果每个消息的大小都是一样的,那么在接收对等方只要累计接收数据,直到数据等于一个定长的数值就将它作为一个消息。
- 包头加上包体长度。包头是定长的 4 个字节,说明了包体的长度。接收对等方先接收包头长度,依据包头长度来接收包体。
- 在数据包之间设置边界,如添加特殊符号
\r\n标记。FTP 协议正是这么做的。但问题在于如果数据正文中也含有\r\n,则会误判为消息的边界。 - 使用更加复杂的应用层协议。
为什么客户端释放最后需要 TIME-WAIT 等待 2MSL 呢?
- 为了保证客户端发送的最后一个 ACK 报文能够到达服务端。若未成功到达,则服务端超时重传 FIN+ACK 报文段,客户端再重传 ACK,并重新计时。
- 防止已失效的连接请求报文段出现在本连接中。TIME-WAIT 持续 2MSL 可使本连接持续的时间内所产生的所有报文段都从网络中消失,这样可使下次连接中不会出现旧的连接报文段。
