现在随着各个企业积极的拥抱AI技术,那么其中一项关键的环节就是基于AI技术训练得到的各种模型对具体业务问题进行推理(model infer or prediction). 针对这个问题, 我想给大家分享一个基于spark on yarn with gpu的方案,能够充分的利用spark的大数据处理能力以及hadoop yarn的gpu调度的能力,轻易的扩展到更大的数据量以及更多的gpu并发支持。
框架版本:
- spark-3.0.0-preview2
- hadoop-3.2.1
- spark-tensorflow-connector_2.12-1.10.(spark-tensorflow-connector用于spark 解析tensorflow的TFRecord 格式.)
实际业务需求:
预先生成的TFRecord 格式的待标签识别的图像信息(imageId,imageBytes)
然后期望基于spark+hadoop yarn来基于标签识别模型对里面的图像进行标签识别,并且期望能够轻易的扩展到更多数量的gpu以提升速度。
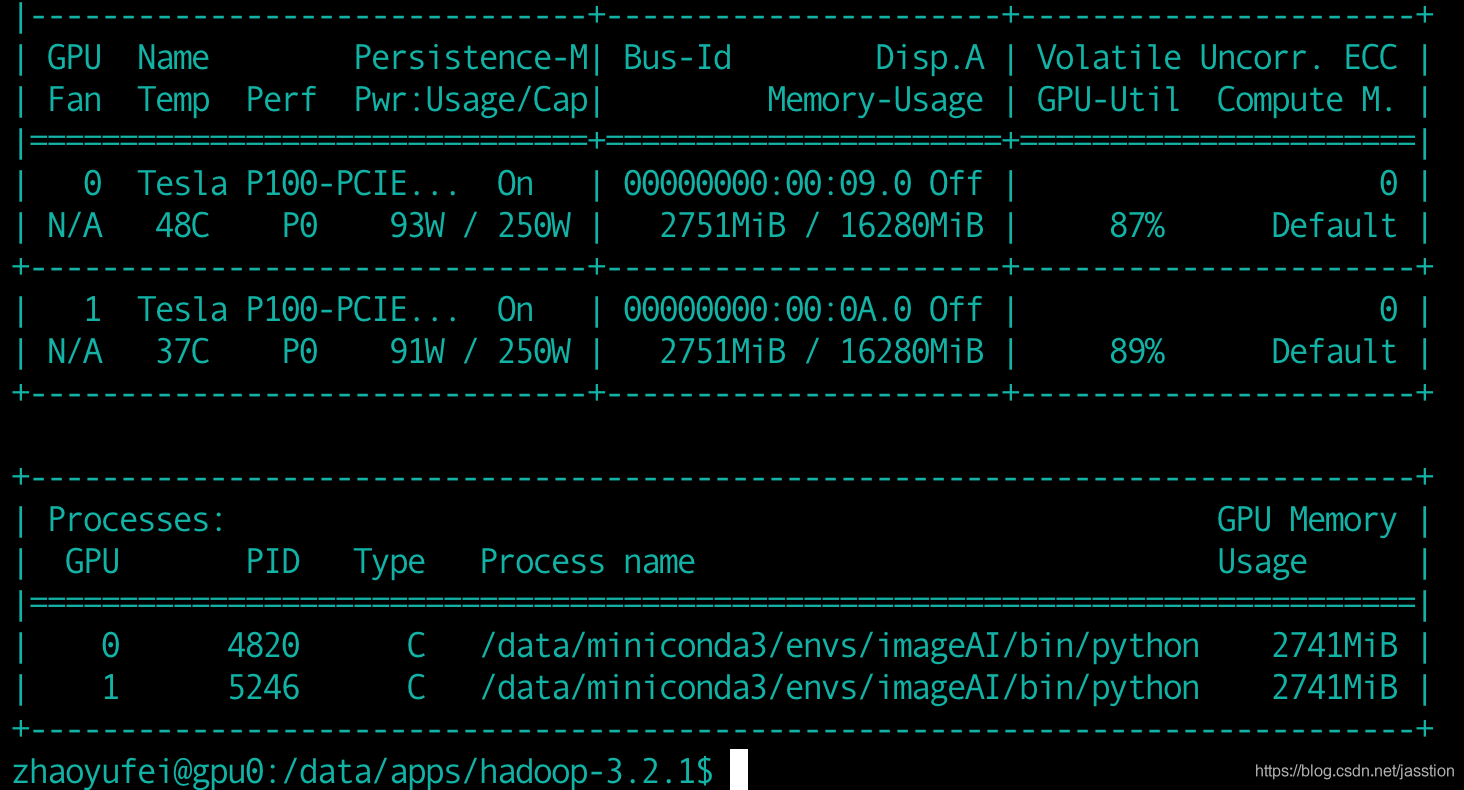
现在假设我们已经正确的安装了hadoop-3.2.1集群,配置好了spark-3.0.0的运行环境并且有一台服务器中有gpu资源(两个Tesla P100,内存:16280MB)。
pyspark 代码如下:
def testSparkTfrecordsOnYarn():
featuresFile='hdfs://host:9000/data/mlib_data/getty/features_test'
tfrecordsFile='hdfs://host:9000/data/mlib_data/getty/images_test_tfrecords/part-r-00000'
fields = [StructField("imageId", StringType()),
StructField("imageBytes", BinaryType()),
StructField("label", StringType())
]
schema = StructType(fields)
df = spark.read.format("tfrecords").option("recordType", "Example").schema(schema).load(tfrecordsFile).persist(
storageLevel=StorageLevel.MEMORY_ONLY)
print(df.rdd.getNumPartitions())
# print(df.count())
def modelInfer(rows):
from vcgImageAI.subProjects.comm.vcgModels import getModel
config = {}
tencentMultiLabelModel = getModel(config)
results=[]
for row in rows:
try:
imageId = row.imageId
imageBytes = row.imageBytes
start = time.time()*1000.0
image_data_array = [tencentMultiLabelModel.preProcess(imageBytes)]
end = time.time()*1000.0
print('preProcess spent time: %d' % (end - start))
start = time.time()*1000.0
features = tencentMultiLabelModel.getFeatures(image_data_array=image_data_array)
end = time.time() * 1000.0
print('modelInfer spent time: %d' % (end - start))
feature = [str(x) for x in features[0]]
featuresStr = ','.join(feature)
result = Row(imageId=imageId,features=featuresStr)
print(result)
results.append(result)
except BaseException as e:
print('modelInfer error:%s' % str(e))
continue
print('result number: %d' % len(results))
return results
features_df=df.rdd.mapPartitions(lambda rows : modelInfer(rows=rows),preservesPartitioning=True).persist(
storageLevel=StorageLevel.MEMORY_ONLY).toDF()
# print('features_df count: %s' % features_df.count())
features_df.write.format("com.databricks.spark.csv").option("header", "True").option("delimiter",
'\t').mode(
"overwrite").save(featuresFile)
看过上面的代码或许大家已经想到思路了,就是让spark 的每个executor运行在每个yarn集群中的 一个gpu上面, 然后每个executor可以根据gpu的内存大小运行多个task, 只要确保一个executor中的所有 task的模型的内存小于当前的gpu的内存就行(16G)
因为模型的初始化和载入是比较浪费时间的,所以我们采用的是spark的mapPartitions instead of map, 另外我们还需要针对我们自己的数据集选择合理的partitionNum,不能太大, 也不能太小, 太大的话可能会导致内存溢出,太小的话会导致频繁的模型初始化和载入。
然后下面就是提交运行命令:
nohup spark-submit --master yarn --py-files hdfs://172.16.241.100:9000/data/stuff/vcgPylibary.tar.gz --deploy-mode cluster --name zhaoyufei_gettml --num-executors 1 --executor-cores 1 --executor-memory 10G --conf spark.executor.resource.gpu.amount=1 comm.py > ./out &上面的命令中有几个参数特别重要分别是:
- py-files
- deploy-mode
- num-executors
- executor-cores
- spark.executor.resource.gpu.amount
py-files是你提交的代码现在是comm.py所有的依赖, 比如:tensorflow, pytorch,你自己的python libary等
deploy-mode表示你选择将spark driver本地运行还是放到hadoop yarn中的容器运行, 当前的选择是cluster,在容器中运行。
num-executors:根据你hadoop yan集群中可用的gpu数据来确定
executor-cores:根据你gpu的内存确定, 比如如果内存大的话可以考虑同时运行几个model infer 的 task
spark.executor.resource.gpu.amount:这个是固定的, 每个spark executor (也是每个yarn container)使用一个gpu