聚类分析的概念
聚类分析是根据“物以类聚”的道理,对样本或指标进行分类的一种多元统计分析方法,它们讨论的对象是大量的样本,要求能合理地按各自的特性进行合理的分类,没有任何模式可供参考或依循,即在没有先验知识的情况下进行的。比如说;
谁经常光顾商店,谁买什么东西,买多少?
按会员卡记录的光临次数、光临时间、性别、年龄、职业、购物种类、金额等变量分类
这样商店可以……
识别顾客购买模式(如喜欢一大早来买酸奶和鲜肉,习惯周末时一次性大采购)
刻画不同的客户群的特征
怎样进行分类?
关于变量的分类,有两种方法
一种叫相似系数分类,性质越接近的变量或样本,它们的相似系数越接近于1或一l,而彼此无关的变量或样本它们的相似系数则越接近于0,相似的为一类,不相似的为不同类。
另一种叫距离分类,它是将每一个样本看作p维空间的一个点,并用某种度量测量点与点之间的距离,距离较近的归为一类,距离较远的点应属于不同的类。
变量间距离计算方法
绝对距离
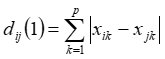
欧式距离
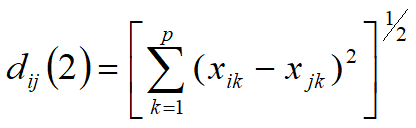
明考斯基距离
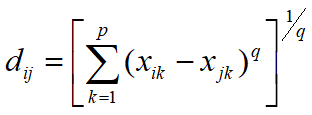
…
变量间相似系数计算方法
1.相关系数
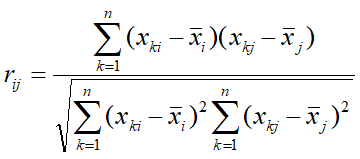
2.夹角余弦
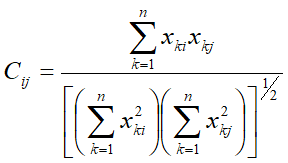
分类方法
分类可以根据对象不同,根据变量间相似系数叫R型聚类;根据样本间距离分类间Q型聚类。
也可以根据方法不同,分为:系统聚类:又称为层次聚类(hierarchical
cluster)(静态聚类);
K均值聚类( K-means Cluster )(动态聚类)
本文按方法的不同进行分类。
层次聚类(hierarchicalcluster)(静态聚类)
层次聚类方法
层次聚类是指聚类过程是按照一定层次进行的。 系统聚类法不仅需要度量个体与个体之间的距离,还要度量类与类之间的距离。类间距离被度量出来之后,距离最小的两个小类将首先被合并成为一类。由类间距离定义的不同产生了不同的系统聚类法。
通过计算类间的距离进行不断进行迭代聚合分类。
类间的距离计算方法有:
最短距离法(Nearest Neighbor)
最长距离法(Further Neighbor)
间平均连接法(Between-group linkage)
组内平均连接法(Within-group linkage)
重心法(Centroid clustering)
中位数法(Median clustering)
离差平方和法(Ward’s method)
spss实现
以笔者丽水山耕统调分析数据为例

点击分析-分类-系统分层聚类-分层时点击树状图

如图,按年龄对399个样本进行分类。
K均值聚类
K-均值聚类也叫快速聚类
要求事先确定分类数
运算速度快(特别是对于大样本)
系统首先选择k个聚类中心,根据其他观测值与聚类中心的距离远近,将所有的观测值分成k类;再将k个类的中心(均值)作为新的聚类中心,重新按照距离进行分类;……,这样一直迭代下去,直到达到指定的迭代次数或达到中止迭代的判据要求时,聚类过程结束。
spss实现
分析-分类-k均值聚类(笔者选用的聚类中心为4个,选用ANOVA检验其显著性)

4类中心,ANOVA图中Sig<0.05时说明变量间具有显著性

每类个例数
总结
K均值聚类优点: 算法原理简单,处理快当聚类密集时,类与类之间区别明显,效果好
缺点: K是事先给定的,K值选定难确定;对孤立点、噪声敏感;结果不一定是全局最优,只能保证局部最优;很难发现大小差别很大的簇及进行增量计算;结果不稳定,初始值选定对结果有一定的影响
计算量大
层 次聚类较大的优点,就是它一次性地得到了整个聚类的过程,只要得到了上面那样的聚类树,想要分多少个cluster都可以直接根据树结构来得到结果,改变 cluster数目不需要再次计算数据点的归属。层次聚类的缺点是计算量比较大,因为要每次都要计算多个cluster内所有数据点的两两距离。另外,由 于层次聚类使用的是贪心算法,得到的显然只是局域最优,不一定就是全局最优,这可以通过加入随机效应解决,这就是另外的问题了。
参考链接
https://www.cnblogs.com/nku-wangfeng/p/7642745.html
https://blog.csdn.net/wsp_1138886114/article/details/80475981
