众所周知,每种基本数据类型都有一个固定的位数,比如byte占8位,short占16位,int占32位等。正因如此,当把一个低精度的数据类型转成一个高精度的数据类型时,必然会涉及到如何扩展位数的问题。这里有两种解决方案:
(1)补零扩展:填充一定位数的0。
(2)补符号位扩展:填充一定位数的符号位(非负数填充0,负数填充1)。
对于无符号类型(相当于都是非负数)与有符号类型中的非负数部分,这两种方法没有区别,都是填充0;对于有符号类型中的负数部分,这两种方法就会产生差异了,补零扩展会填充0,而补符号位扩展会填充1。下面将byte类型的-127转为int类型为例,探讨一下这两种方法的区别。
首先必须明确一些知识点:
- 计算机是用补码来存储数字的;
- 正数的补码等于原码;
- 负数的补码等于反码+1;
- 一个数的补码的补码等于原码。
符号扩展
符号扩展是计算机算术中在保留数字的符号(正/负)和值的同时增加二进制数的位数的操作。 这是通过根据所使用的特定带符号的数字表示的过程,将数字附加到数字的最高有效位来完成的。
例如,如果使用六位表示数字“ 00 1010”(十进制正数10),并且符号扩展操作将字长增加到16位,则新的表示形式就是“ 0000 0000 0000 1010”。因此,既保持了价值,又保持了价值为正的事实。
如果用10位表示用二进制补码值“1111110001”(十进制负15),并且将其符号扩展为16位,则新表示为“1111 1111 1111 0001 ”。因此,通过在左侧填充ones,可以保持负号和原始编号的值。 1111 1111 1111 0001
例如,在Intel x86指令集中,有两种方式进行符号扩展:
- 使用指令cbw,cwd,cwde和cdq:分别将字节转换为字,将字转换为双字,将字转换为扩展双字和将双字转换为四字(在x86上下文中,一个字节有8位,一个字有16位,一个双字和扩展的双字32位和四字64位);
- 使用由movsx(“带符号扩展的移动”)指令系列完成的符号扩展移动之一。
零扩展
在移动或转换操作中,零扩展是指将目标的高位设置为零,而不是将其设置为源的最高有效位的副本。 如果操作的源是无符号数字,则零扩展通常是在保留其数值的同时将其移至更大字段的正确方法,而符号扩展对于有符号数字是正确的。
在x86和x64指令集中,movzx指令(“零扩展移动”)执行此功能。 例如,movzx ebx,al将一个字节从al寄存器复制到ebx的低位字节,然后用零填充ebx的其余字节。
在x64上,大多数写入任何通用寄存器的低32位的指令都会将目标寄存器的高一半置零。 例如,指令mov eax,1234将清除rax寄存器的高32位。
实例
举个例子:
127原码1111 1111,反码1000 0000,补码1000 0001。计算机存储的是1000 0001,用十六进制表示为0x81。
- 当使用补零扩展时,结果为:
0000 0000 0000 0000 0000 0000 1000 0001
用十六进制表示为0x81。为了计算十进制值,计算它的补码,结果为:
0000 0000 0000 0000 0000 0000 1000 0001
将这个二进制数转成十进制的结果是129。
- 当使用补符号位扩展时,结果为:
1111 1111 1111 1111 1111 1111 1000 0001
用十六进制表示为0xFFFFFF81。为了计算十进制值,计算它的补码,结果为:
1000 0000 0000 0000 0000 0000 0111 1111
将这个二进制数转成十进制的结果是-127。
由此可以得出结论:
(1)使用补零扩展能够保证二进制存储的一致性,但不能保证十进制值不变。
(2)使用补符号位扩展能够保证十进制值不变,但不能保证二进制存储的一致性。
在C/C++中,如果把一个char向一个整形转换的时候,就会存在着这个问题。
如果你想得到一个正数,那么如果一个字符的ASCII码值是小于零的,而直接用(int)c进行强制类型转换,结果是通过符号扩展得到的也为一个负数。
要得到正数,一定要用(int)(unsigned char)c;因为unsigned char去除了c的符号位,所以,这样的类型转换后,再用(int)进行转换得到的就是一个正数。
#include <iostream>
#include <string>
#include <algorithm>
#include <bitset>
int main()
{
int i = 129;
char chA = (char)i;
int c = (int)(unsigned char)chA;
int b = (int)chA;
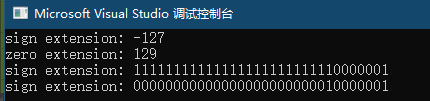
std::cout << "sign extension: " << b << std::endl;
std::cout << "zero extension: " << c << std::endl;
char d = -127;
std::bitset <sizeof(int) * 8> x(d);
std::cout << "sign extension: " << x << std::endl;
unsigned char e = (d & 0XFF);
std::bitset <sizeof(int) * 8> y(e);
std::cout << "sign extension: " << y << std::endl;
return 0;
}结果
std::bitset
std::bitset 是 一种 位集存储位(元素只有两个可能的值:0或1 true或false,...)。
- bitset存储二进制数位。
- bitset就像一个bool类型的数组一样,但是有空间优化——bitset中的一个元素一般只占1 bit(在大多数系统上,相当于一个char元素所占空间的八分之一,一个char占用一个字节byte,8位bits)
- bitset中的每个元素都能单独被访问,例如对于一个叫做foo的bitset,表达式foo[3]访问了它的第4个元素,就像访问了数组其元素一样。但是,因为在大多数C ++环境中没有元素类型是单个位,所以可以将单个元素作为特殊引用类型进行访问(请参见bitset :: reference)。
- bitset具有可以从整数值和二进制字符串构造并转换为整数值的功能(请参阅其构造函数和成员to_ulong和to_string)。它们也可以直接以二进制格式插入和从流中提取(请参阅适用的运算符)。
- bitset的大小在编译时就需要确定(由其模板参数确定)。有关还可优化空间分配并允许动态调整大小的类,请参见vector的布尔特殊化(vector <bool>)。
参考:
