绪论
在使用spring或者springboot项目开发中,经常通过注入的方式完成一个bean对另一个bean的引用,比如classA中药注入B的bean,写法如下
@Autowired
private B b
而B中要注入A的话就是下面的写法了
@Autowired
private A a
用法非常简单,一目了然,用习惯了就成自然了,觉得就是那么回事,但小编最近读了点儿spring源码,就想搞清楚spring怎么就那么聪明,你那样用就可以完成注入呢?
现在我想探讨的是另一个问题,当在class A 中注入B,同时在class B中注入A,如果按照spring的bean的生命周期的过程去分析,发现这个问题竟然是循环依赖,按照我的理解和对spring ioc的一点研究,这就是成了死循环了啊,那么spring是怎么解决这个问题呢?这个问题很重要也很有意思,我们先来看看下面这张简图:

上述这幅图从直观的理解上描述了一个看似bug的问题,就是循环注入依赖,首先我们通过代码来看一个简单的例子吧,代码非常简单,两个被spring管理的类,一个启动类,一个配置类用于扫描包结构
AppConfig代码:
@Configuration
@ComponentScan("com.congge.v1")
public class AppConfig {
}
X 和Y 的代码过于简单,直接贴上去了,大家可以随意命名都没问题的,能够被spring扫描到就可以
@Component
public class X {
@Autowired
Y y;
public X(){
System.out.println("X class create");
}
}
@Component
public class Y {
@Autowired
X x
public Y(){
System.out.println("Y class create");
}
}
测试启动类 MainTest2
public class MainTest2 {
public static void main(String[] args) {
/*AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(AppConfig.class);
ac.refresh();*/
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(AppConfig.class);
ac.refresh();
}
}
直接运行这段代码,先看看效果再说

代码正常运行,并且打印出了各自类的构造函数信息,从效果来看,spring不仅完成了循环依赖,而且可以得到我么预期的效果,那么上面图示中的理解是哪里有问题呢?带着这个疑问我们来看看代码,
我们知道,spring中有一套管理每一个bean的完整的生命周期的机制,正是通过spring对bean的生命周期的维护,使得bean最终可以完成许多复杂的功能,下面首先贴上个人对spring创建bean的生命周期的理解

上述是通过源码的断点调试结合官网的相关资料做出,可能存在不足之处,通过一个bean的生命周期去理解依赖注入可能更容易点,下面我们通过断点来调试一下依赖注入的过程
按照第一张图的理解,循环注入的步骤大概分为下面几步,
- 创建beanX
- beanX在实例化过程中需要注入Y,即Y作为一个属性将注入到X中,但Y必须是一个Bean
- X注入Y的时候直接从单例池getBean(Y),但是拿不到,就需要调用createBean(Y)
- beanY创建过程中同样需要注入beanX,于是从单例池获取X,但发现也没有拿到
调试过程中,始终记得上述的步骤和流程才好调试出来效果,为了方便调试,可以在关键的步骤添加条件判断,可以节约时间
1、创建beanX
具体的调用链路可以通过源码跟踪,我这里直接走进开始创建beanX的步骤,
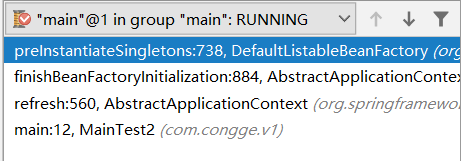
进入方法preInstantiateSingletons()创建beanX

进入getBean方法中,通过调用栈最终来到doGetBean方法,

如备注所说,初次获取bean肯定拿不到,因为createBean的方法都还没有调用呢,在这个方法中继续走下去,走到createBean的地方,注意的是,这里有一个getSingleton,是解决循环依赖的第一个突破口,当然我们首先关注的是createBean方法,

进入createBean方法中,我们重点要关注的是下面创建bean的方法,因为在这个方法中,将会完成bean的依赖注入的过程

继续进入doCreateBean方法,在该方法中,需要重点关注populateBean这个方法,这个方法中,其中要做的一件事就是当某个bean中注入了其他的bean的时候,其他的bean将会被当做这个bean的一个属性,完成类似setBean的功能

那么截止到这里,仅仅完成了new X的功能,继续该方法,就进入了第一张图中的注入beanY的逻辑了,怎么注入呢?下面就又开始重复上面的步骤了,即从单例池获取beanY,肯定获取不到啊,只好继续创建beanY的过程了,那么我们直接进入getBean的方法中吧,当我直接F8的时候,直接跳转到getBean的方法了,这个和上第一张图的差不多

下面继续createBean(Y)的流程吧,和上面的一样,在createBean(Y)的最终,由于Y中也注入了X,因此X也将会作为一个属性被set到Y中去,set之前还是要从单例池取一遍的,因此直接F8走完创建bean的流程来到doGetBean的方法中,

这一次,我们不打算直接跳过getSingleton这个方法了,要知道spring可以完成循环注入依赖的功能,肯定是在某个地方秘密的暂存了,或者是可以通过某种方式建造出来,既然前几步中X和Y的对象实例化过程都已经完成了

至少可以猜想,通过这个方法应该可以把X的bean给弄出来了吧?按照猜想,我们进入这个方法,于是我们看到一个令人惊讶的事情,在之前调试的时候,这个方法从来没有进来过(可能是没有试过循环依赖),但这里就过来了,问题的关键就在isSingletonCurrentlyInCreation这个方法中

顾名思义,这个方法表示:当前的这个bean是不是在创建过程中呢?如果是,就走里面的额逻辑,我们不禁猜想,既然传入一个beanName就可以创建出beanX或者beanY,那么肯定在某个时刻,在某个标识正在创建bean的集合中,把bean的名称存进去了,这个就是前面在createBean的方法中那个划重点的地方,请进入getSingleton方法目睹一下真像,很明显,在创建之前,要先从那个“池”中获取一次,然后放入标识正在创建的"池"中

这样就可以继续下去了,接着断点走完这个方法,走完后我们发现,X的bean就被创建出来了

到底是怎么创建出来的呢?通过下面这段代码,传入beanName就可以将bean创建出来了,这里涉及到spring的bean的多级缓存,先卖个关子,后面会对多级缓存做一篇分析说明,简单来说,多级缓存主要分为3种:singletonObjects(一级缓存,单例缓存池),singletonFactories(二级缓存,存放的是工厂),earlySingletonObjects(存放临时对象,比如正在创建过程中的bean),

那么经过这个方法之后,beanX就创建出来了,后面的流程就可以一路通畅的走下去了,

基本上到这里,我们通过一路的源码调试,将spring的循环依赖注入的底层原理简单分析了一下,虽然看起来比较简单,但是只有弄懂了整个代码执行的顺序流程,才好调试和模拟出来,最后下一个问题:为什么通过传入一个beanName就可以在工厂中创建出一个bean?有兴趣的同学可以稍作研究一下,本篇到此结束,最后感谢观看!
