任务来袭
了解基本语言
内容:
- 使用phpstudy软件搭建php环境;
- 了解php基本语法知识;
- 安装python语言环境;
- 阅读requests库文档;
- 写出百度搜索结果爬虫脚本;
使用phpstudy软件搭建php环境
-
首先安装phpstudy
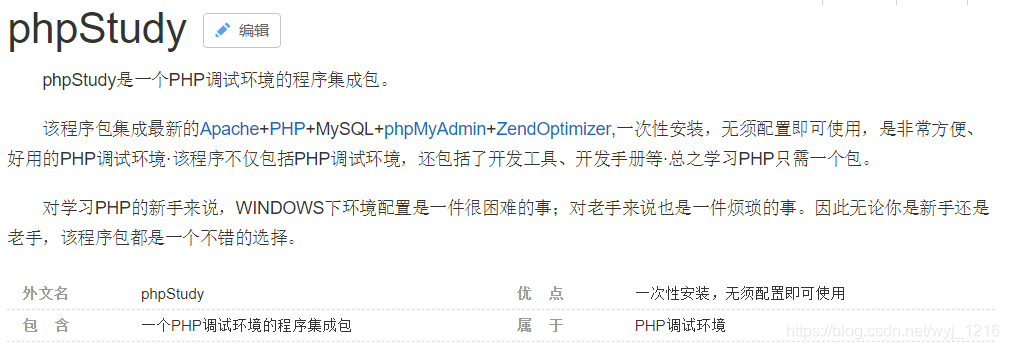
- 什么是phpstudy呢?百度了一下,解释如下:
- 安装:http://www.php.cn/xiazai/gongju/845
根据提示一步一步进行安装就好了
- 什么是phpstudy呢?百度了一下,解释如下:
-
phpstudy的简单使用
-
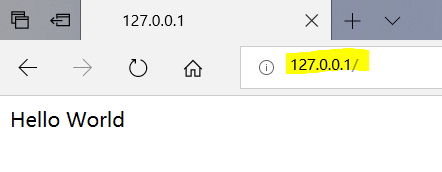
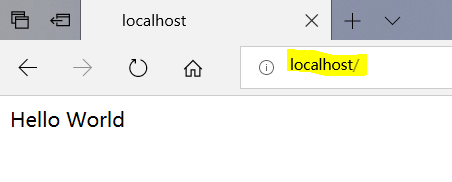
在地址栏输入127.0.0.1或者localhost(即本机)会出现下面结果
-
更改端口
在“其他选项菜单”中找到“软件设置”、“端口常规设置”
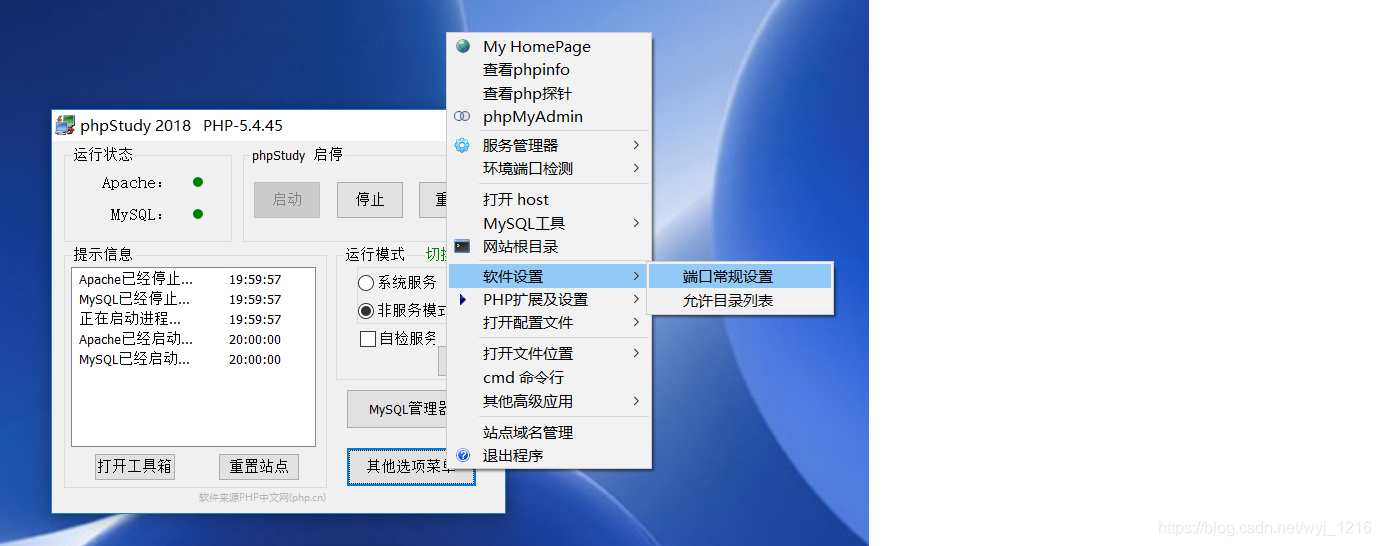
看到默认端口为80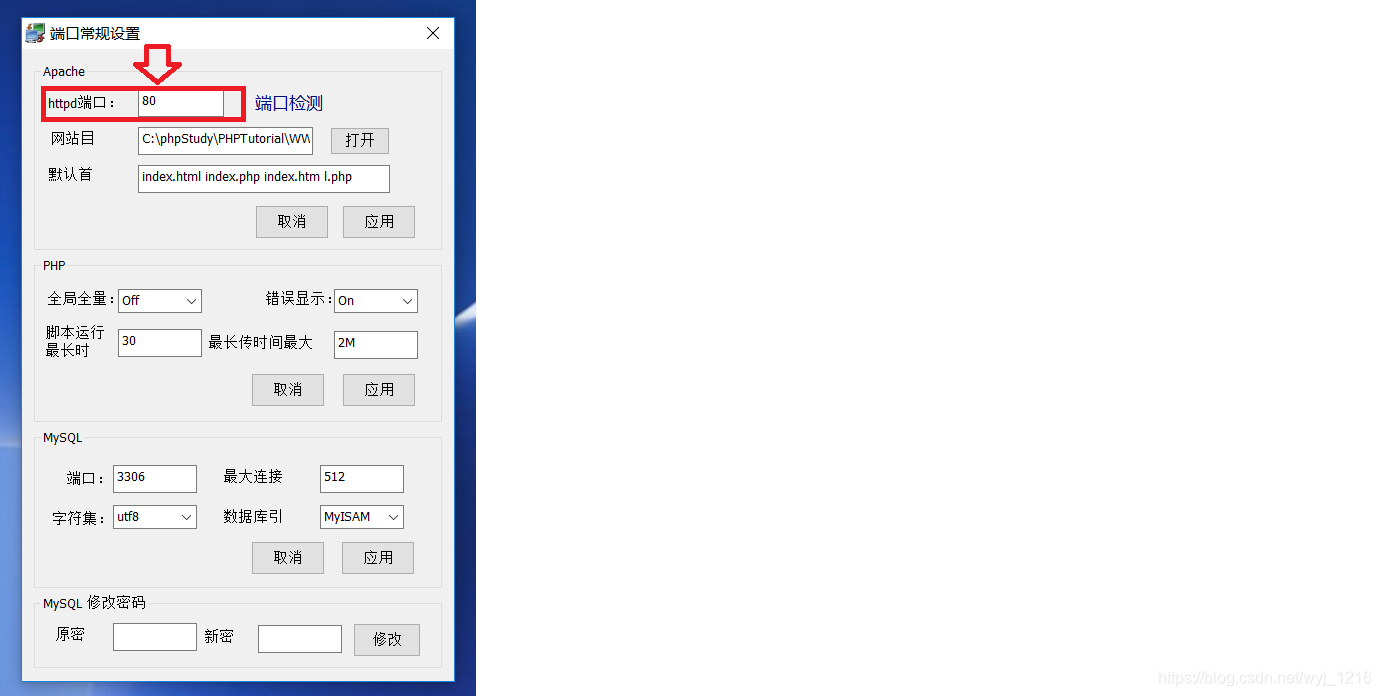
更改端口值,相应的地址栏输入也要进行更改:
localhost:端口号/xxx.php
(当端口值为80时,可以为:localhost/xxx.php ) -
更改目录
一般默认C:\phpStudy\PHPTutorial\WWW为放代码的地方,倘若将这里路径进行更改,一定要记得将WWW文件下的相应代码复制到更改的文件下,不然会报错哦
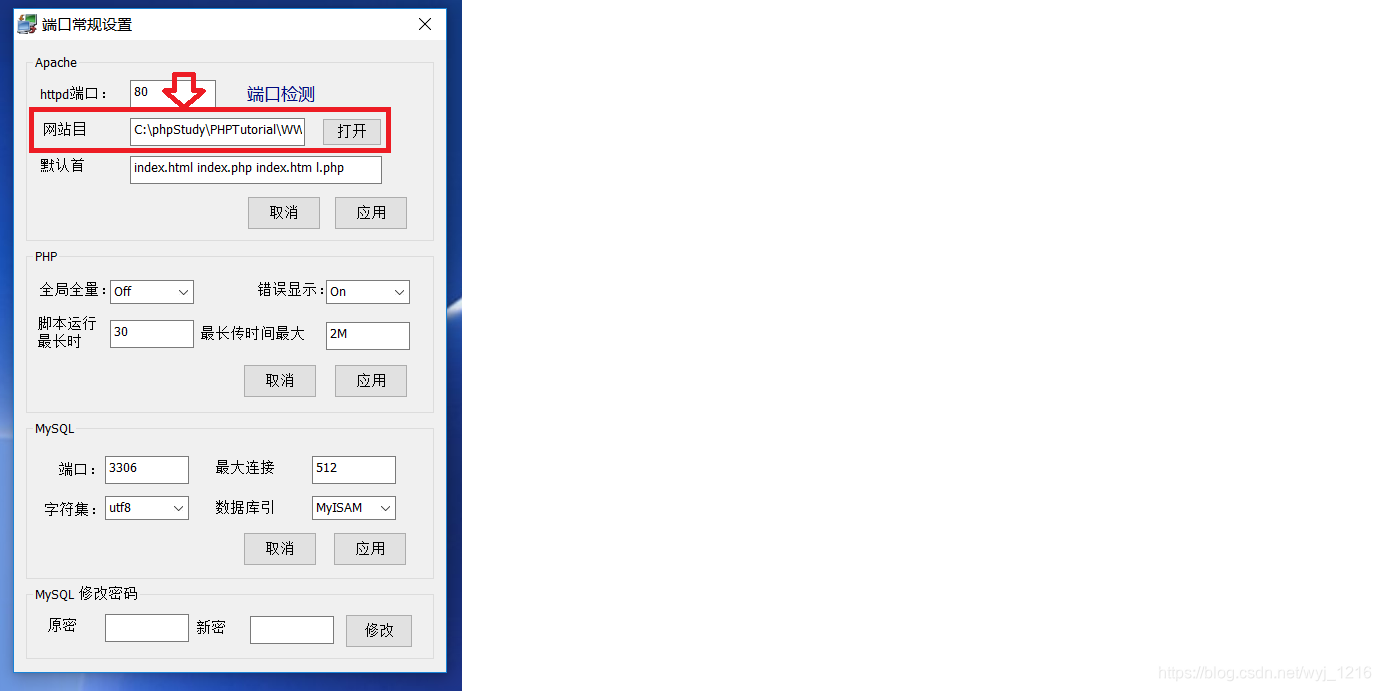
-
更改页面内容
首先在默认首页里进行更改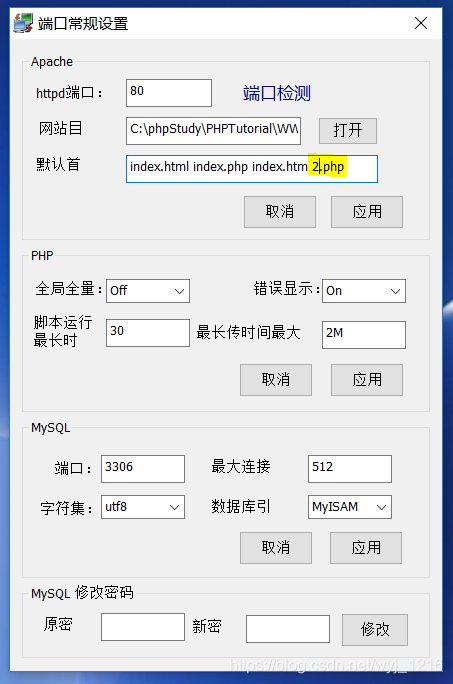
再在WWW下将相应的文件代码进行修改
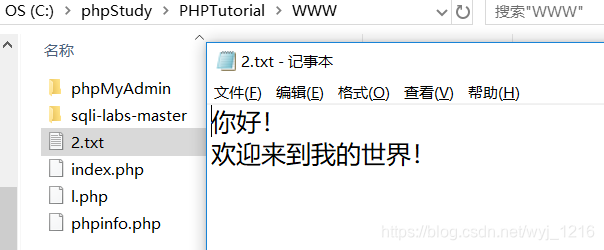
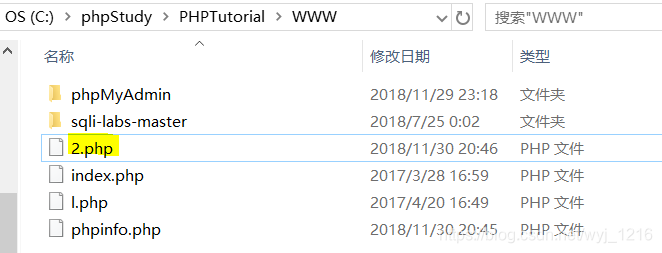
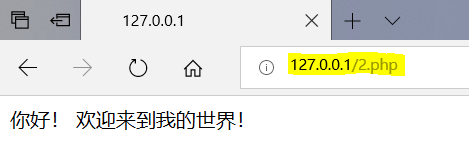
再次打开就是更改后的首页了
-
-
在这里推荐一篇大佬的博客:
https://blog.csdn.net/williamgavin/article/details/79176325
了解php基本语法知识
php以<?php开始,以?>结束,每一行代码都必须以分号结束。
<!DOCTYPE html>
<html>
<boby>
<h1>这是我的第一个PHP页面</h1>
<?php
echo "Hello World";//两种在浏览器输出文本的基础指令:echo print
//这是一行注释
/*
这
是
多
行
注
释
*/
?>
</boby>
</html>
php变量
以$符号开始,后接变量名称
PHP没有声明变量的命令,在第一次被赋值时被创建
PHP会根据变量的值,自动把变量转换成正确的数据类型
PHP有四种不同的变量作用域:
local global static parameter
局部作用域、全局作用域
- 在所有函数外部定义的变量是全局变量,可被脚本中的任何部分访问(访问需使用global关键字)
- 在函数内部生命的变量是局部变量,仅在该函数内部被访问
- 当一个函数完成时,其所有变量都会被删除。若不希望摸个局部变量被删除,可以使用static关键字。
- 参数作用域:参数是通过调用代码将值传递给函数的局部变量,是在参数列表中生声明的,作为函数声明的一部分。
<?php
$x=5;//全局变量
function mytest()//参数作用域:function mytest($y)
{ //若在函数内部调用函数外的全局变量,应为:global $x;
$y=8;//局部变量、不被删除:static $y=8;
echo "<p>测试变量在函数内部:<p>';
echo "变量x为:$x";
echo "<br>";
echo "变量y为:$y";
}
mytest();
echo "<p>测试变量在函数外部:<p>";
echo "变量x为:$x";
echo "<br>";
echo "变量y为:$y";
?>
输出语句
- echo 可以输出一个或多个字符串,速度快,无返回值
- print 只允许输出一个字符串,返回值总为1
数据类型
- String(字符串)
- Integer(整型)
- Float(浮点型)
- Boolean(布尔型)
- Array(数组)
- Object(对象)、NULL(空值)
常量
在脚本中,值不可改变,在整个脚本中均可使用。
设置常量,用define()函数:
define(string constant_name,nixed value,case_sensitive=true)
其中,constant_name,必选参数,常量名称,即标志符;value,必选参数,常量的值;case_sensitive,可选参数,指定是否大小写敏感,设定为 true 表示不敏感。
安装python语言环境
在cmd界面下,打开python
>python
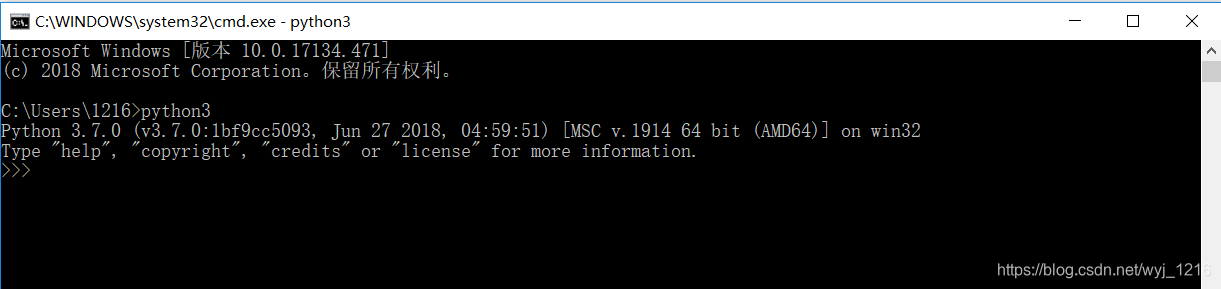
(我这里设置为python3)
若得不到相应的正确显示,要手动添加环境变量
“此电脑”右键“属性”,找到“高级系统设置”,点击“环境变量”
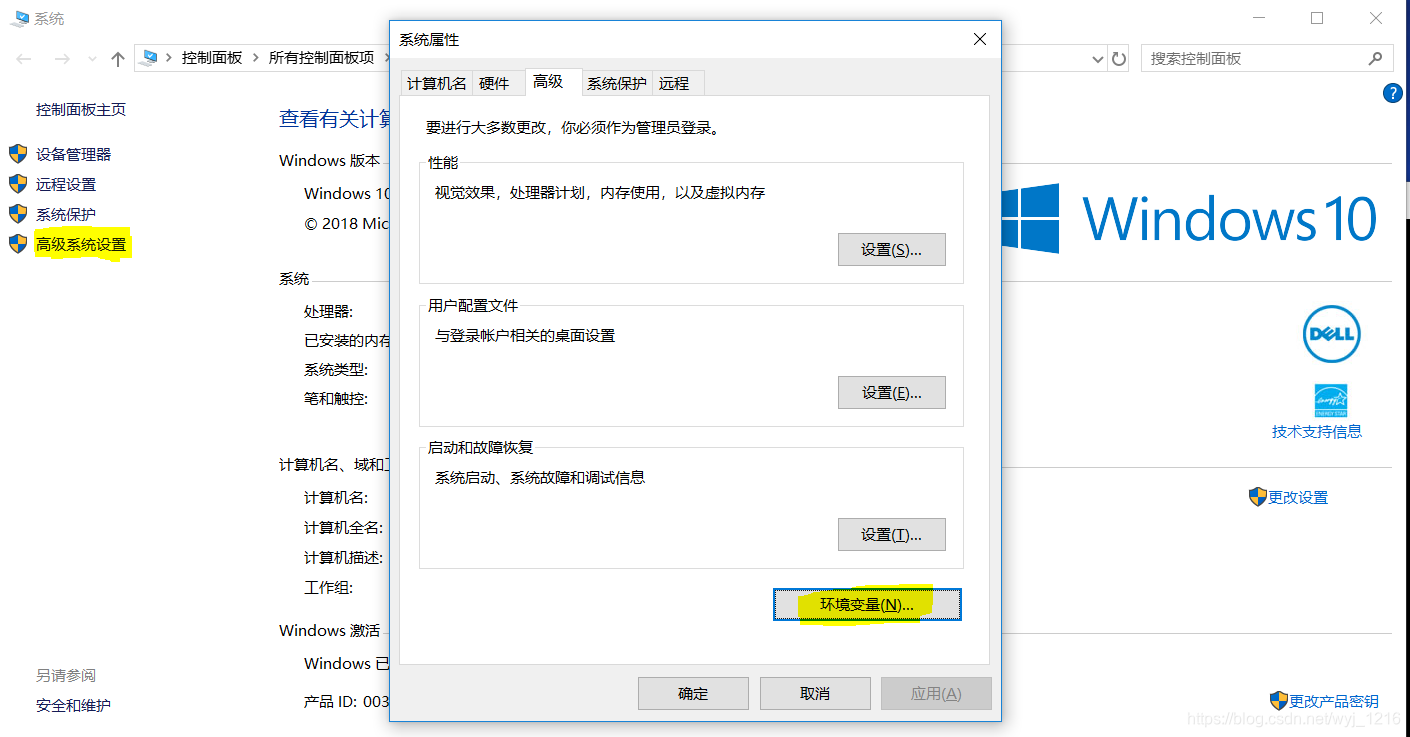
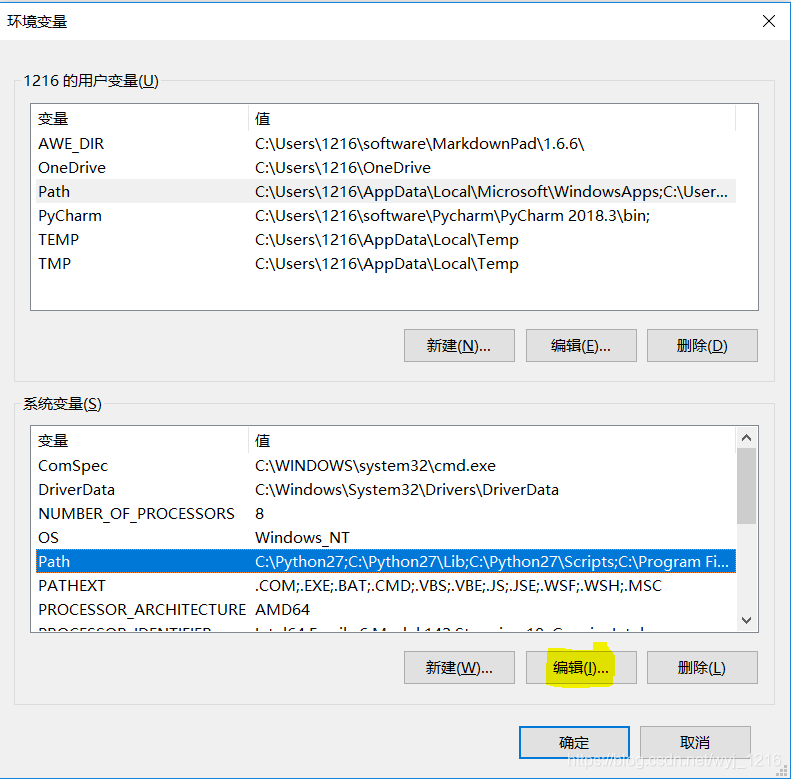
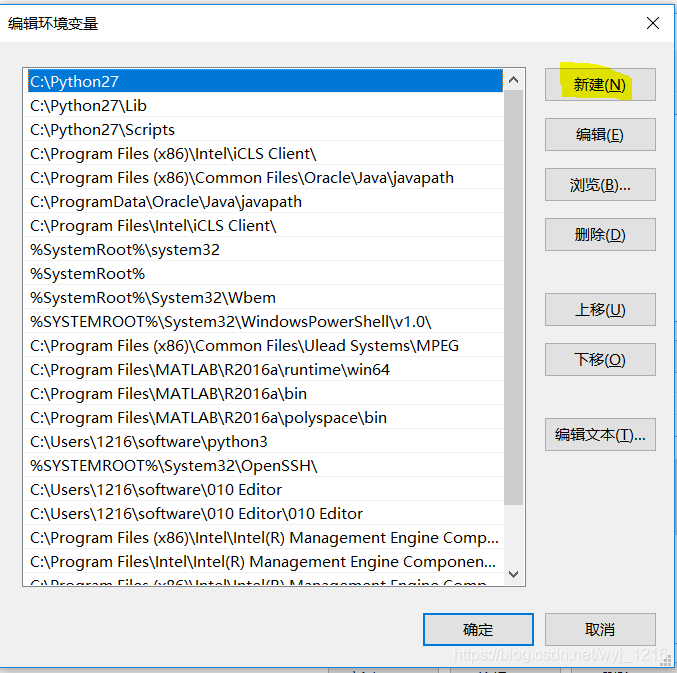
找到“path”点击“编辑”,点击“新建”,将文件路径添加进去
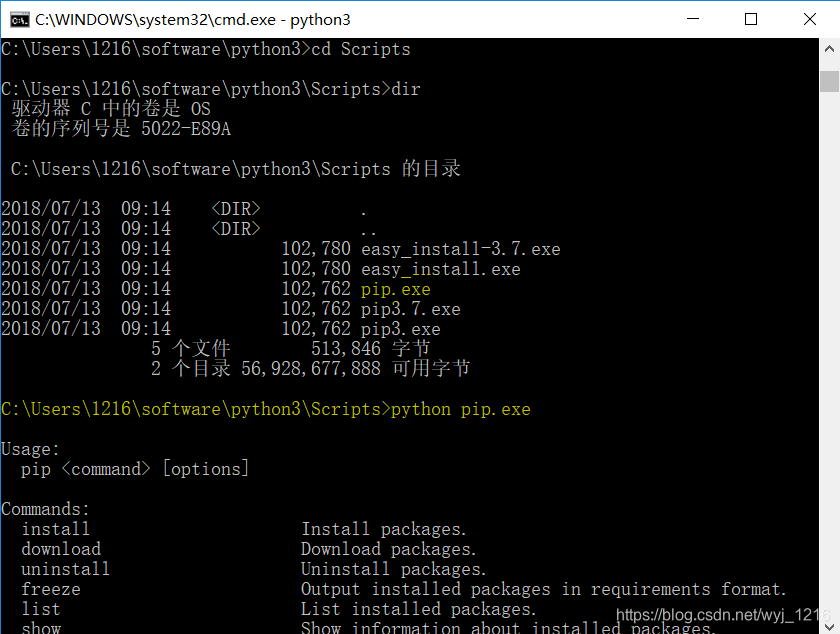
接下来安装pip,找到并打开python目录,找到Scripts,打开
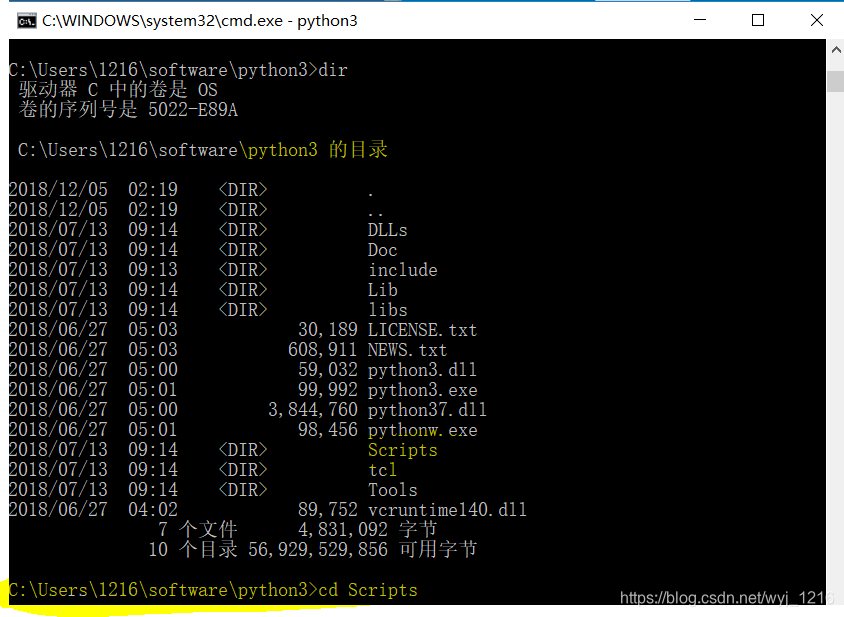
找到pip.exe,并运行
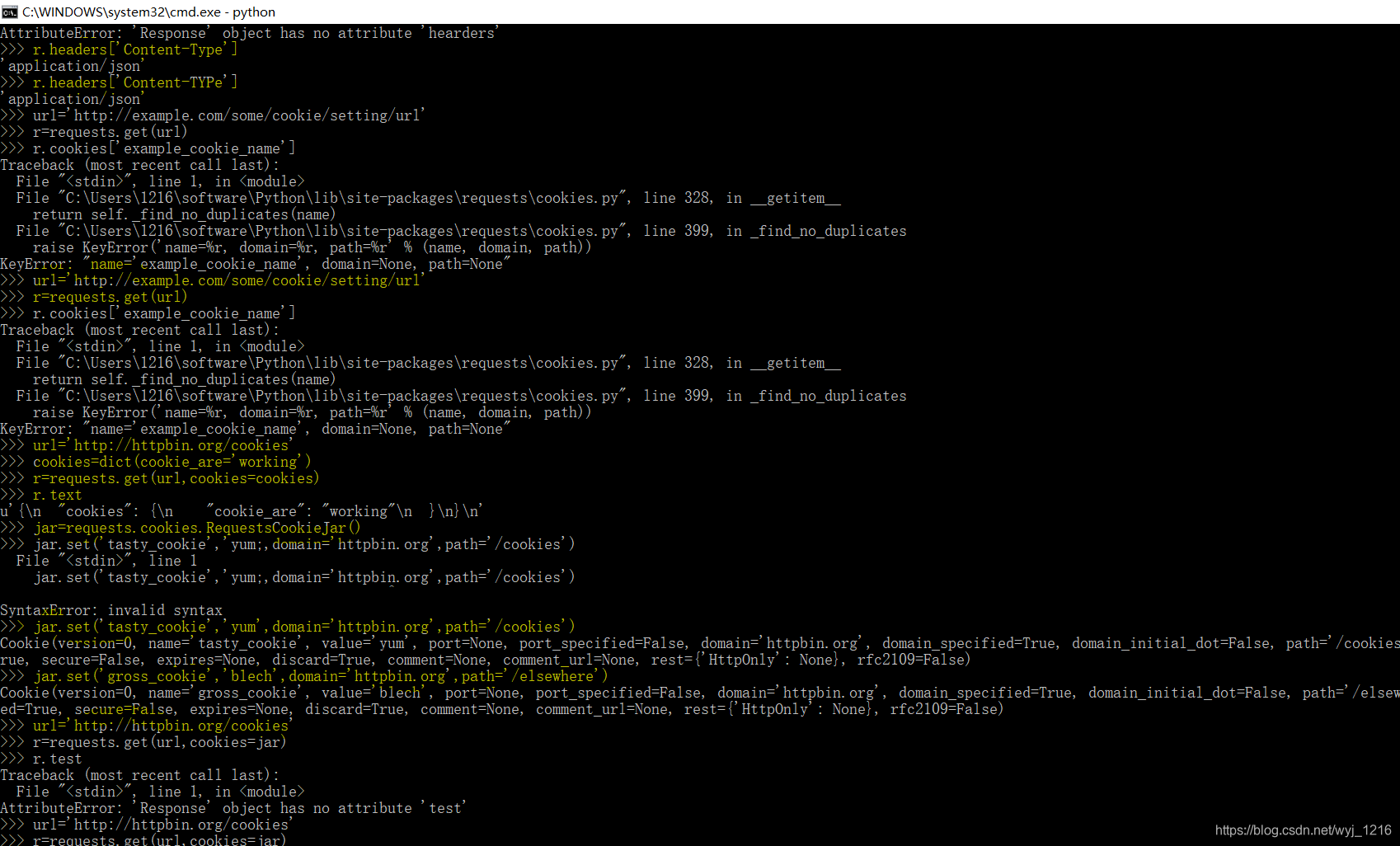
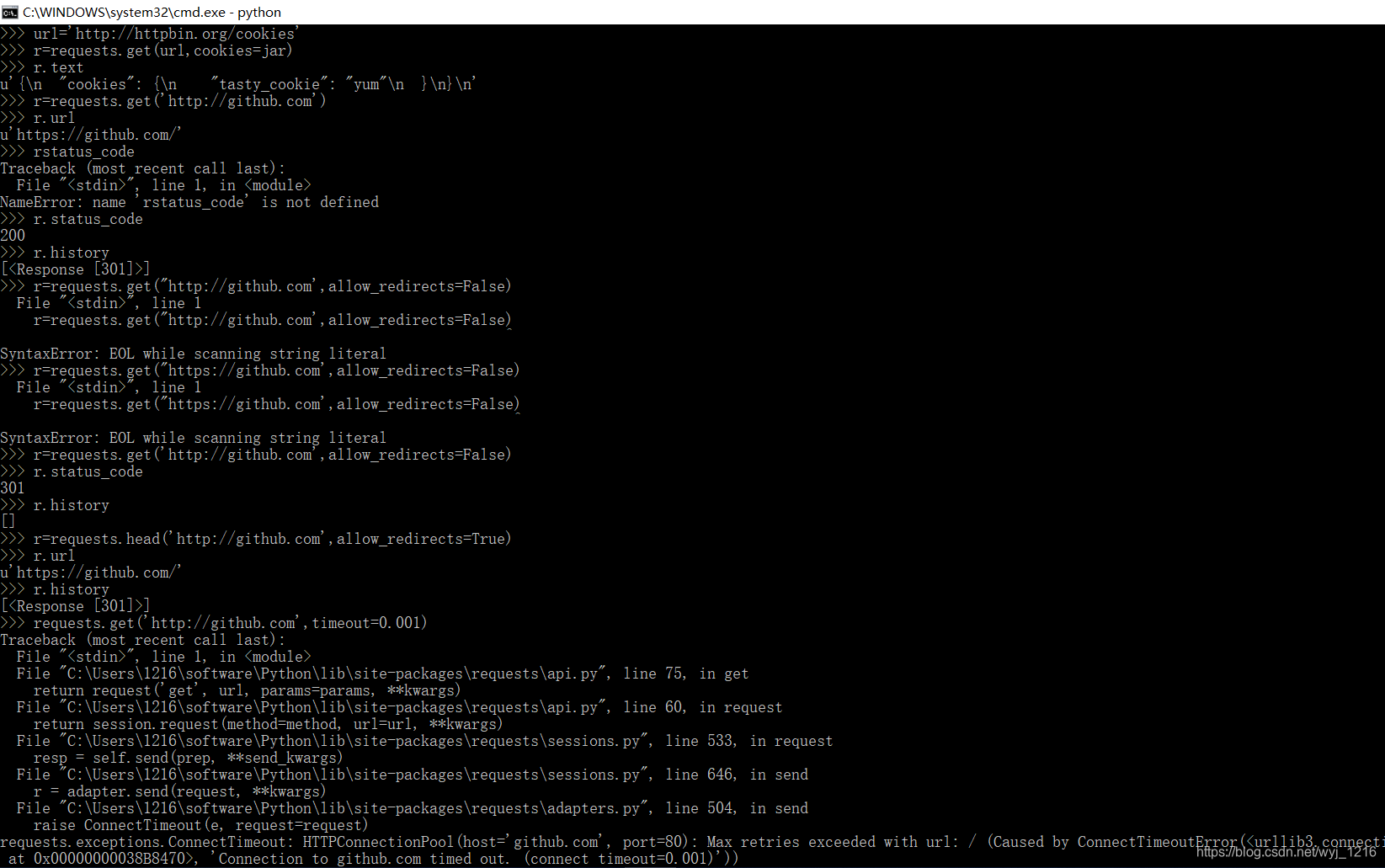
阅读reuests库文档
-
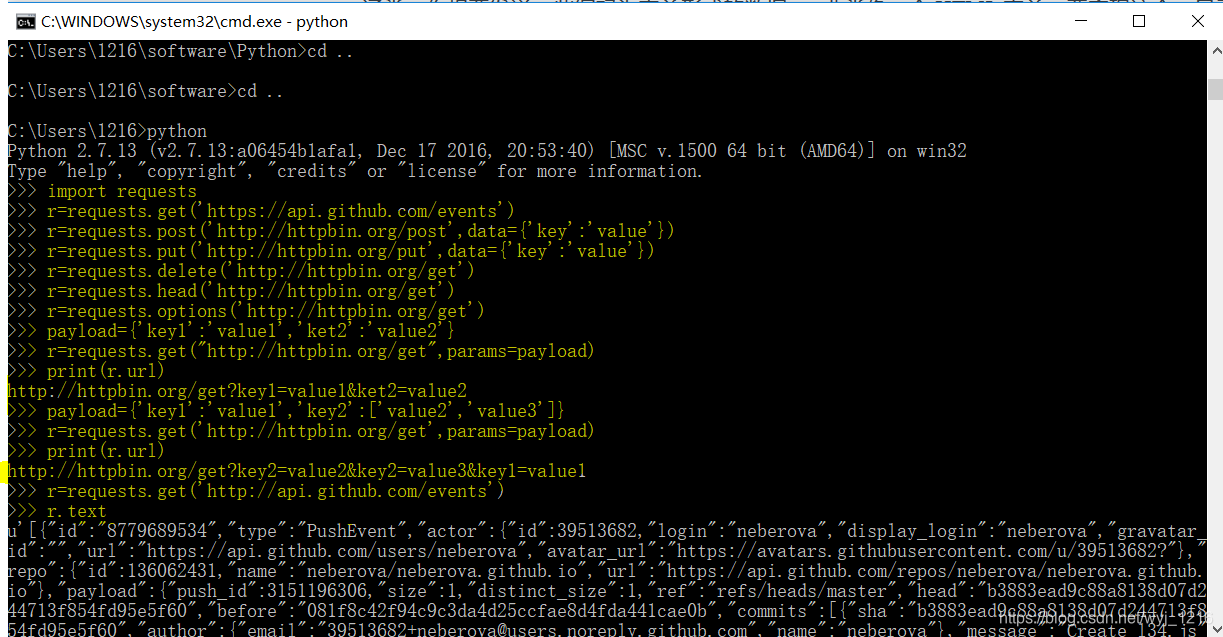
安装requests库
执行命令:
pip install requests检查是否安装好:
>>>import requests
-
链接网址:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
-
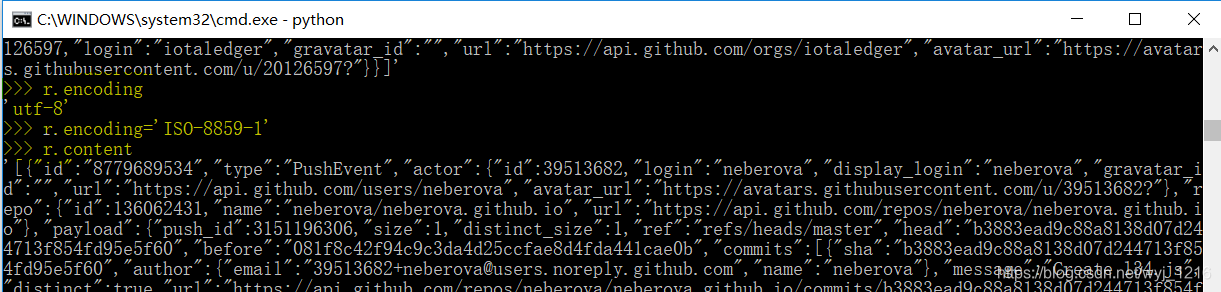
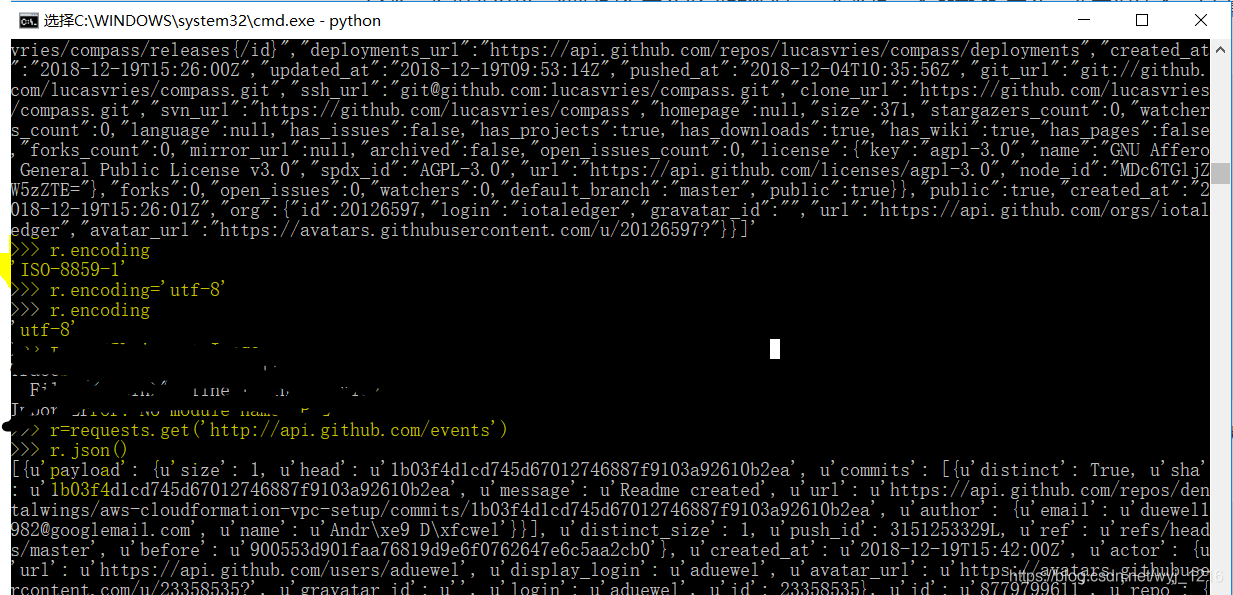
实际演练:
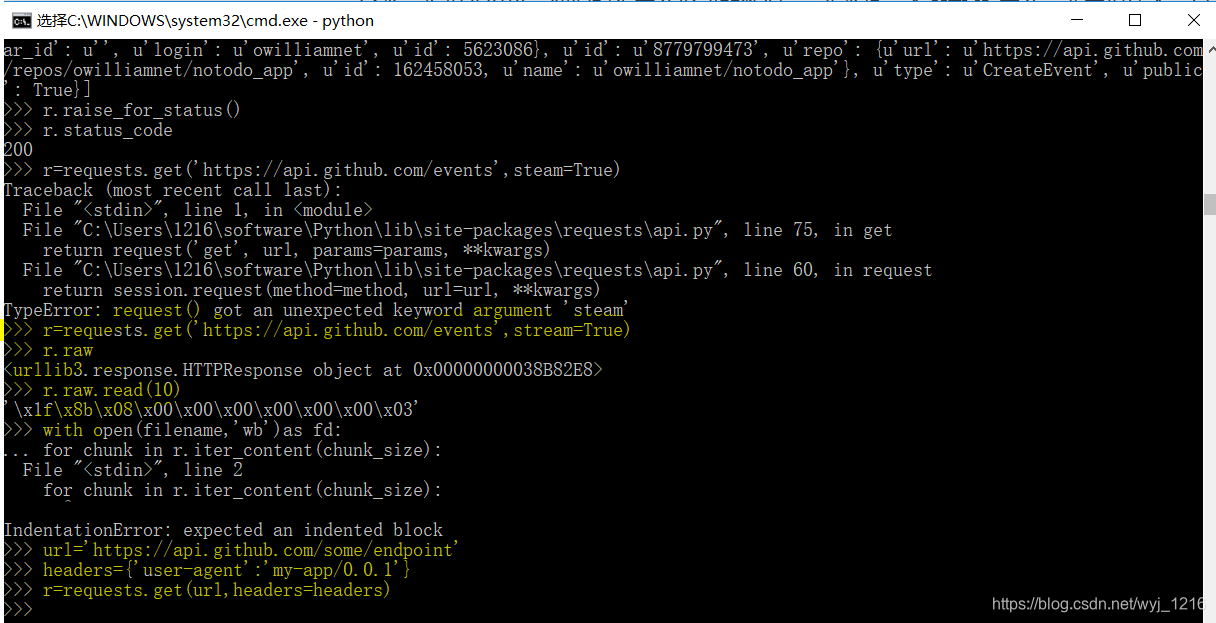
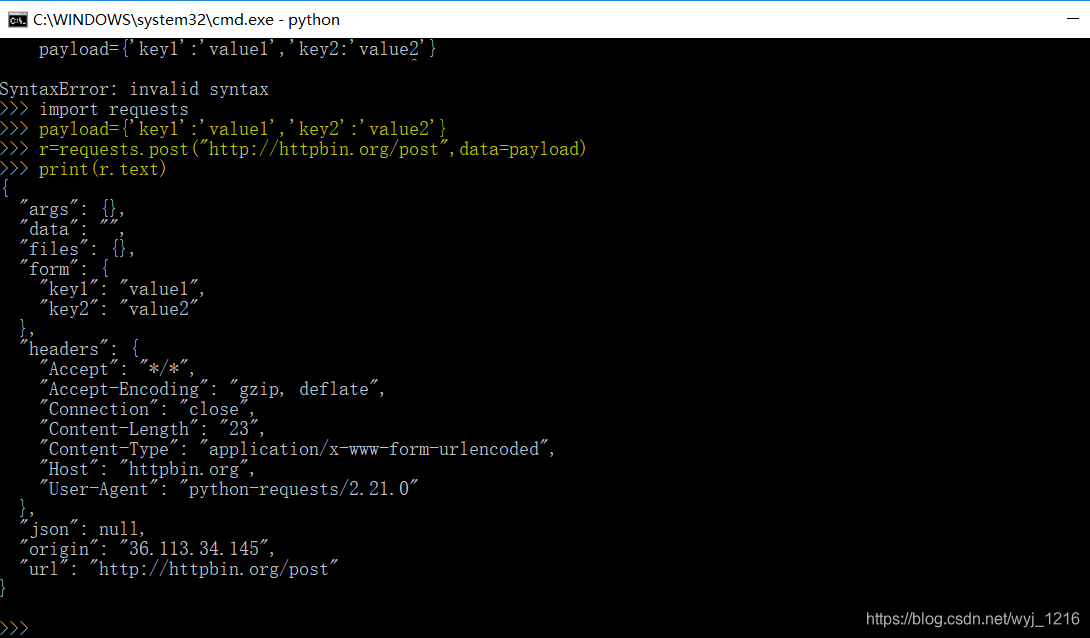
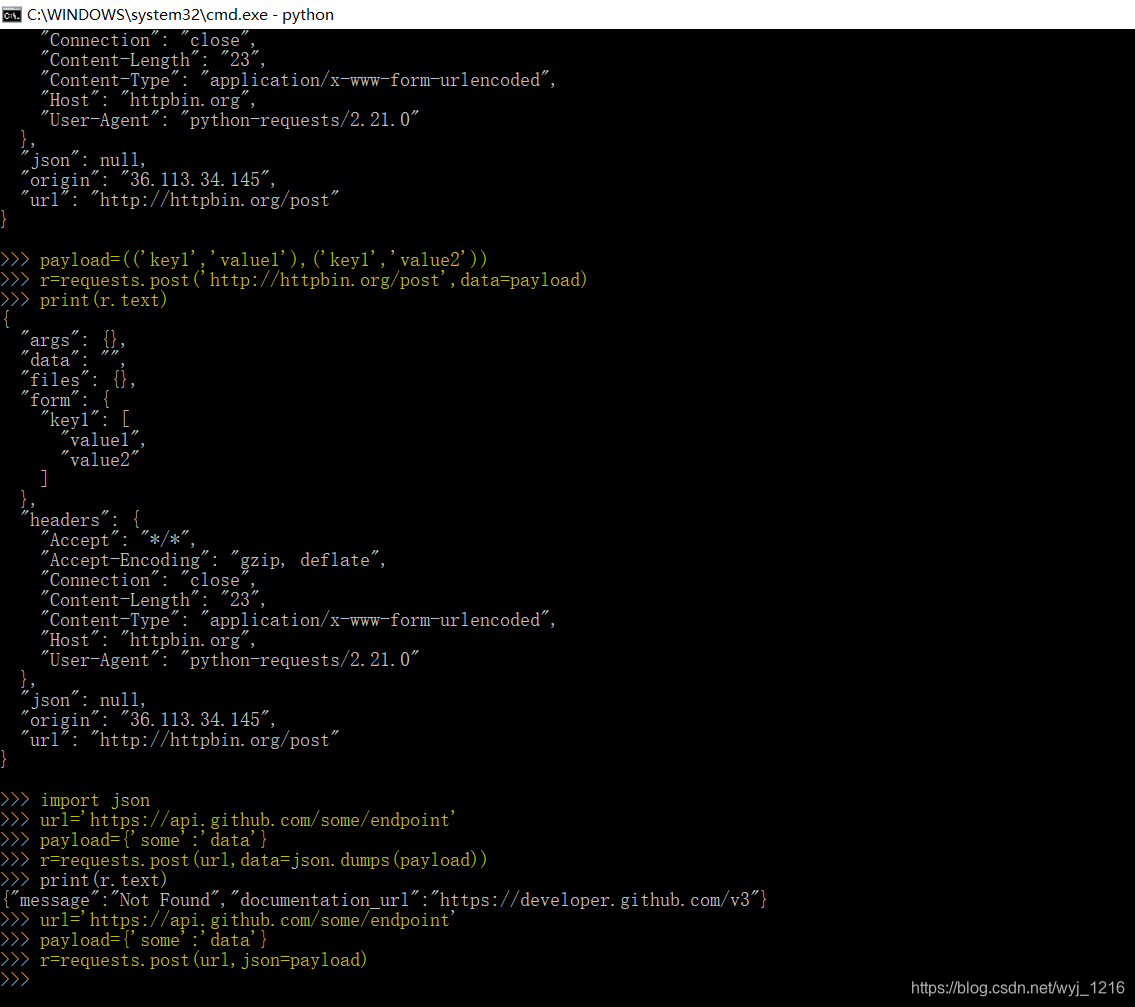
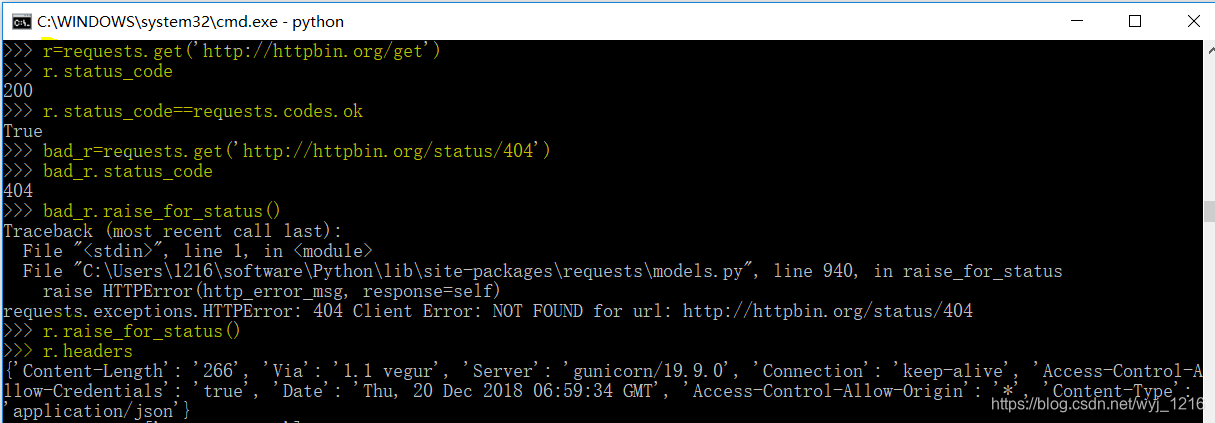
百度搜索结果爬虫脚本
终端输入命令:
python baidu_crawler.py -k inurl:asp?id= -p 2
其中,脚本命名为baidu_crawler.py,有三个参数,-k是必须的,后接搜索关键词,-t后接一个整数,是超时时间,默认为60秒,-p后接一个整数,是要爬取的总页数,默认为5页
源程序代码:
# !/usr/bin/python
# -*- coding:UTF-8 -*-
import re
import requests
import traceback
from urllib import quote
import sys, getopt
reload(sys)
sys.setdefaultencoding('utf-8')
class crawler:
'''爬百度搜索结果的爬虫'''
url = u''
urls = []
o_urls = []
html = ''
total_pages = 5
current_page = 0
next_page_url = ''
timeout = 60 #默认超时时间为60秒
headersParameters = { #发送HTTP请求时的HEAD信息,用于伪装为浏览器
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def __init__(self, keyword):
self.url = u'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8'
def set_timeout(self, time):
'''设置超时时间,单位:秒'''
try:
self.timeout = int(time)
except:
pass
def set_total_pages(self, num):
'''设置总共要爬取的页数'''
try:
self.total_pages = int(num)
except:
pass
def set_current_url(self, url):
'''设置当前url'''
self.url = url
def switch_url(self):
'''切换当前url为下一页的url若下一页为空,则退出程序'''
if self.next_page_url == '':
sys.exit()
else:
self.set_current_url(self.next_page_url)
def is_finish(self):
'''判断是否爬取完毕'''
if self.current_page >= self.total_pages:
return True
else:
return False
def get_html(self):
'''爬取当前url所指页面的内容,保存到html中'''
r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters)
if r.status_code==200:
self.html = r.text
self.current_page += 1
else:
self.html = u''
print '[ERROR]',self.url,u'get此url返回的http状态码不是200'
def get_urls(self):
'''从当前html中解析出搜索结果的url,保存到o_urls'''
o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html)
o_urls = list(set(o_urls)) #去重
self.o_urls = o_urls #取下一页地址
next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html)
if len(next) > 0:
self.next_page_url = 'https://www.baidu.com'+next[-1]
else:
self.next_page_url = ''
def get_real(self, o_url):
'''获取重定向url指向的网址'''
r = requests.get(o_url, allow_redirects = False) #禁止自动跳转
if r.status_code == 302:
try:
return r.headers['location'] #返回指向的地址
except:
pass
return o_url #返回源地址
def transformation(self):
'''读取当前o_urls中的链接重定向的网址,并保存到urls中'''
self.urls = []
for o_url in self.o_urls:
self.urls.append(self.get_real(o_url))
def print_urls(self):
'''输出当前urls中的url'''
for url in self.urls:
print url
def print_o_urls(self):
'''输出当前o_urls中的url'''
for url in self.o_urls:
print url
def run(self):
while(not self.is_finish()):
c.get_html()
c.get_urls()
c.transformation()
c.print_urls()
c.switch_url()
if __name__ == '__main__':
help = 'baidu_crawler.py -k <keyword> [-t <timeout> -p <total pages>]'
keyword = None
timeout = None
totalpages = None
try:
opts, args = getopt.getopt(sys.argv[1:], "hk:t:p:")
except getopt.GetoptError:
print(help)
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print(help)
sys.exit()
elif opt in ("-k", "--keyword"):
keyword = arg
elif opt in ("-t", "--timeout"):
timeout = arg
elif opt in ("-p", "--totalpages"):
totalpages = arg
if keyword == None:
print(help)
sys.exit()
c = crawler(keyword)
if timeout != None:
c.set_timeout(timeout)
if totalpages != None:
c.set_total_pages(totalpages)
c.run()
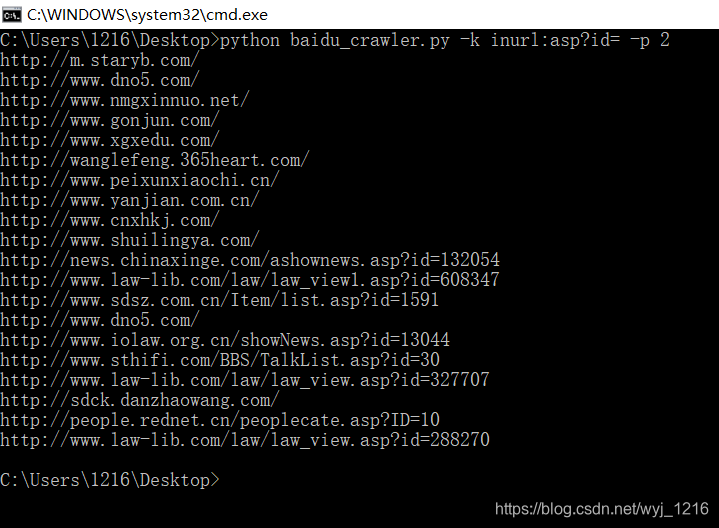
搜索如图:
在这里感谢以为大佬:https://blog.csdn.net/wn314/article/details/76595472
