
文章目录
The Final Project
- 要么做默认的项目——SQuAD问答
- 要么自己找一个项目——必须要TA/prof/post/PhD同意
- 可以使用任何语言/框架,推荐使用Pytorch
The Default Final Project
Building atextualquestionanswering systemforSQuAD
数据集:https://rajpurkar.github.io/SQuAD-explorer/
任务示例:

应注意的几个点

Project Proposal
- 找一个与你的主题相关的研究论文
对于默认的项目,在SQuAD榜单上的一篇论文就可以,但你或许应该从其他地方寻找一些有意思的QA/reading 相关工作 - 写一篇研究论文的摘要,描述你希望如何使用或获取它的思想,以及你计划如何扩展或改进它到你的最终项目工作中
- 根据需要描述,特别是对于定制项目:
一个项目计划,相关的现有文献,你将使用/探索的模型的种类;你将使用的数据(以及如何获得),以及你将如何评估成功。
Project Milestone
- 这是一份进度报告
- 你不应该半途而废!
- 描述你所做的实验
- 描述获得的初步结果
- 描述你打算如何度过剩下的时间
预计到目前为止,你已经实现了一些系统,并有了一些初步的实验结果(某些不寻常的项目除外)
Finding Research Topics
对于所有的科学,都有一下两种开始的方法
- [钉子]从感兴趣的(域)问题开始,并尝试找到比当前已知/使用的更好/更好的解决方法
- [锤子]从感兴趣的技术方法开始,找出扩展或改进它的好方法或新的应用方法
Project types
这不是一个详尽的列表,但大多数项目是其中之一
- 兴趣的应用/任务,探索如何有效地接近/解决它,通常应用现有的神经网络模型
- 实现一个复杂的神经架构并在一些数据上演示其性能
- 提出一种新的或变异的神经网络模型并探索其实证成功
- 分析项目。分析一个模型的行为:它如何表示语言知识,它能处理什么样的现象或它所犯的错误
- 稀有理论项目:显示模型类型、数据或数据表示的一些有趣的、非平凡的属性
一些例子
- 使用词级别和字符级别的莎士比亚分格诗歌生成
提出了门控LSTM


3.

4.

How to find an interesting place to start?
- 看ACL论文选集https://aclanthology.info
- 也可以看主要的机器学习会议:NeurIPS,ICML,ICLR
- 看cs224n过去的项目
- 看看在线预印本服务器,尤其是: https://arxiv.org
- 甚至可以在现实生活中找一个有趣的问题
一个统计各种任务当前最优解决方案的网站
https://paperswithcode.com/sota
**Finding a topic **
图灵奖获得者、斯坦福大学名誉教授艾德·费根鲍姆说,要听从他的导师艾未未先驱、图灵奖和诺贝尔奖获得者赫伯·西蒙的建议:
“如果你看到一个有很多人工作的研究领域,就去别的地方。”
“If you see a research area where many people are working, go somewhere else.”
对于大多数自定的项目,必须含有
- 合适的数据,Usuallyaimingat:10,000+ labeled examples by milestone
- 可行的任务
- 自动评价标准
- NLP是项目的中心
Finding data
- 可以自己收集数据
- 模型可能采用无监督数据
- 可以自己标注少量数据
- 可以找一个提供有效标注的网站,比如likes,stars,ratings等等
- 大多数人使用前人建立的数据集
一些数据来源
- Linguistic Data Consortium
包含Treebanks, named entities,coreference data,lots of newswire, lots of speech with transcription,parallel MT data
需要付费 - Machine translation :http://statmt.org
- Dependency parsing: Universal Dependencies
- 一些其他数据
- Look at Kaggle
- Look at research papers
- Look at lists of datasets :https://github.com/niderhoff/nlp-datasets
再看门控循环单元和MT
直觉上,RNN会发生什么?
- 衡量过去对未来的影响
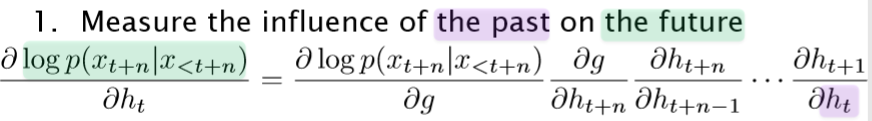
如上图,相同颜色为所指。使用了链导法则,上式表明了过去( )对未来( )的影响,此影响用未来的误差对现在的偏导衡量 - 在t处的扰动是如何影响
的?

Backpropagation through Time
问题:梯度消失是个大问题
- 当梯度为0时,我们无法判断
- 数据中t和t+n之间没有依赖关系,或者
- 参数配置错误(消失梯度条件)
- 普通RNN是否存在这个问题
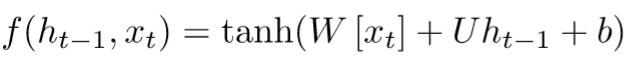
存在,如下图,会导致梯度消失
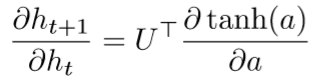
Gated Recurrent Unit
- 这意味着错误必须通过所有中间节点反向传播:

- 也许我们可以创建自适应的快捷连接

上图与HighwayNet很像,通过 向量控制哪部分数据(更新后的 还是未更新的 )传递下去 - 或者让网络自适应地剪除不必要的连接

注意图中的颜色,与上一种方法相比,这种方法增加了一个重置门。不再是全盘接收上一个时间步的隐藏状态,而是使用向量 来控制。
下面用图来总结普通RNN和门控RNN
-
普通RNN:对于前一时间步的输出全盘读取,然后全盘更新

-
门控RNN:
改进在于- 不再是全盘读取,而是选择一个可读取子集,通过向量 来决定前一时间步的输出 有多少参与下一时间步的更新
- 不再是全部更新到下一时间步,而是选择一个可写子集,通过向量
来决定哪些数据(
还是
)选择为下一时间步的输出

注:- 门控循环单元更加实际一些
- 这里的思想与注意力有些重叠
-
两个最常用的门控循环单元:GRU和LSTM
GRU和我们之间讲的门控RNN差不多,而LSTM有三个门,其中两个来控制从之前的时间步读取多少内容,一个控制向下一时间步传递多少内容。

- LSTM的计算图

LSTM将所有的操作都用作门,所以所有的东西都可以被遗忘或者忽视。

底部非线性的更新就和普通RNN相同

上图中的这部分是关键点,这里没有使用乘,而是使用了加,将非线性的部分与 相加得到 ,类似在 和 之间增加了一个直接的线性连接。(与最近出现的一些新的架构很类似,如ResNets)
- LSTM的计算图
The large output vocabulary problem in NMT (or all NLG)

- 在seq2seq任务中,我们在解码器部分生成目标序列时,在每个时间步都使用softmax对词表中所有单词求生成概率。这样会消耗大量计算资源
- 词生成问题:词表规模适中,通常为50K
可能的解决方法
- Hierarchical softmax:树结构的词表
- Noise-contrastive estimation:binary classification
- 一次训练一部分词汇;测试一组可能的翻译:Jean, Cho, Memisevic, Bengio. ACL2015
- 使用注意力弄清楚你在翻译什么:你可以做一些简单的事情,比如查字典
- 更多的想法:单词片段;char。模型
MT评价
- 人工评价
- 忠实度和流利度(5 or 7个分数段)
- 错误分类
- 翻译排名比较(例如人工判断两个翻译哪一个更好)
- 在一个应用中测试,将MT作为子组件
- 例如,外语文献问答
- 可能无法测试翻译的许多方面(例如,跨语言信息检索)
- 例如,外语文献问答
- 自动评测:BLEU、其余如TER,METEOR
BLEU Evaluation Metric
(Papineni et al, ACL-2002)
-
n-gram精确度(分数介于0~1)
- n-gram既能衡量忠实度和流利度
- 对不同n-gram结果几何平均加和
-
简短惩罚:短的句子更容易得到高分,因此对较短的句子乘一个惩罚
具体计算例子:https://www.cnblogs.com/by-dream/p/7679284.html -
初始的结果显示BLEU分数与人类判断具有线性相关

-
MT的自动评测
- 人们开始优化系统来提高BLEU分数
- BLEU分数很快增加
- 但BLEU与人类对质量的判断之间的相关性一直在下降
- BLEU的分数现在接近人工翻译的分数,但它们的真实质量仍然远远低于人工翻译
- 提出自动机器翻译评估已经成为它自己的研究领域
- 有很多建议:TER,METEOR,MaxSim,SEPIA,RTE-MT
- TERpA 是一个具有代表性的,好处理一些词的选择变化的度量
- MT研究需要一些自动的度量,以允许快速的开发和评估
- 人们开始优化系统来提高BLEU分数
如何做一个研究
- 定义任务,例如:Summarization(摘要)
- 定义数据集
- 寻找学术数据集
它们已有baselines
例如:Newsroom Summarization Dataset:https://summari.es/ - 定义自己的数据(更难一些,需要新的baselines)
允许连接到自己的研究
新的问题提供新的机会
有创意:Twitter、博客、新闻等。有很多整洁的网站,为新的任务提供创造性的机会
- 寻找学术数据集
- Dataset hygiene :分离 devtest 和 test,稍后会讨论更多
- 定义自己的度量
在网上搜索在该任务上已有的度量方法
摘要: Rouge (Recall-Oriented Understudy for GistingEvaluation) ,它定义了人工摘要的 n-gram重叠
人工评价仍然更适合于摘要;你可以做一个小规模的人类计算 - 建立一个baseline
首先实现一个最简单的模型(通常对unigrams、bigrams 或平均字向量进行逻辑回归)
计算训练集和开发集的度量
分析错误
如果度量令人惊讶且没有错误,那么,完成!问题太简单了。需要重新找个任务 - 实现现有的神经网络模型
计算训练集和开发集的指标
分析输出和错误
这门课的最低标准 - 永远要接近您的数据(除了最后的测试集),即要总是在当前数据集上进行实验,不能根据其他数据集去改进模型等等
可视化数据集
收集汇总统计信息
查看错误
分析不同的超参数如何影响性能 - 尝试一些不同的模型以及模型变体,旨在通过有一个好的实验设置快速迭代

Pots of data
- 许多公开可用的数据集都是使用train/dev/test结构发布的。我们应该只在开发完成时才运行测试集
- 这样的拆分以相当大的数据集为前提。
- 如果没有dev集或者您想要一个单独的tune集,那么您可以通过分割训练数据来创建一个tune集,但你必须权衡它的大小/有用性与减少的train集大小
- 有一个固定的测试集可以确保所有系统都是根据相同的gold数据进行评估的。这通常是好的,但是如果测试集具有不寻常的属性,从而扭曲了任务的进度,则会出现问题。
Training models and pots of data
- 在训练时,可能会发生过拟合,即模型在训练集上表现很好,但在测试集上表现很差
- 监测和避免过拟合的方法时使用独立的验证集(开发集)和测试集

- 在训练集上建立(估计/训练)模型。
- 通常,然后在另一组独立的数据上设置更多的超参数,即调整集(tuning set ),调整集是超参数的训练集!
- 当您在dev set(开发测试集或验证集)上运行时,您可以测量进度;如果您经常这样做,那么您就太适合dev集了,所以最好有第二个dev集,即dev2集
- 只有在最后,你才能在一个测试集上评估和呈现最终的数字•使用最终的测试集极值几次…理想情况下只有一次
- train、tune、dev和testset必须完全不同
- 在训练集上测试是无效的,你会得到一个错误的好成绩。因为可能在训练集上发生过拟合
- 您需要一个独立的验证集,如果验证集与训练集相同,则无法正确设置超参数
- 我们需要意识到,每一次通过评估结果的变化而完成的调整,都是对数据集的拟合过程。我们需要对数据集的过拟合,但是不可以在独立测试集上过拟合,否则就失去了测试集的意义
Getting your neural network to train
- 以积极的态度开始
- 认识到残酷的现实
- 有很多事情会导致神经网络不会学习或学习的不好,找到并修正它们(“debuggingandtuning”)可能会花费比实现模型更多的时间
- 很难弄清楚这些东西是什么,但经验、实验护理和经验法则会有帮助!
Models are sensitive to learning rates

Models are sensitive to initialization

Training a (gated) RNN
- 使用LSTM或GRU:它使您的生活变得更加简单!
- 初始化递归矩阵为正交矩阵
- 用一个可感知的(小的)比例初始化其他矩阵
- 初始化忘记门偏差为1:默认记住
- 使用自适应学习速率算法:Adam, AdaDelta,…
- 梯度范数的裁剪:1-5似乎是一个合理的阈值,当与Adam 或 AdaDelta一起使用
- 要么只使用 dropout vertically,要么研究使用Bayesian dropout(Gal和Gahramani -不在PyTorch中原生支持)
- 要有耐心!优化需要时间
Experimental strategy
- 增量地工作!
- 从一个非常简单的模型开始
- 一个接一个地添加修饰物让它开始工作,让模型使用它们中的每一个(或者放弃它们)
- 最初运行在少量数据上
- 你会更容易在一个小的数据集中看到bug
- 像8个例子这样的东西很好
- 通常,合成数据对这很有用
- 确保你能得到100%的数据
- 否则你的模型肯定要么不够强大,要么是破碎的
- 在大型数据集中运行
- 模型优化后的训练数据仍应接近100%
- 否则,您可能想要考虑一种更强大的模式来过拟合训练数据
- 对训练数据的过拟合在进行深度学习时并不可怕
- 这些模型通常善于一般化,因为分布式表示共享统计强度,和对训练数据的过度拟合无关
- 模型优化后的训练数据仍应接近100%
- 但是,现在仍然需要良好的泛化性能
- 对模型进行正则化,直到它不与dev数据过拟合为止
- 像L2正则化这样的策略是有用的
- 但通常Dropout是成功的秘诀
Details matter!
- 查看您的数据,收集汇总统计信息
- 查看您的模型的输出,进行错误分析
- 调优超参数对于神经网络几乎所有的成功都非常重要
报告要求

