爬取b站弹幕
前段时间爬取了b站的弹幕,现在记录一下心得体会
前期准备
HTML解析
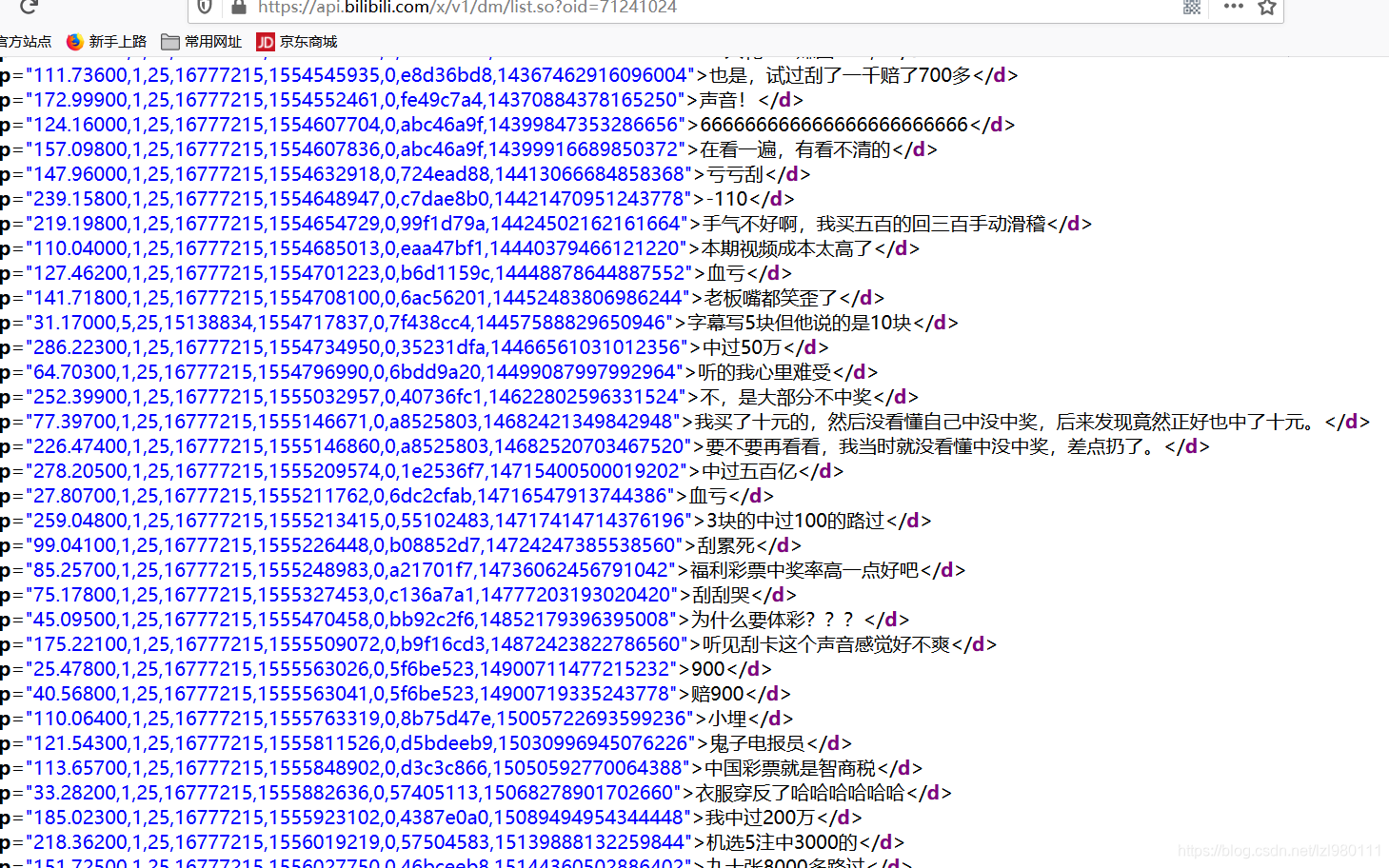
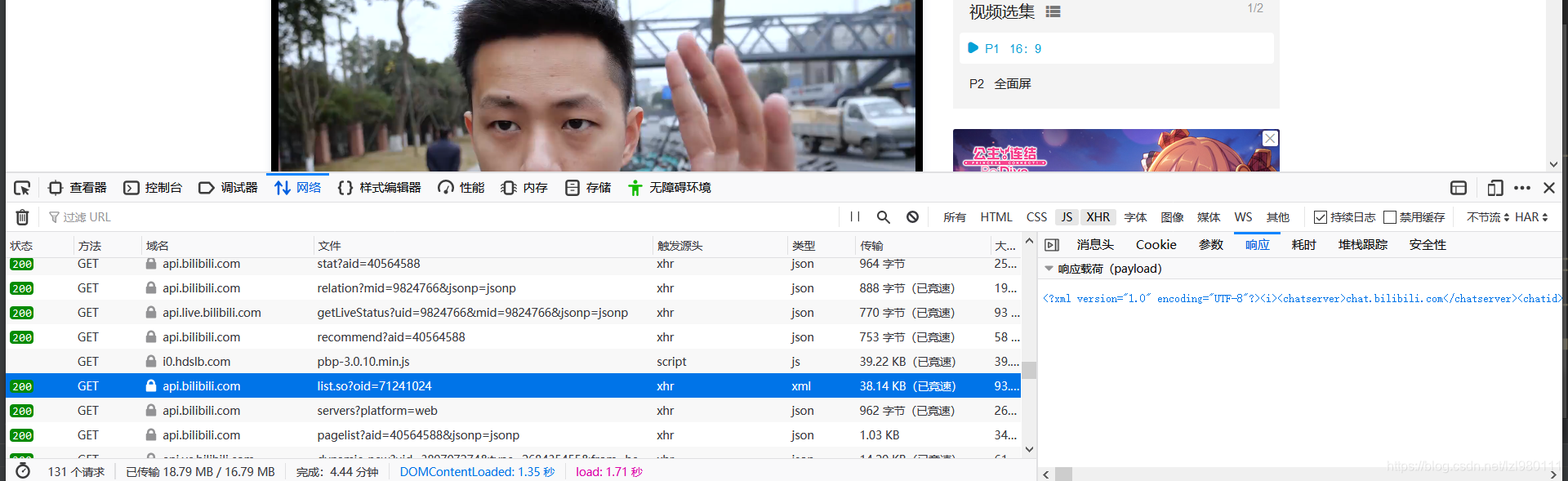
找到弹幕所在的json响应文件,发现里面有1000多条实时弹幕
分析参数:
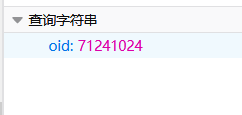
只有视频的主键标识 oid
变法找到 oid 抓取下来(我是想着抓取一个up主的所有视频,所以要抓取全部的oid)
看到每个视频的url是固定的格式:https://www.bilibili.com/video/av+vid
从主界面抓取了所有的vid,然后通过xpath抓取了所有的oid
至此,所有的oid抓取完毕
下面进入代码抓取弹幕,解析数据
先进行一个小测试,测试下抓取单个视频的弹幕:
url="https://api.bilibili.com/x/v1/dm/list.so?oid=144896116"
headers={
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"
}
# query_list={"oid":"144896116"}
response=requests.get(url,headers=headers)
html_str=response.content
html=etree.HTML(html_str)
d_list=html.xpath('//d')
content_list=[]
a=d_list[0].xpath('//text()')
items={}
items["danmu"]=a
content_list.append(items)
with open("blbl.txt","w",encoding="utf-8") as f:
for content in content_list:
f.write(json.dumps(content,ensure_ascii=False))
f.write("\n")
果然抓取成功
然后抓取全部的弹幕,解析,存入数据库
import pymysql
import json
import io
import sys
con = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='root',
db='test',
charset='utf8mb4'
)
cur = con.cursor()
cur.execute("insert into danmu(dm) value('测试')")
con.commit()
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030')
with open("danmu.json", "r", encoding="utf-8") as f:
danmu_str = json.load(f)
# print(danmu_str["dm"][0]["danmu"])
j = 0
for j in range(0, 1002):
for item in danmu_str["dm"][j]["danmu"]:
# sql_str="insert into danmu(dm) value( \""+item+"\")"
for stuff in dirty_stuff:
item = item.replace(stuff, "")
print(item)
length = item.__len__()
for l in range(1, length - 1):
if (item_list[0]==item_list[l]):
item=item_list[0]
sql_str = "insert into danmu(dm) value( \"" + item + "\")"
cur.execute(sql_str)
con.commit()
解析数据,进行弹幕排行:
select count(*) as count,dm as danmu
from danmu
group by dm
order by count desc;
排行结果:
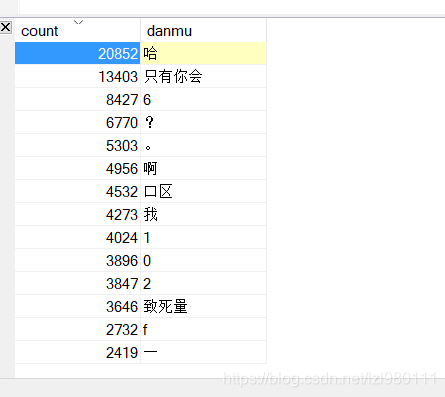
我是抓去了敬汉卿的100万条弹幕,排行结果优点意外,什么0 啊,f啊,一啊的…
