机器学习概述
基本概念
特征与特征向量
以芒果为例,每个芒果的特征包括颜色、大小、产地、品牌等
通常用特征向量来表示样本的特征,每一维表示一个特征
标签
标签是我们要预测的,可以是连续值(比如芒果的甜度,水分以及成熟程度的综合打分)也可以是离散值(比如“好”和“坏”两个标签)
样本与数据集
一个标记好特征和标签的芒果就是一个样本
一组样本组合数据集
数据集可以分为两部分:训练集和测试集
训练学习算法

评价(性能度量)

机器学习的基本流程(预测任务)
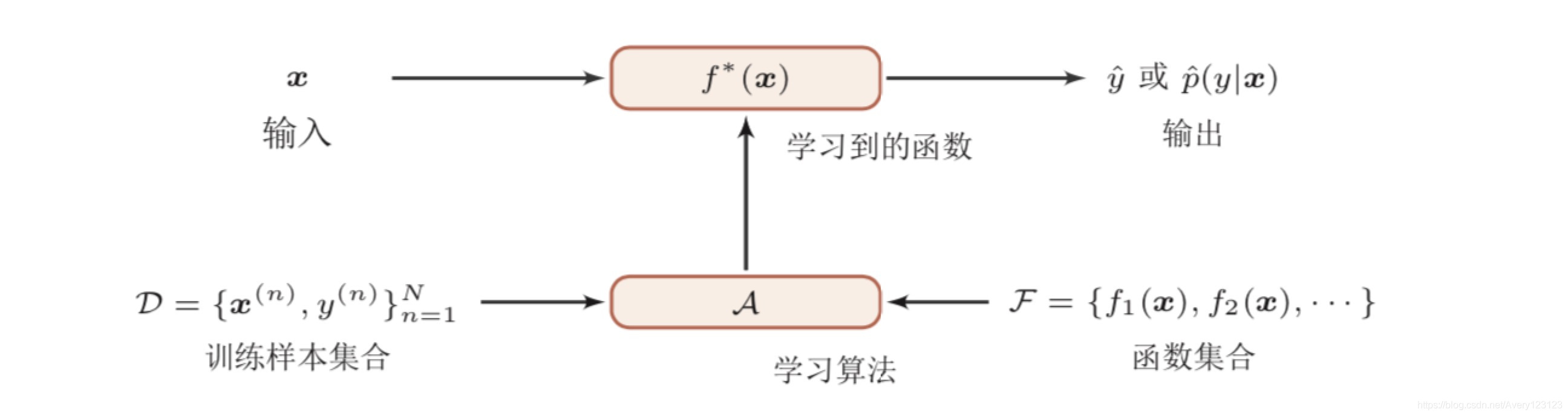
机器学习三要素
模型
概念


线性模型


非线性模型

学习准则

损失函数
损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异。
下面介绍几种常用的损失函数。
0-1损失函数

平方损失函数

交叉熵损失函数


Hinge损失函数

风险最小化准则

优化算法

梯度下降法

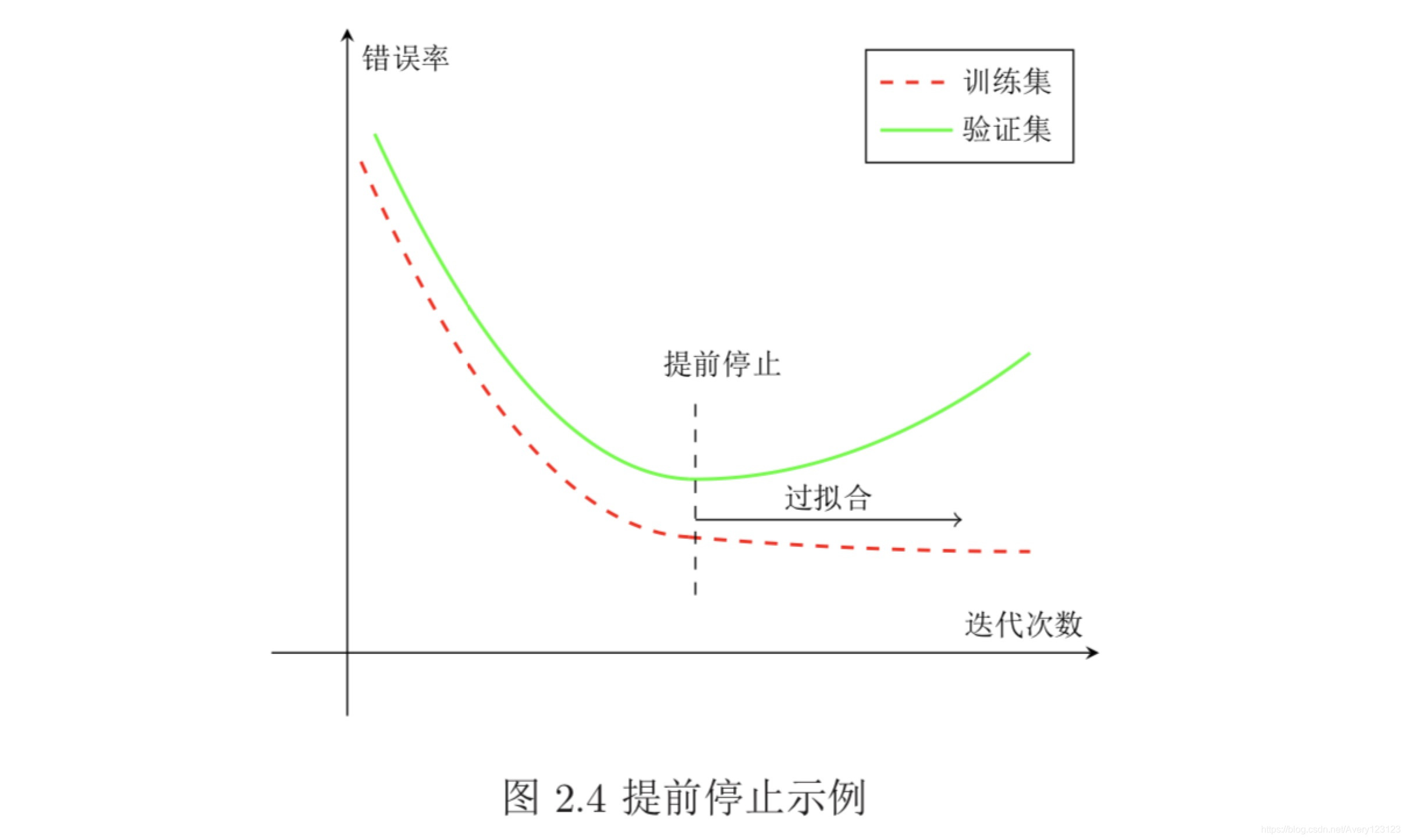
提前停止
针对梯度下降的优化算法,除了加正则化项之外,还可以通过提前停止来防止过拟合。
在梯度下降训练的过程中,由于过拟合的原因,在训练样本上收敛的参数, 并不一定在测试集上最优。因此,除了训练集和测试集之外,有时也会使用一 个验证集(Validation Set)来进行模型选择,测试模型在验证集上是否最优。 在每次迭代时,把新得到的模型f(x;θ)在验证集上进行测试,并计算错误率如果在验证集上的错误率不再下降,就停止迭代。这种策略叫提前停止(Early Stop)。如果没有验证集,可以在训练集上划分出一个小比例的子集作为验证集。 图2.4给出了提前停止的示例。
随机梯度下降
在公式 (2.28) 的梯度下降法中,目标函数是整个训练集上风险函数,这种方 式称为批量梯度下降法(Batch Gradient Descent,BGD)。批量梯度下降法在每 次迭代时需要计算每个样本上损失函数的梯度并求和。当训练集中的样本数量 N 很大时,空间复杂度比较高,每次迭代的计算开销也很大。
在机器学习中,我们假设每个样本都是独立同分布地从真实数据分布中随 机抽取出来的,真正的优化目标是期望风险最小。批量梯度下降法相当于是从 真实数据分布中采集 N 个样本,并由它们计算出来的经验风险的梯度来近似期 望风险的梯度。为了减少每次迭代的计算复杂度,我们也可以在每次迭代时只 采集一个样本,计算这个样本损失函数的梯度并更新参数,即随机梯度下降法
随机梯度下降法的训练过程如算法2.1所示。
批量梯度下降和随机梯度下降之间的区别在于每次迭代的优化目标是对所 有样本的平均损失函数还是单个样本的损失函数。随机梯度下降因为实现简单, 收敛速度也非常快,因此使用非常广泛。随机梯度下降相当于在批量梯度下降的 梯度上引入了随机噪声。当目标函数非凸时,反而可以使其逃离局部最优点。


机器学习的简单示例:线性回归
在本节中,我们通过一个简单的模型(线性回归)来具体了解机器学习的一 般过程,以及不同学习准则(经验风险最小化、结构风险最小化、最大似然估计、 最大后验估计)之间的关系。
线性回归(Linear Regression)是机器学习和统计学中最基础和广泛应用的 模型,是一种对自变量和因变量之间关系进行建模的回归分析。自变量数量为 1 时称为简单回归,自变量数量大于 1 时称为多元回归。

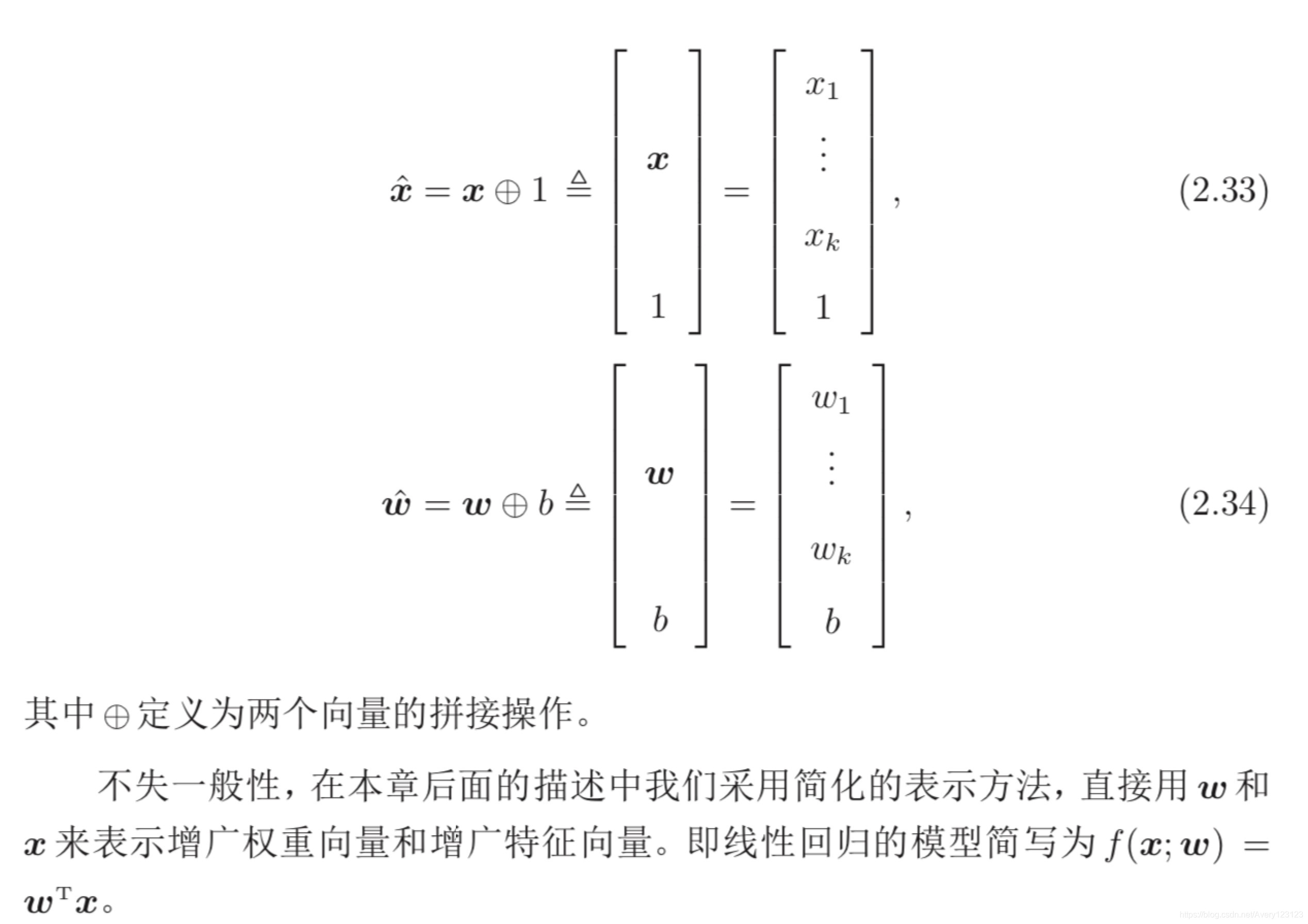
参数学习

经验风险最小化
由于线性回归的标签 y 和模型输出都为连续的实数值,因此平方损失函数非 常合适来衡量真实标签和预测标签之间的差异。根据经验风险最小化准则,训练集 D 上的的经验风险定义为


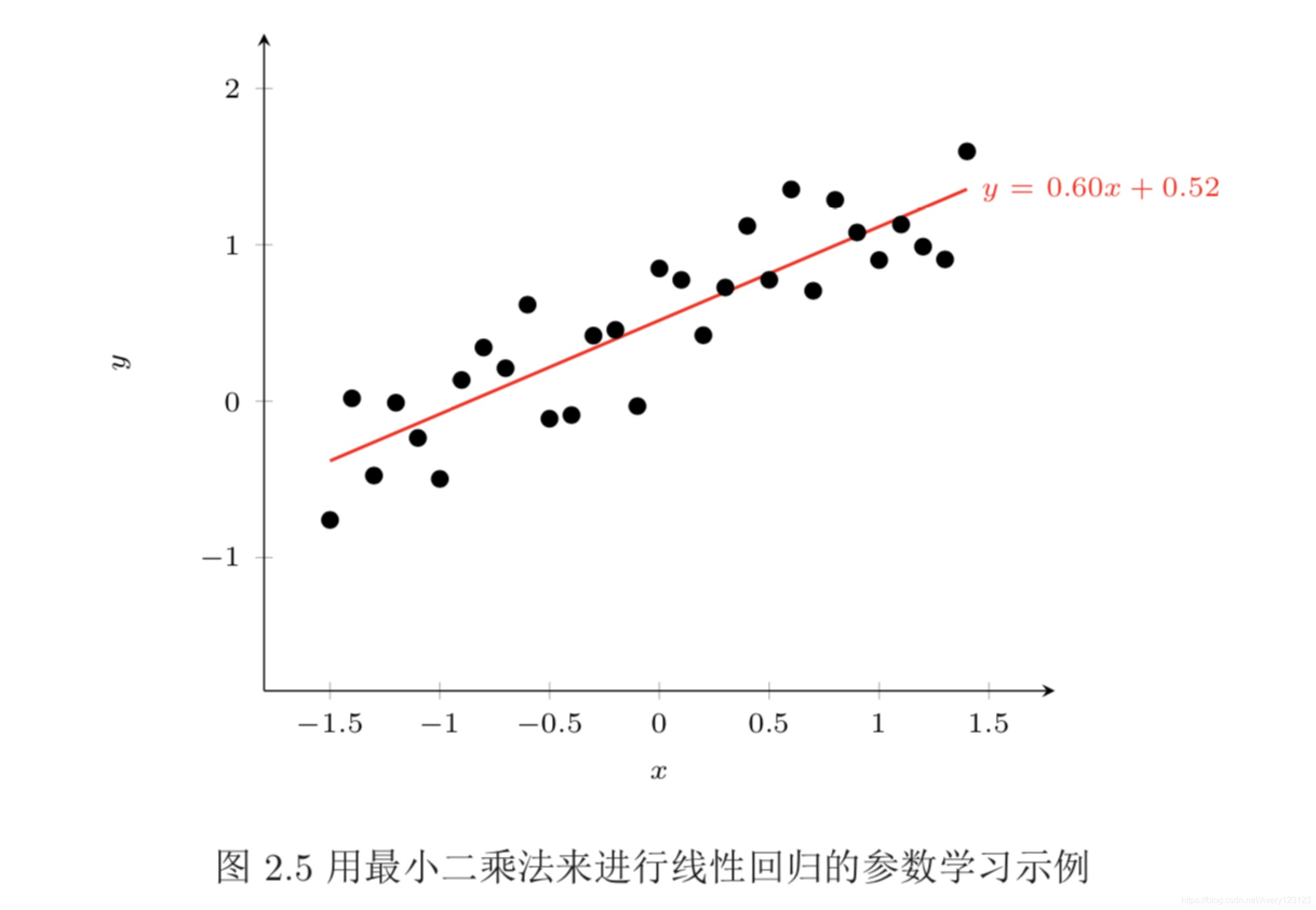
这种求解线性回归参数的方法也叫最小二乘法(Least Square Method,LSM)。 图2.5给出了用最小二乘法来进行参数学习的示例。

结构风险最小化


最大似然估计


最大后验估计


偏差-方差分解
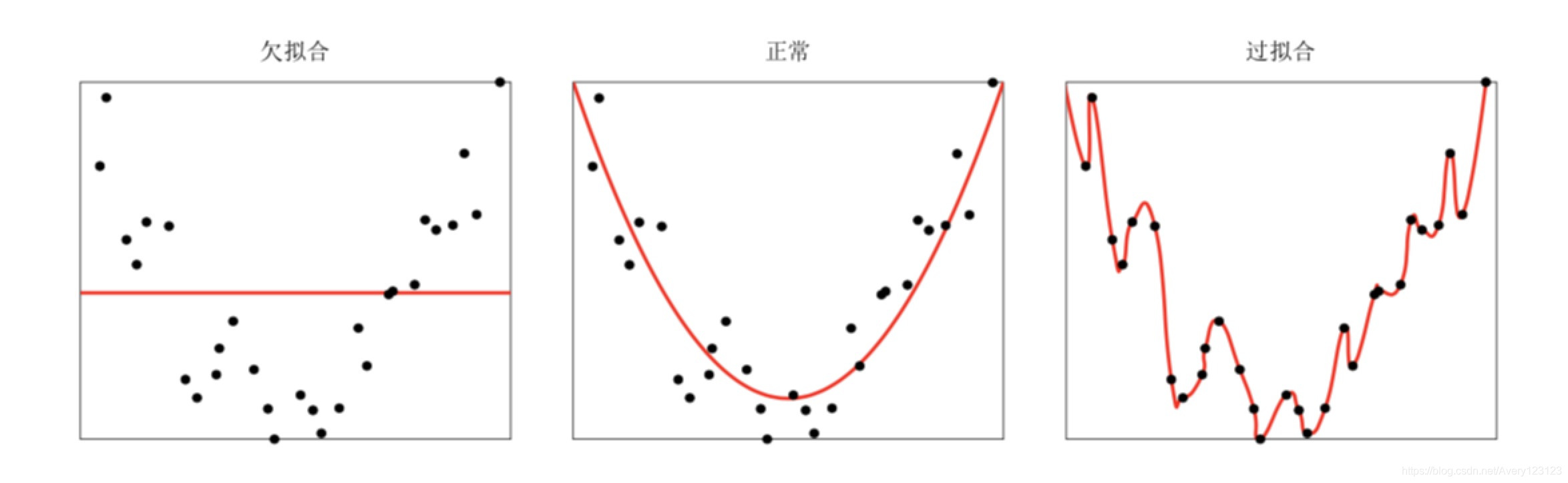
为了避免过拟合,我们经常会在模型的拟合能力和复杂度之间进行权衡。拟 合能力强的模型一般复杂度会比较高,容易导致过拟合。相反,如果限制模型 的复杂度,降低其拟合能力,又可能会导致欠拟合。因此,如何在模型的拟合能 力和复杂度之间取得一个较好的平衡,对一个机器学习算法来讲十分重要。偏 差-方差分解(Bias-Variance Decomposition)为我们提供一个很好的分析和指 导工具。
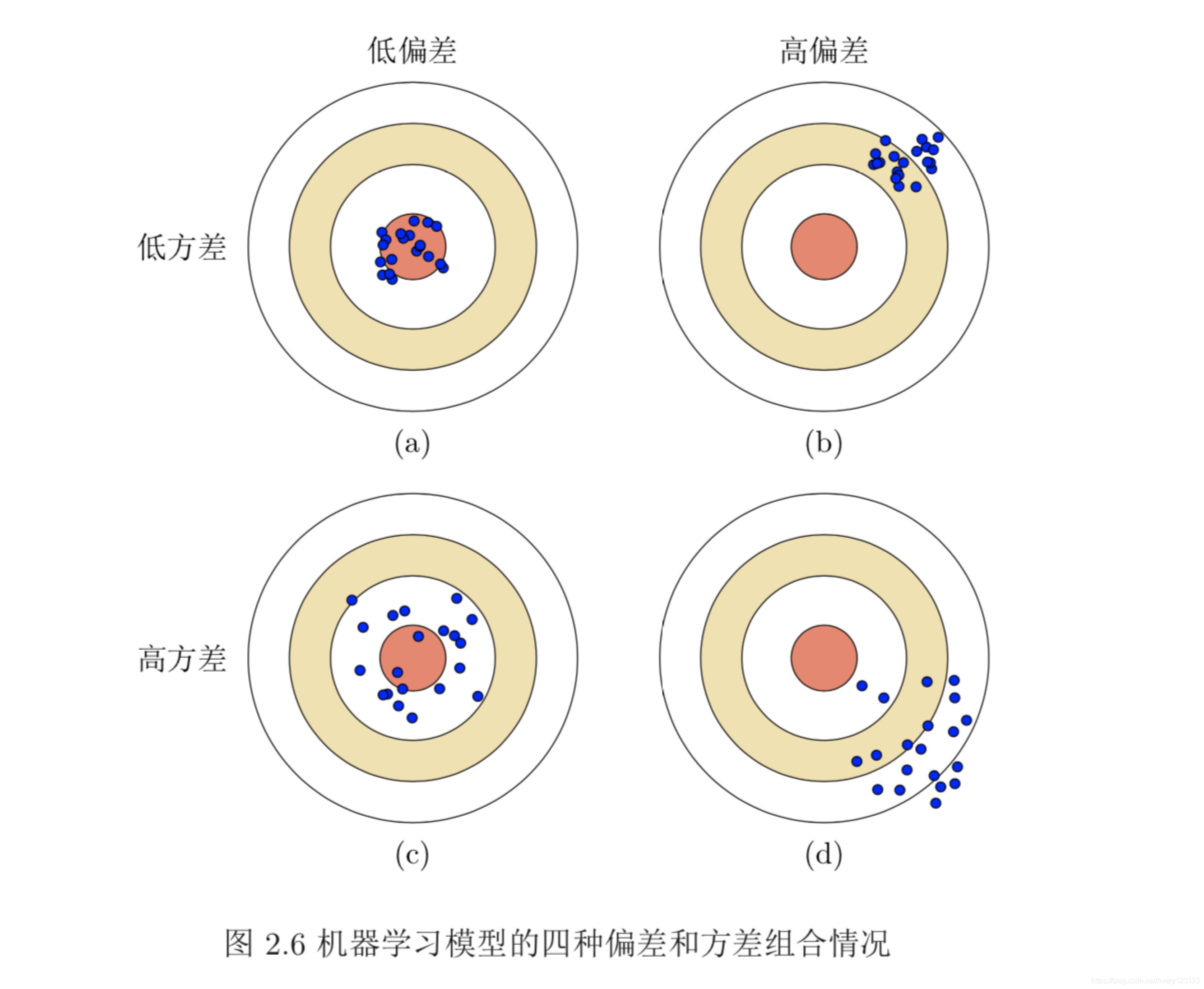
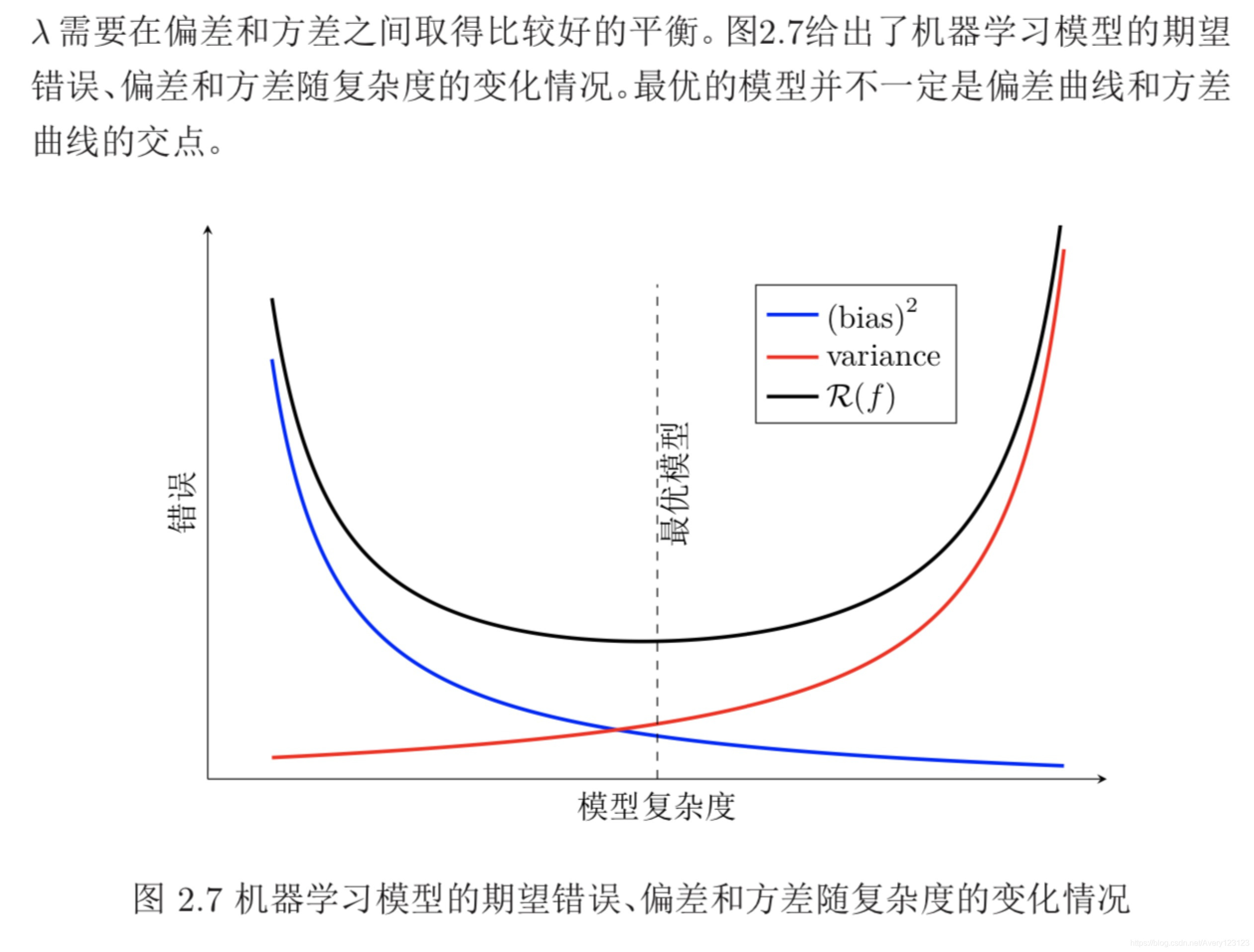
偏差和方差分解给机器学习模型提供了一种分析途径,但在实际操作中难 以直接衡量。一般来说,当一个模型在训练集上的错误率比较高时,说明模型的 拟合能力不够,偏差比较高。这种情况可以通过增加数据特征、提高模型复杂度、 减少正则化系数等操作来改进模型。当模型在训练集上的错误率比较低,但验证 集上的错误率比较高时,说明模型过拟合,方差比较高。这种情况可以通过降低 模型复杂度、加大正则化系数、引入先验等方法来缓解。此外,还有一种有效降低 方差的方法为集成模型,即通过多个高方差模型的平均来降低方差。
机器学习算法的类型
机器学习算法可以按照不同的标准来进行分类。比如按函数 f (x; θ) 的不同, 机器学习算法可以分为线性模型和非线性模型;按照学习准则的不同,机器学习 算法也可以分为统计方法和非统计方法。
但一般来说,我们会按照训练样本提供的信息以及反馈方式的不同,将机器 学习算法分为以下几类:




数据的特征表示
在实际应用中,数据的类型多种多样,比如文本、音频、图像、视频等。不同类 型的数据,其原始特征(Raw Feature)的空间也不相同。比如一张灰度图像(像 素数量为 n)的特征空间为 [0, 255]n,一个自然语言句子(长度为 L)的特征空间 为|V|L,其中V为词表集合。而很多机器学习算法要求是输入的样本特征是数学 上可计算的,因此在机器学习之前我们需要将这些不同类型的数据转换为向量表示。
传统的特征学习
传统的特征学习一般是通过人为地设计一些准则,然后根据这些准则来选 取有效的特征,具体又可以分为两种:特征选择和特征抽取。
特征选择和特征抽取的优点是可以用较少的特征来表示原始特征中的大部 分相关信息,去掉噪声信息,并进而提高计算效率和减小维度灾难(Curse of Dimensionality)。对于很多没有正则化的模型,特征选择和特征抽取非常必要。 经过特征选择或特征抽取后,特征的数量一般会减少,因此特征选择和特征抽取 也经常称为维数约减或降维(Dimension Reduction)。
特征选择


特征抽取


深度学习方法
传统的特征抽取一般是和预测模型的学习分离的。我们会先通过主成分分 析或线性判别分析等方法抽取出有效的特征,然后再基于这些特征来训练一个 具体的机器学习模型。
如果我们将特征的表示学习和机器学习的预测学习有机地统一到一个模型 中,建立一个端到端的学习算法,就可以有效地避免它们之间准则的不一致性。 这种表示学习方法称为深度学习(Deep Learning,DL)。深度学习方法的难点是 如何评价表示学习对最终系统输出结果的贡献或影响,即贡献度分配问题。目前 比较有效的模型是神经网络,即将最后的输出层作为预测学习,其它层作为表示学习。
评价指标





宏平均和微平均 为了计算分类算法在所有类别上的总体查准率、查全率和F1 值,经常使用两种平均方法,分别称为宏平均(Macro Average)和微平均(Micro Average)[Yang,1999]。


在实际应用中,我们也可以通过调整分类模型的阈值来进行更全面的评价, 比如AUC(Area Under Curve)、ROC(Receiver Operating Characteristic)曲 线、PR(Precision-Recall)曲线等。此外,很多任务还有自己专门的评价方式,比 如TopN准确率。
交叉验证
交叉验证(Cross Validation)是一种比较好的衡量机器学习模型的统 计分析方法,可以有效避免划分训练集和测试集时的随机性对评价结果造成的 影响。我们可以把原始数据集平均分为 K 组不重复的子集,每次选 K − 1 组子集 作为训练集,剩下的一组子集作为验证集。这样可以进行 K 次试验并得到 K 个 模型,将这 K 个模型在各自验证集上的错误率的平均作为分类器的评价。
理论和定理
PCA学习理论
当使用机器学习方法来解决某个特定问题时,通常靠经验或者多次试验来 选择合适的模型、训练样本数量以及学习算法收敛的速度等。但是经验判断或多 次试验往往成本比较高,也不太可靠,因此希望有一套理论能够分析问题难度、 计算模型能力,为学习算法提供理论保证,并指导机器学习模型和学习算法的 设计。这就是计算学习理论。计算学习理论(Computational Learning Theory) 是关于机器学习的理论基础,其中最基础的理论就是可能近似正确(Probably Approximately Correct,PAC)学习理论。


没有免费的午餐定理
没有免费午餐定理(No Free Lunch Theorem,NFL)是由Wolpert和Mac- erday 在最优化理论中提出的。没有免费午餐定理证明:对于基于迭代的最优化 算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。如果一个算法 对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差。也就是 说,不能脱离具体问题来谈论算法的优劣,任何算法都有局限性。必须要“具体问 题具体分析”。
丑小鸭定理
丑小鸭定理(Ugly Duckling Theorem)是1969年由渡边慧提出的[Watan- able,1969]。“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”。这 个定理初看好像不符合常识,但是仔细思考后是非常有道理的。
因为世界上不存在相似性的客观标准,一切相似性的标准都是主观的。如果 以体型大小的角度来看,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是如 果以基因的角度来看,丑小鸭与它父母的差别要小于它父母和其他白天鹅之间 的差别。
奥卡姆剃刀原理
奥卡姆剃刀(Occam’s Razor)原理是由14世纪逻辑学家William of Occam 提出的一个解决问题的法则:“如无必要,勿增实体”。奥卡姆剃刀的思想和机器 学习上正则化思想十分类似:简单的模型泛化能力更好。如果有两个性能相近的 模型,我们应该选择更简单的模型。因此,在机器学习的学习准则上,我们经常会 引入参数正则化来限制模型能力,避免过拟合。

归纳偏置
在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就 称为归纳偏置(Inductive Bias)[Mitchell,1997]。比如在最近邻分类器中,我们会 假设在特征空间中,一个小的局部区域中的大部分样本都同属一类。在朴素贝叶 斯分类器中,我们会假设每个特征的条件概率是互相独立的。
渡边慧(Satosi Watanabe), 1910-1993,美籍日本学者,理论物理学家,也是模式识别的最早研究者之一。
这里的“丑小鸭”是指白天鹅 的幼雏,而不是“丑陋的小鸭 子”。
归纳偏置在贝叶斯学习中也经常称为先验(Priors)。
