关系抽取(三) — Dependency-based Models
Improved Relation Classification by Deep Recurrent Neural Networks with Data Augmentation
现状
使用feature-based和kernel-based方式:feature: lexical, syntactic, semantic one; kernel: require predefined similarity measure of two data samples, a kernel along the shortest dependency path (SDP) between two entities
当前的NN都是single layer,需要用一个deep的架构
模型

- 将SDP拆分成两条sub-path,每个sub-path用RNN处理。
- 每个RNN利用4个channel:word embeddings, POS embeddings, grammatical relation embeddings, and WordNet embeddings。
- Word representations: Each word in a given sentence is mapped to a real-valued vector by looking up in a word embedding table. Unsupervisedly trained on a large corpus, word embeddings are thought to be able to well capture words’ syntactic and semantic information (Mikolov et al., 2013b)
- Part-of-speech tags: Since word embed- dings are obtained on a generic corpus of a large scale, the information they contain may not agree with a specific sentence. We deal with this problem by allying each input word with its POS tag, e.g., noun, verb, etc.In our experiment, we only take into use a coarse-grained POS category, containing 15 different tags
- Grammatical relations: The dependency relations between a governing word and its children makes a difference in meaning. A same word pair may have different dependency relation types. For example, “beats nsubj − − − → it” is distinct from “beats dobj − − − → it.”Thus, it is necessary to capture such grammatical relations in SDPs
- WordNet hypernyms: As illustrated in Section 1, hyponymy information is also useful for relation classification. (Details are not repeated here.) To leverage WordNet hypernyms, we use a tool developed by Ciaramita and Altun (2006).2The tool assigns a hypernym to each word, from 41 predefined concepts in WordNet, e.g., noun.food, verb.motion, etc. Given its hypernym, each word gains a more abstract concept, which helps to build a linkage between different but conceptual similar words.
- 层叠拼接4个RNN层StackedRNNCells
- 每个RNN后接一个max-pooling来搜集信息
- 所有的max-pooling结果concatenation在一起送入softmax
- 为了解决deep数据不足的问题,通过将SDP反向+directed relation来进行data augmentation
Bidirectional Recurrent Convolutional Neural Network for Relation Classification
模型
最短依存路径SDP
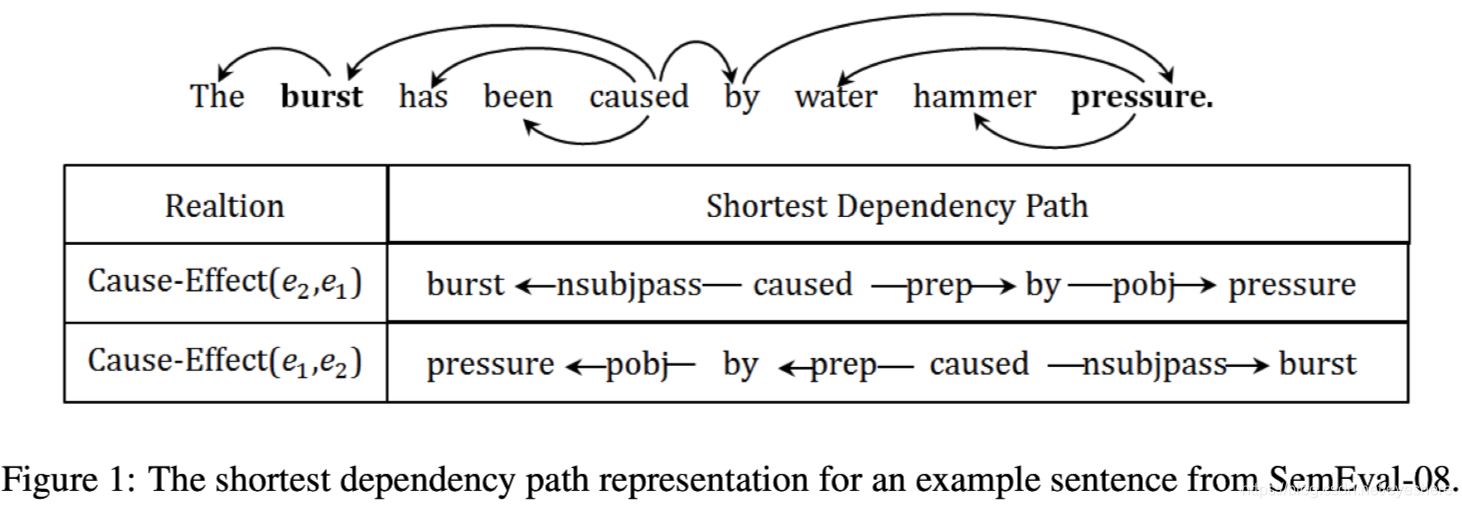
贡献
- 提出RCNN,通过two-channel LSTM捕捉SDP的全局特征,通过CNN捕捉相邻节点的局部特征
- 提出沿着SDP双向BiRCNN,从两个方向去捕捉信息。
模型架构
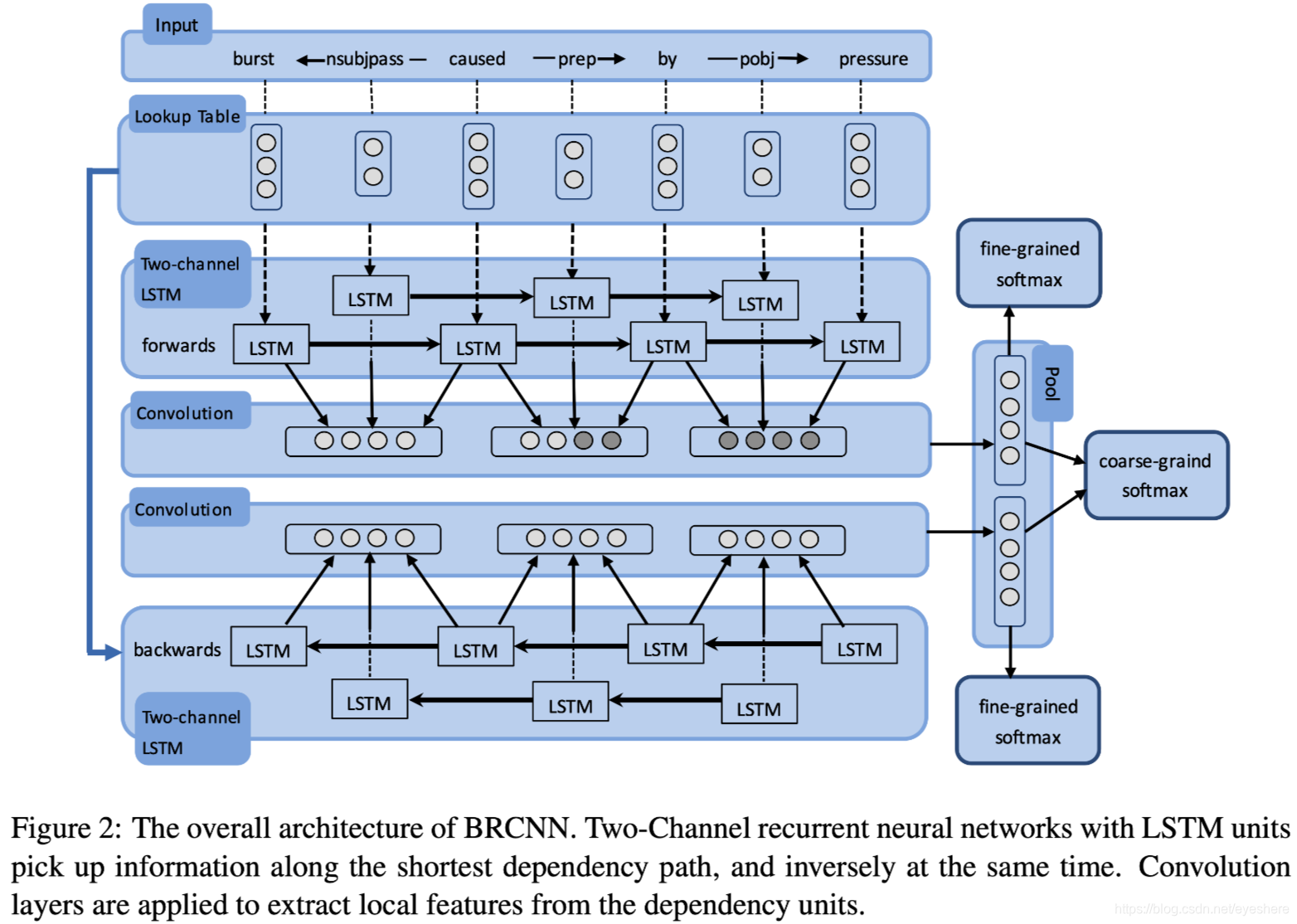
- SDP作为输入,包括words和relation,其中words用预训练向量初始化,relation随机初始化。将words和relation分别通过embedding层送入LSTM组成two-channel LSTM(words和relation分别通过不同的LSTM, 互不影响,是两个channel)
- CONV从LSTM结果中捕捉dependency unit的局部特征(两个word+一个relation),再通过max-pooling搜集全局信息
- 损失函数
其中前两项对应是forward和backward的损失函数,第三项对应拼接forward和backward的损失函数,第4项是l2正则项。
预测:
代码
def model(input_, word_vec_matrix_pretrained, keep_prob, config):
word_vec = tf.constant(value=word_vec_matrix_pretrained, name="word_vec", dtype=tf.float32)
rel_vec = tf.Variable(tf.random_uniform([config.rel_size, config.rel_vec_size], -0.05, 0.05), name="rel_vec", dtype=tf.float32)
#tf.add_to_collection(l2_collection_name, word_vec)
tf.add_to_collection(l2_collection_name, rel_vec)
# 前向two-channel BiLSTM + CNN
with tf.name_scope("look_up_table_f"):
inputs_words_f = tf.nn.embedding_lookup(word_vec, input_["sdp_words_index"])
inputs_rels_f = tf.nn.embedding_lookup(rel_vec, input_["sdp_rels_index"])
inputs_words_f = tf.nn.dropout(inputs_words_f, keep_prob)
inputs_rels_f = tf.nn.dropout(inputs_rels_f, keep_prob)
with tf.name_scope("lstm_f"):
words_lstm_rst_f = lstm_layer(inputs_words_f, length2(input_["sdp_words_index"]), config.word_lstm_hidden_size, config.forget_bias, "word_lstm_f")
rels_lstm_rst_f = lstm_layer(inputs_rels_f, length2(input_["sdp_rels_index"]), config.rel_lstm_hidden_size, config.forget_bias, "rel_lstm_f")
tf.summary.histogram("words_lstm_rst_f", words_lstm_rst_f)
tf.summary.histogram("rels_lstm_rst_f", rels_lstm_rst_f)
with tf.name_scope("conv_max_pool_f"):
conv_output_f = conv_layer(words_lstm_rst_f, rels_lstm_rst_f, input_["mask"], config.concat_conv_size, config.conv_out_size, "conv_f")
pool_output_f = pool_layer(conv_output_f, config)
tf.summary.histogram("conv_output_f", conv_output_f)
tf.summary.histogram("pool_output_f", pool_output_f)
# 后向two-channel BiLSTM + CNN
with tf.name_scope("look_up_table_b"):
inputs_words_b = tf.nn.embedding_lookup(word_vec, input_["sdp_rev_words_index"])
inputs_rels_b = tf.nn.embedding_lookup(rel_vec, input_["sdp_rev_rels_index"])
inputs_words_b = tf.nn.dropout(inputs_words_b, keep_prob)
inputs_rels_b = tf.nn.dropout(inputs_rels_b, keep_prob)
with tf.name_scope("lstm_b"):
words_lstm_rst_b = lstm_layer(inputs_words_b, length2(input_["sdp_rev_words_index"]), config.word_lstm_hidden_size, config.forget_bias, "word_lstm_b")
rels_lstm_rst_b = lstm_layer(inputs_rels_b, length2(input_["sdp_rev_rels_index"]), config.rel_lstm_hidden_size, config.forget_bias, "rel_lstm_b")
tf.summary.histogram("words_lstm_rst_b", words_lstm_rst_b)
tf.summary.histogram("rels_lstm_rst_b", rels_lstm_rst_b)
with tf.name_scope("conv_max_pool_b"):
conv_output_b = conv_layer(words_lstm_rst_b, rels_lstm_rst_b, input_["mask"], config.concat_conv_size, config.conv_out_size, "conv_b")
pool_output_b = pool_layer(conv_output_b, config)
tf.summary.histogram("conv_output_b", conv_output_b)
tf.summary.histogram("pool_output_b", pool_output_b)
with tf.name_scope("softmax"):
# 拼接前向和后向的输出
pool_concat = tf.concat([pool_output_f, pool_output_b], 1)
logits_f, hypothesis_f = softmax_layer(pool_output_f, config.conv_out_size, 19, "softmax_f")
logits_b, hypothesis_b = softmax_layer(pool_output_b, config.conv_out_size, 19, "softmax_b")
logits_concat, hypothesis_concat = softmax_layer(pool_concat, 2*(config.conv_out_size), 10, "softmax_concat")
# L2 regularization
regularizers = 0
vars = tf.get_collection(l2_collection_name)
for var in vars:
regularizers += tf.nn.l2_loss(var)
# loss function
# 损失函数
loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits_f, labels=input_["label_fb"])
loss += tf.nn.softmax_cross_entropy_with_logits(logits=logits_b, labels=input_["label_fb"])
if config.has_corase_grained:
loss += tf.nn.softmax_cross_entropy_with_logits(logits=logits_concat, labels=input_["label_concat"])
loss_avg = tf.reduce_mean(loss) + config.l2 * regularizers
# gradient clip
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss_avg, tvars), config.grad_clip)
#train_op = tf.train.AdamOptimizer(config.lr)
train_op = tf.train.AdadeltaOptimizer(config.lr)
optimizer = train_op.apply_gradients(zip(grads, tvars))
# get predict results
# 预测
prediction = get_prediction(hypothesis_f, hypothesis_b, config.alpha)
correct_prediction = tf.equal(prediction, tf.argmax(input_["label_fb"], 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
loss_summary = tf.summary.scalar("loss", loss_avg)
accuracy_summary = tf.summary.scalar("accuracy_summary", accuracy)
grad_summaries = []
for g, v in zip(grads, tvars):
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.histogram("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
summary = tf.summary.merge_all()
return loss_avg, accuracy, prediction, optimizer, summary
