笔记内容:

一、模块
Python越来越被广大程序员使用,越来越火爆的原因是因为Python有非常丰富和强大标准库和第三方库,几乎可以实现你所想要实现的任何功能,并且都有相应的Python库支持,比如用于简单绘图的turtle标准库,网络爬虫的requests请求库、解析库lxml、BeautifulSoup等等的第三方库这些都是Python的模块。这些库也就是我们所说的模块。
标准库:不需要下载安装就可以直接引用的库,都是标准库。
第三方库:需要我们下载安装的库,都是第三方库。
在使用模块时我们要提前引用库
import:在导入库的时候我们要使用import来导入库,比如:import sys
Python中的sys模块是一个用来处理Python运行时环境的模块,它提供了许多函数和变量来处理Python运行时环境的不同部分。
1 import sys 2 print(sys.platform)
输出结果:win32
使用import导入sys库,每个库中都有很多方法,在使用方法时要用点来使用,sys.platform是获取当前系统平台的方法。
1 import sys 2 print(sys.path)
输出结果:
['C:\\Users\\Administrator\\PycharmProjects\\untitled', 'C:\\Users\\Administrator\\PycharmProjects\\untitled', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python38-32\\python38.zip', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python38-32\\DLLs', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python38-32\\lib', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python38-32', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python38-32\\lib\\site-packages']
sys.path打印出一个又一个的路径,这一个有一个的路径就是Python的全局环境变量,这路径里面存的就是Python导入库或者Python自己进行一些调用的时候就到这些路径里来寻找。也就是说无论是什么库,只要调用就肯定在这些路径中其中的一个里面,如果没找到就说明没有安装。Python一般装的第三方库都存在C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python38-32\\lib\\site-packages里面。安装的第三方库库会自动安装到site-packages里。而一般的标准库都存在C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python38-32\\lib里,也就是site-packages的上一级目录。
这些都是Python的标准库,这里面有很多是我们以后常用的库。
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数,如:临时文件夹位置和系统文件夹位置等。
1 import sys 2 print(sys.argv)
在集成开发环境PyCharm中如果直接运行上述代码会打印出该脚本的绝对路径。
sys.argv的作用是实现从程序外部向程序传递参数。
1 import os 2 os.system("dir")
输出结果:
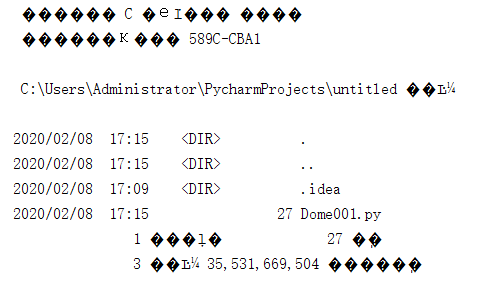
os模块提供了多数操作系统的功能接口函数。
dir在Windows中DOS命令为查看当前目录中的所有文件,我们使用os模块可以在Python中直接使用DOS命令dir,我们看到在输出结果上有很多的乱码,这是因为,Windows的编码方式与Python的UTF-8不同,所以才会出现乱码。
在使用os.system()方法,运行的是命令,这个命令产生的结果是无法保存的,如果想要保存产生的结果需要使用os.popen(),但是这个方法打印出来是地址,我们需要读取这个地址中所存的数据,就要使用.read()来读取数据。
1 import os 2 DOS = os.popen("dir") 3 print(DOS)
输出结果:<os._wrap_close object at 0x02AF3E38>
import os DOS = os.popen("dir").read() print(DOS)
输出结果:

上述这些就是模块的例子,只列举了两个模块中的几个方法,暂时知道模块是什么,怎么使用。
第三方库是基本都是一些大佬写出来我们直接下载安装使用的库,而我们自己也可以写一个模块,但是切记模块名不要用中文!!!我们自己写完的库也可以放到site-packages中。
二、PyCharm
工欲善其事必先利其器,每个语言都有自己的集成开发环境,Python比较优秀的集成开发环境就是Pycharm。
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
PyCharm是英文的开发环境所以需要一点英文基础,如果英文基础不太好的话那就需要慢慢探索熟能生巧。
Pycharm的下载安装可以参考百度经验中的【PyCharm的下载与安装】,熟练掌握编程环境的使用才是效率的根本。
简述Python的运行过程:
PyCodeObject和pyc文件,pyc文件是py文件编译后生成的字节码文件。pyc文件经过python解释器最终会生成机器码运行。而其实PyCodeObject则是Python编译器真正编译成的结果。在Python程序运行时,编译结果保存在PyCodeObject中,当Python程序结束运行时,Python解释器将PyCodeObject写回到pyc文件中。当Python程序第二次运行的时候,程序首先会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就会重复上述过程,所以也就是可以理解为pyc文件是PyCodeObject的一种持久化保存方式。
三、数据类型
1.数字
(1)int整型:不带小数点的整数。
(2)float浮点型:带小数点的数一般都称为浮点数。
科学计数法:26E5与26*10**4是相等的
2.布尔值
真或者假,1或者0。
3.字符串
name = 'Machine'
三元运算:
1 a,b=1,4 2 d = a if a>b else b 3 print(d)
意思是如果a>b,d的值为a,如果a<b,d的值便为b。三元运算十分的方便省去了冗杂的代码,直接一行代码解决。
四、列表与元组
大学生活总是那么惬意且美好,一群沙雕室友总是能带来无穷无尽的乐趣,让我在编程中也会闪烁出他们的名字。
我想把这些人的名字存起来
names = "徐某 赵某 田某某 靳某某 王某 周某某 陈某"
把这些人的名字变成一个字符串,赋给names这个变量,这样把他们的名字都存起来了,但是如果我们想要取出其中一个人的名字那那就十分的不方便,因为这些人的名字是一个字符串,所以Python就用其他方式来进行存储数据,它就是列表,一种数据类型。
names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某']
这样就把这些人的名字存储到了列表中,也就是说 变量名 = [ ],这样的数据就是列表。
而我们要想取出某人时就需要使用索引来取出数据,比如我们想要取出靳某某:
names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] print(names[3])
3就是靳某某的索引,计算机的数都是从0开始的所以徐某某的索引是0,赵某某是1,·········陈某某是6。这样我们只要直到元素的索引就可以取出这个数据元素。
如果我们想要同时取出两个数据的话就要在引入一个新的知识,切片。
1 names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] 2 print(names[3:5])
names[3:5]就取出了靳某某和王某,3是靳某某的索引而5是周某某的索引,为什么却只打印出两个人的名字呢?这是因为在切片里有一个规定就是中括号里的索引是半闭半开的,也就是说3:5是指从索引为3的数据元素开始一直取到元素为5-1的数据元素。同时切片也是可以连续切片的。切片这个名称很贴合实际,就像我们在切菜时取其中一段,我们用刀切取出来,需要切两刀。
索引是可正可负的,如果为正就从列表的前面开始,如果为负就从列表的后面开始。
names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] print(names[-1])
name[-1]就把最后的陈某取出来了,用的索引进行切片的时候也要注意把两个数中小的索引写到冒号前面,大的放到冒号的后面。
增:现在我想要在这个列表的基础上再添加一些元素的话我们就要使用.append()来添加元素。
names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] names.append('朱某某') print(names)
输出结果:
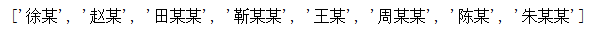
通过.append()我们将朱某某添加到了这个列表中。通过这个方法把一个新的元素插入到列表的最后面,如果我们想要把新的元素插入特定的位置我们就不能使用.append()来进行插入,因为.append()把新的元素插入到列表的最后。
1 names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] 2 names.append('朱某某') 3 names.insert(0,'张某某') 4 print(names)
.insert()里面有两个参数,一个是索引,一个是所插入的元素,将新的元素插入到指定位置,原来所在这个位置的元素向后顺延,整个列表边长+1,列表是不可以批量插入的,只能一个数据一个数据的插入。
改:在列表中如果有某个元素是错误的我们可以直接进行更改。
1 names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] 2 names[0] = '朱某某' 3 print(names)
从代码中我们可以看出,列表的第一个元素是徐某某,而我们更改后变成了朱某某,也就是说我们如果想要更改某个元素,可以直接用索引赋值即可。
删:列表中的数据如果我们想要删除的话,我们有很多方法来对数据进行删除。
1 names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] 2 names.remove('徐某') 3 del names[-1] 4 print(names)
输出结果:

使用.remove()来指定数据删除,del来删除指定索引位置的数据。
同时还有一种方法
1 names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] 2 names.pop(0) 3 print(names)
.pop()也是指定索引来删除数据元素,如果在括号内不指定元素的话就会默认删除列表的最后一个。
对于数据量小的列表我们可以非常容易的进行操作,但是如果我们面对的是一个超级长的列表,一个包含学校所有人名字的列表的话想要找到某个人并且把他的名字提取出来就不是通过眼睛看,动手查就能实现的了,于是我们就要用到.index()来对元素进行查找。
1 names = ['徐某','赵某','田某某','靳某某','王某','周某某','陈某'] 2 number = names.index('田某某') 3 print(number)
我们使用.index()来对整个列表查找这个田某某,并且返回他的索引。如果在整个列表中没有这数据元素就会报错。
如果在列表中有很多个相同的数据元素我们可以使用.count()对其进行统计个数
names = ['徐某','赵某','田某某','靳某某','王某','田某某','周某某','田某某','陈某'] print(names.count('田某某'))
显然易见输出结果是3。
在对列表的操作中还有一个函数.copy,.copy是浅拷贝之会复制列表的第一层,如果是嵌套列表的话就会发生变化。
1 names1 = [['朱某某,张某某'],'徐某','赵某','靳某某','王某','周某某','田某某','陈某'] 2 names2 = names1.copy() 3 names1[-1] = 'Chen' 4 names1[0][0] = 'Zhu' 5 print(names1) 6 print(names2)
显示结果:

第3行我们把names1列表的最后一个值变为英文Chen,而names2却没有发生变化,第4行我们把位于names1列表索引为0的子列表中的第一个元素改为Zhu,names2也跟着发生变化,这是引文.copy是浅拷贝对于正常的元素就会进行复制,但是对于嵌套的子列表复制的只是列表的存储地址,names1对于子列表的改变没有改变其地址,在打印names2时会到相应的地址中去找,所以会随着names1的改变而改变。
除了浅复制还有深复制
在使用深复制.deepcopy()时我们需要导入模块这个模块的名字是copy。
1 import copy 2 3 names1 = [['朱某某,张某某'],'徐某','赵某','靳某某','王某','周某某','田某某','陈某'] 4 names2 = copy.deepcopy(names1) 5 names1[-1] = 'Chen' 6 names1[0][0] = 'Zhu' 7 print(names1) 8 print(names2)
显示结果:

这里就能看到names1完全被names2复制,是完全独立的两个列表。
names2 = names1和copy是不一样的,因为前者names1与names2的地址完全相同,指向同一地址,而copy的使用让names1与names2是两个地址。
对于列表的操作还有很多,比如.clear()清除,.extend()合并等等,这些函数都是我们们对于列表常用的操作,应该熟练掌握。
元组:
元组和列表大致相同,也被称为不可修改的列表,也是用来存储数据,元组一旦创建,便不可修改,元组又称为只读列表,列表用方括号,而元组用括号。
1 names1 = ('徐某','赵某','靳某某','王某','周某某','田某某','陈某')
元组只有两个方法,一个是count,一个是index,与列表的用法相同。一些不修改的数据用元组来存储
五、字典
字典是一种Key-value的数据类型,每个键对应键值。
1 Students = { 2 'student01':"靳某某", 3 'student02':"徐某", 4 'student03':"赵某" 5 }
这样的数据类型就是字典,用逗号分隔每组数据,冒号前面的是键,冒号后面的是键值,整体用花括号括起来。
字典是无序的,无法通过索引取出来,所以只能通过键Key来取值
1 Students = { 2 'student01':"靳某某", 3 'student02':"徐某", 4 'student03':"赵某" 5 } 6 print(Students['student01'])
输出结果:靳某某
如果想要修改可以直接通过键进行修改
1 Students = { 2 'student01':"靳某某", 3 'student02':"徐某", 4 'student03':"赵某" 5 } 6 print(Students) 7 Students['student01'] = '田某某' 8 print(Students)
输出结果:

可以看到靳某某被改成了田某某。
1 Students = { 2 'student01':"靳某某", 3 'student02':"徐某", 4 'student03':"赵某" 5 } 6 print(Students) 7 Students['student04'] = '田某某' 8 print(Students)
输出结果:

如果想要插入一个新的数据时可以直接写一个新的键并对键进行赋值。
字典也可以进行删除
1 Students = { 2 'student01':"靳某某", 3 'student02':"徐某", 4 'student03':"赵某" 5 } 6 print(Students) 7 del Students['student01'] 8 print(Students)
输出结果:

del在字典中也是删除,在列表中也是删除,因为del时Python内部自带的删除方式。
1 Students = { 2 'student01':"靳某某", 3 'student02':"徐某", 4 'student03':"赵某" 5 } 6 print(Students) 7 Students.pop('student02') 8 print(Students)
显示结果:

.pop也是一种删除方法,还有一种删除方法是.popitem()是随机删除一个元素。
在查找获取字典中的值的时候推荐使用.get()因为这种方法不会报错,如果有就返回值,如果没有就返回None。
1 Students = { 2 'student01':"靳某某", 3 'student03':"赵某", 4 'student02':"徐某" 5 } 6 print(Students.get('student01')) 7 print(Students.get('student04'))
输出结果:

还有一种验证数据是否存在与字典中的方法是
Students = { 'student01':"靳某某", 'student03':"赵某", 'student02':"徐某" } print('student01' in Students)
输出结果:
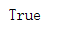
如果存在就返回True,如果没有就返回False。
无论是列表和字典都是可以进行嵌套的,例如列表中的数据元素可以是任何数据类型包括列表和字典,而字典的Value也是可以是任何数据类型。
小的时候总以为兴趣是最好的老师,后来才明白原来高薪才是。