今天主要对从CSDN爬取的标题利用jieba(结巴)进行分词,但在分词过程中发现,如大数据被分成了大/数据,云计算被分隔成了云/计算。
后来又从百度百科---》信息领域爬取了相关词语作为词典,预计今天晚上完成切词任务。
其中分割代码如下:
1 import jieba 2 import io 3 4 #对句子进行分词 5 def cut(): 6 f=open("E://luntan.txt","r+",encoding="utf-8") 7 for line in f: 8 seg_list=jieba.cut(line) 9 #print(' '.join(seg_list)) 10 for i in seg_list: 11 print(i) 12 write(i+" ") 13 #write(' '.join(seg_list)) 14 15 16 #分词后写入 17 def write(contents): 18 f=open("E://luntan_cut.txt","a+",encoding="utf-8") 19 f.write(contents) 20 print("写入成功!") 21 f.close() 22 23 #创建停用词 24 def stopwordslist(filepath): 25 stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] 26 return stopwords 27 28 # 对句子进行去除停用词 29 def seg_sentence(sentence): 30 sentence_seged = jieba.cut(sentence.strip()) 31 stopwords = stopwordslist('E://stop.txt') # 这里加载停用词的路径 32 outstr = '' 33 for word in sentence_seged: 34 if word not in stopwords: 35 if word != '\t': 36 outstr += word 37 outstr += " " 38 return outstr 39 40 #循环去除 41 def cut_all(): 42 inputs = open('E://luntan_cut.txt', 'r', encoding='utf-8') 43 outputs = open('E//luntan_stop', 'w') 44 for line in inputs: 45 line_seg = seg_sentence(line) # 这里的返回值是字符串 46 outputs.write(line_seg + '\n') 47 outputs.close() 48 inputs.close() 49 50 if __name__=="__main__": 51 cut()
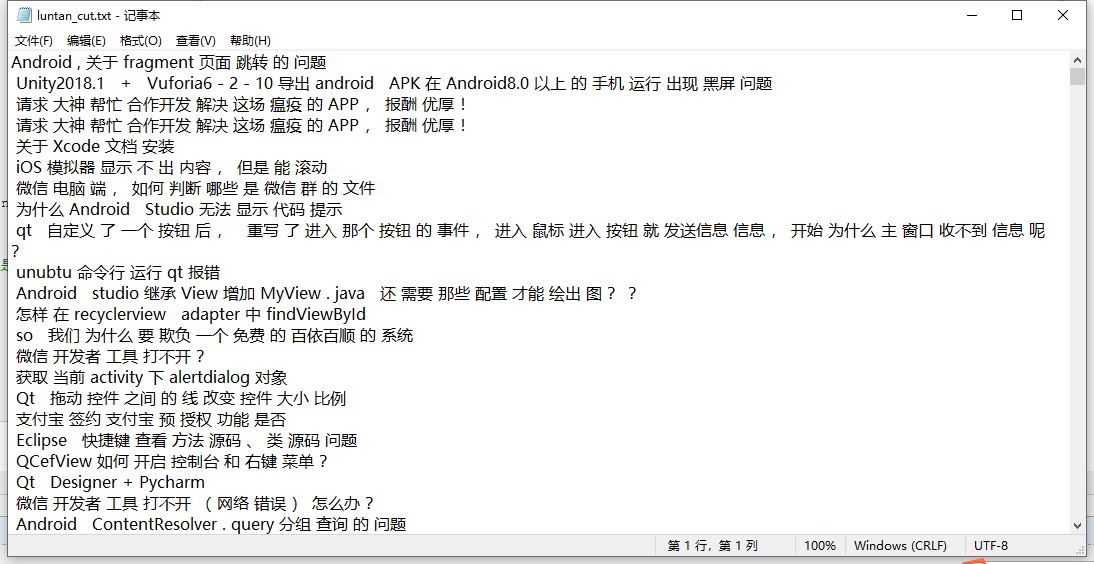
分割后的文本
从百度爬取词典要把百度页面 地址:https://baike.baidu.com/wikitag/taglist?tagId=76607
该页拉到最下,并存为本地mhtml格式,在浏览器打开然后右击查看源代码,源代码保存为txt格式文件,
代码如下:
1 import io 2 import re 3 4 patton=re.compile(r'title=".*"') 5 def read(): 6 f=open("E://mhtml.txt","r+",encoding="utf-8") 7 for line in f: 8 line=line.rstrip("\n") 9 m=patton.findall(line) 10 #print(line) 11 if len(m)!=0: 12 print(m) 13 write(str(m).lstrip("['title=\"").rstrip("\"']")+"\r") 14 15 def write(contents): 16 f=open("E://xinxi.txt","a+",encoding="utf-8") 17 f.write(contents) 18 print("写入成功!") 19 f.close() 20 21 if __name__=="__main__": 22 read()
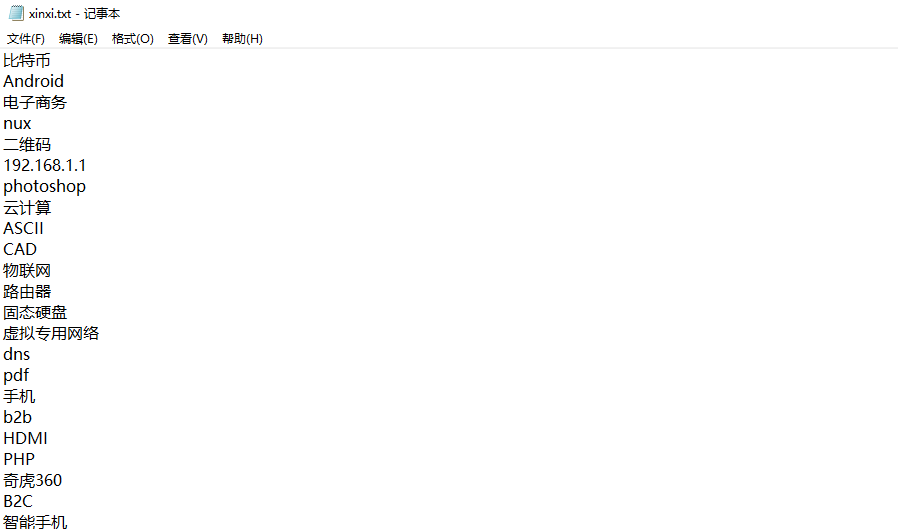
效果: