学习笔记(13-14章)
本博客内容基本整理自《Hbase原理与实践》一书。仅用于个人学习和积累。
1.HBase系统调优
1.1.HBase-HDFS调优
HBase服务通过调用HDFS的客户端对数据进行读写操作,因此对HDFS客户端的相关优化也会影响HBase的读写性能。这里主要关注如下三个方面。
Short-Circuit Local Read :对于本地数据,Short Circuit Local Read策略允许客户端绕过DataNode直接从磁盘上读取本地数据,因为不需要经过DataNode而减少了多次网络传输开销,因此数据读取的效率会更高。Hedged Read :根据Hedged Read策略,如果在指定时间内读取请求没有返回,HDFS客户端将会向第二个副本发送第二次数据请求,并且谁先返回就使用谁,之后返回的将会被丢弃。Region Data Locality :即数据本地率,表示当前Region的数据在Region所在节点存储的比例。
1.2.HBase读写性能调优
HBase系统的读取优化可以从三个方面进行:服务器端、客户端、列簇设计。HBase写入性能主要从HBase服务端以及客户端两个方面进行优化。
1.2.1.HBase读取性能优化
- 服务器端:读请求是否均衡;BlockCache设置是否合理;HFile文件是否太多;Compaction是否消耗过多系统资源;数据本地率是不是过低。
- 客户端:scan缓存设置是否合理;get是否使用批量请求;请求是否可以显式指定列簇或列;离线批量读取请求是否设置禁止缓存。
- 列簇设计:布隆过滤器是否设置。
1.2.2.HBase写入性能优化
- 服务器端:Region是否太少;写入请求是否均衡;
Utilize Flash storage for WAL; - 客户端:是否可以使用Bulkload方案写入;是否需要写WAL;WAL是否需要同步写入;Put是否可以同步批量提交;Put是否可以异步批量提交;写入KeyValue数据是否太大。
1.3.HBase操作系统调优
HBase官方文档对Linux操作系统环境有几点配置要求:
•Set vm.min_free_kbytes to at lease 1GB(8GB on larger memory systems)
•Set vm.swappiness=0
•Disable NUMA zone reclaim with vm.zone_reclaim_mode=0
•Turn transparent huge pages(THP) off:
Linux内存回收对象主要分为两种:文件缓存以及匿名内存。
1.3.1.swap基本概念
swap意思是交换,顾名思义,当某进程向OS申请内存却发现内存不足时,OS会把内存中暂时不用的数据交换出去,放在swap分区中,这个过程称为swap out。当某进程又需要这些数据且OS发现还有空闲物理内存时,又会把swap分区中的数据交换回物理内存中,这个过程称为swap in。
1.3.2.THP概念
HugePage是一种大页理论,那具体怎么使用HugePage特性呢?目前系统提供了两种使用方式,一种称为Static Huge Pages,另一种就是Transparent Huge Pages。前者顾名思义是一种静态管理策略,需要用户自己根据系统内存大小手动配置大页个数,这样在系统启动的时候就会生成对应个数的大页,后续将不再改变。
THP(Transparent Huge Pages)是一种动态管理策略,它会在运行期动态分配大页给应用,并对这些大页进行管理,对用户来说完全透明,不需要进行任何配置。另外,目前THP只针对匿名内存区域。
THP关闭的场景下(never)HBase性能最优,比较稳定,因此HBase线上切记要关闭THP
2.HBase运维案例分析
HBase运维在本书第十二章主要对运维的理论原理方面进行了分析,这一章结合具体的案例进行了详细的分析,并且在最后有作者的分析思路总结,这一章适合重复阅读。下面我主要整理了书中提到的问题,详细的分析和解决方案见书本。
2.1.RegionServer宕机
- 长时间GC导致RegionServer宕机:长时间Full GC导致RegionServer宕机在前文也有提到,80%的宕机都是由于该原因导致。排查日志可以直接搜索两类关键字——
a long garbage collecting pause或者ABORTING region server。 - 系统严重Bug导致RegionServer宕机
- 大字段scan导致RegionServer宕机
- close_wait端口耗尽导致RegionServer宕机
上述问题现象都为收到RegionServer进程退出的报警。
2.2.HBase写入异常
案例一: MemStore占用内存大小超过设定阈值导致写入阻塞。
现象:整个集群写入阻塞,业务反馈写入请求大量异常。
案例二: RegionServer Active Handler资源被耗尽导致写入阻塞
- 大字段写入导致Active Handler资源被耗尽。
现象:集群部分写入阻塞,部分业务反馈集群写入忽然变慢并且数据开始出现堆积的情况。 - 小集群IO离散型随机读取导致Active Handler资源耗尽。
现象:集群部分写入阻塞,部分业务反馈集群写入忽然变慢并且数据开始出现堆积的情况。
案例三: HDFS缩容导致部分写入异常。
现象:业务反馈部分写入请求超时异常。此时HBase运维在执行HDFS集群多台DataNode退服操作。
2.3.HBase运维问题分析思路
遇到问题我们必然会经历如下三个阶段:问题定位,问题分析,问题修复。
问题定位的基本流程如下:
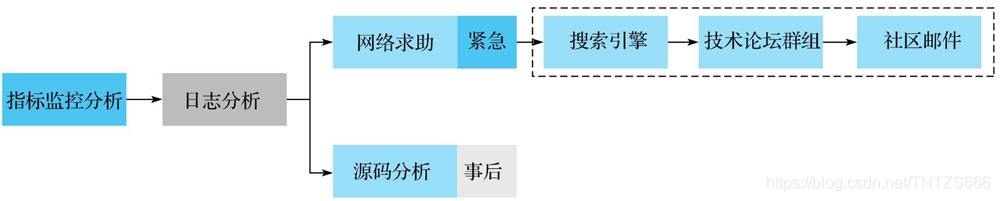
其中,大部分系统性能问题都可以直接在指标监控界面上直观地找到答案。对问题定位有用的监控指标非常多,宏观上看可以分为系统基础指标和业务相关指标两大类。系统基础指标包括系统IO利用率、CPU负载、带宽等;业务相关指标包括RegionServer级别读写TPS、读写平均延迟、请求队列长度/Compaction队列长度、MemStore内存变化、BlockCache命中率等。
对于系统异常类型的问题,需要对相关日志进行分析,HBase系统相关日志最核心的有RegionServer日志和Master日志,另外,GC日志、HDFS相关日志(NameNode日志和DataNode日志)以及ZooKeeper日志在特定场景下对分析问题都有帮助。
3.总结
今天学习了HBase系统调优和书中的一些HBase运维案例。关于系统调优这一块,书中从GC,操作系统,HDFS,读写性能等方面进行了阐述,而调优是需要建立在对某个组件很熟悉的情况下才可以去做的一件事,毕竟优化起到的锦上添花的作用。通过这一部分的阅读,让我对HBase之后调优有了明确的方向,之后如果有能力会去尝试玩一下。第十四章的案例分析可以说是很实在了。书中针对一些异常情况举了具体的案例,每个案例不仅有问题发生的现象,还有定位和分析的过程,并给出了解决方案,如果在平时遇到类似的问题,可以起到一个很好的借鉴作用。此外作者还分享了自己对于问题分析的心得。对比下来,其实在问题定位阶段的流程确实如作者所说的一样,先从直观的监控页面上观察是否有异常,然后通过日志排查,之后可以上网搜索等等。对于这些步骤其实对于其他组件也基本是大同小异,关键在于我们自己需要在遇到问题后能否比较迅速地找到问题发生的具体位置,比如监控页面上哪个参数有异常了,哪个部分的日志里有报错或者异常信息。这些就需要我们自己经验积累了。不然就像现在,书中明确告诉了我有哪些相关日志可以查看,但真的遇到问题时还是需要根据经验才能快速地获取到自己想要的信息。
