1、DataFrame数据结构的解释说明

index表示的是行索引,column表示的是列索引,values表示的是数值,其实不管是行索引,还是列索引都可以看作是索引Index。从每一行看,DataFrame可以看作是一行行的Series序列上下堆积起来的,每个Series的索引就是列索引[0,1,2,3];从每一列看,DataFrame可以看作是一列列的Series序列左右堆积起来的,每个Series的索引就是行索引[0,1,2]。
DataFrame的默认理解方式是:DataFrame其实就是由很多个数据类型不一样的列Series组成。对于上图,此DataFrame其实就是由如下四个Series组成,它们的索引都是行索引[0,1,2]。
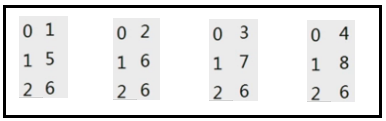
可以把一个DataFrame,类比成MySQL中的一张表:
MySQL表中,每个列字段的数据类型基本都不一样,每张表都有很多个列字段;
如果把MySQL表中的每个列看做是一个数据类型的Series,一张MySQL表就可以看做是由很多个数据类型不一样的Series组成,和我们上面讲述的一致。
2、DataFrame的index属性和columns属性
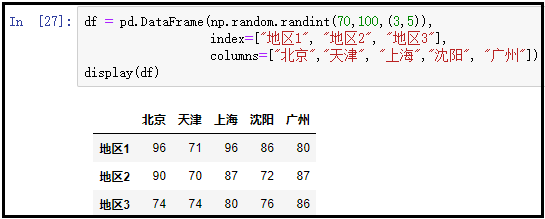
1)构造一个DataFrame
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(70,100,(3,5)),
index=["地区1", "地区2", "地区3"],
columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
结果如下:
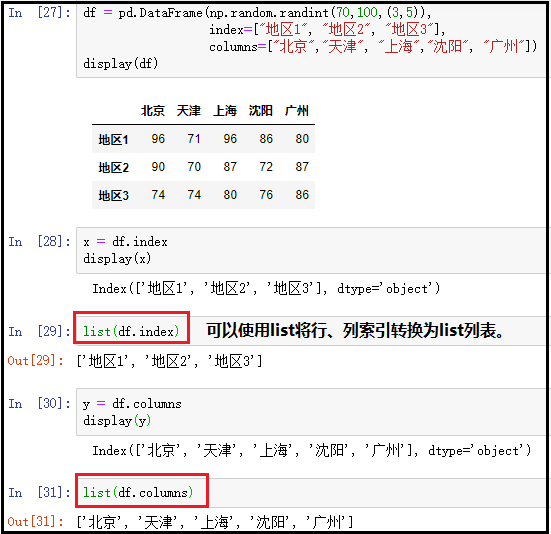
2)index和columns属性
df = pd.DataFrame(np.random.randint(70,100,(3,5)),
index=["地区1", "地区2", "地区3"],
columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
x = df.index
display(x)
list(df.index)
y = df.columns
display(y)
list(df.columns)
结果如下:
① 修改行索引:df.index
df = pd.DataFrame(np.random.randint(70,100,(3,5)),
index=["地区1", "地区2", "地区3"],
columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
df.index = ["a","b","c"]
display(df)
结果如下:

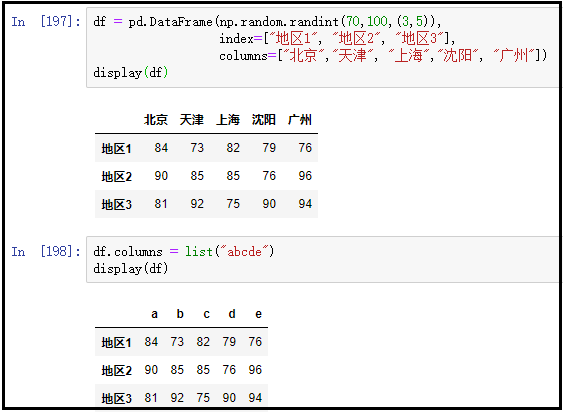
② 修改列索引:df.columns
df = pd.DataFrame(np.random.randint(70,100,(3,5)),
index=["地区1", "地区2", "地区3"],
columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
df.columns = ["a","b","c"]
display(df)
结果如下:
3)DataFrame的索引对象Index
观察“DataFrame的数据结构图”可以发现:每个df既有一个行索引index,又有一个列索引columns。但是不管行索引index,还是列索引columns,统一都都叫做 “Index对象”。不同的是在创建df,指定参数的参数名称的时候,为了方便区分行索引和列索引 ,把行索引这个“Index对象”叫做index,把列索引这个“Index对象”叫做columns 。
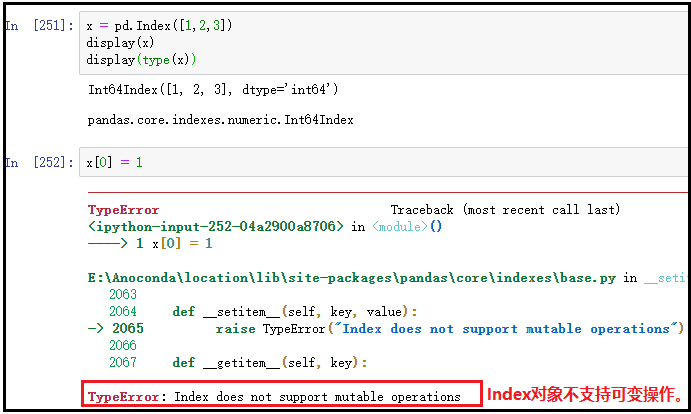
记住:Index索引对象中的元素不支持修改。
# pd.Index()用于创建一个Index对象
x = pd.Index([1,2,3])
display(x)
display(type(x))
x[0] = 1
结果如下:
3、name属性
1)怎么理解DataFrame的name属性

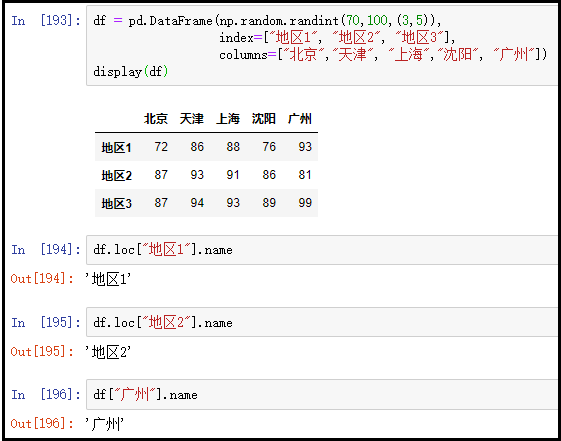
我们知道:取出DataFrame中的每一行、每一列都是一个Series,组成这个DataFrame对象的每个sereis都有一个名称,这个名称,就是对应的那一行、列的索引。如图所示 ,上述有“红橙黄绿蓝靛紫黑”八种颜色,分别编号为1-8,每个号对应的都是一个Series。Series1的name为“地区1”,Series2的name为“地区2”…Series8的name为“广州”。
接下来,我们使用代码检验一下。
df = pd.DataFrame(np.random.randint(70,100,(3,5)),
index=["地区1", "地区2", "地区3"],
columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
df.loc["地区1"].name
df.loc["地区2"].name
......
df["广州"].name
结果如下:
2)为行索引、列索引设置name名称属性:df.index.name和df.columns.name
df = pd.DataFrame(np.random.randint(70,100,(3,5)),
index=["地区1", "地区2", "地区3"],
columns=["北京","天津", "上海","沈阳", "广州"])
display(df)
df.index.name = "index_name"
df.columns.name = "columns_name"
display(df)
结果如下:
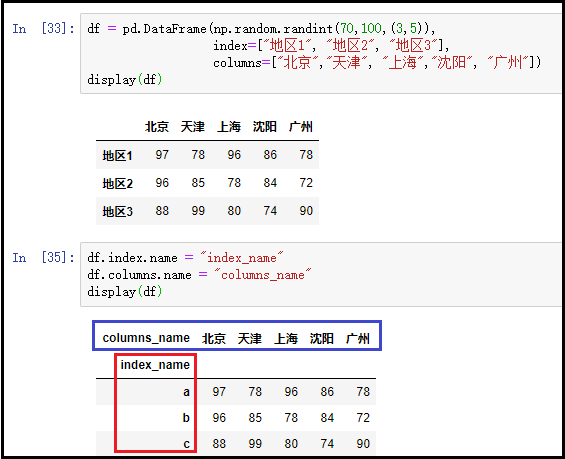
综上所述:通过上面的演示,我们不仅DataFrame的每一行、每一列有一个name名称,并且我们还可以给DataFrame的行索引和列索引分别设置一个name名称。
