扁平化映射 | flatMap
扁平化映射也是将来用得非常多的操作,也是必须要掌握的。
定义
可以把flatMap,理解为先map,然后再flatten

map是将列表中的元素转换为一个List
flatten再将整个列表进行扁平化
方法签名
scala def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): TraversableOnce[B]
方法解析
| flatmap方法 | API | 说明 | | ----------- | ------------------------------ | ------------------------------------------------------------ | | 泛型 | [B] | 最终要转换的集合元素类型 | | 参数 | f: (A) ⇒ GenTraversableOnce[B] | 传入一个函数对象
函数的参数是集合的元素
函数的返回值是一个集合 | | 返回值 | TraversableOnce[B] | B类型的集合
案例
案例说明
有一个包含了若干个文本行的列表:“hadoop hive spark flink flume”, “kudu hbase sqoop storm”
获取到文本行中的每一个单词,并将每一个单词都放到列表中
思路分析
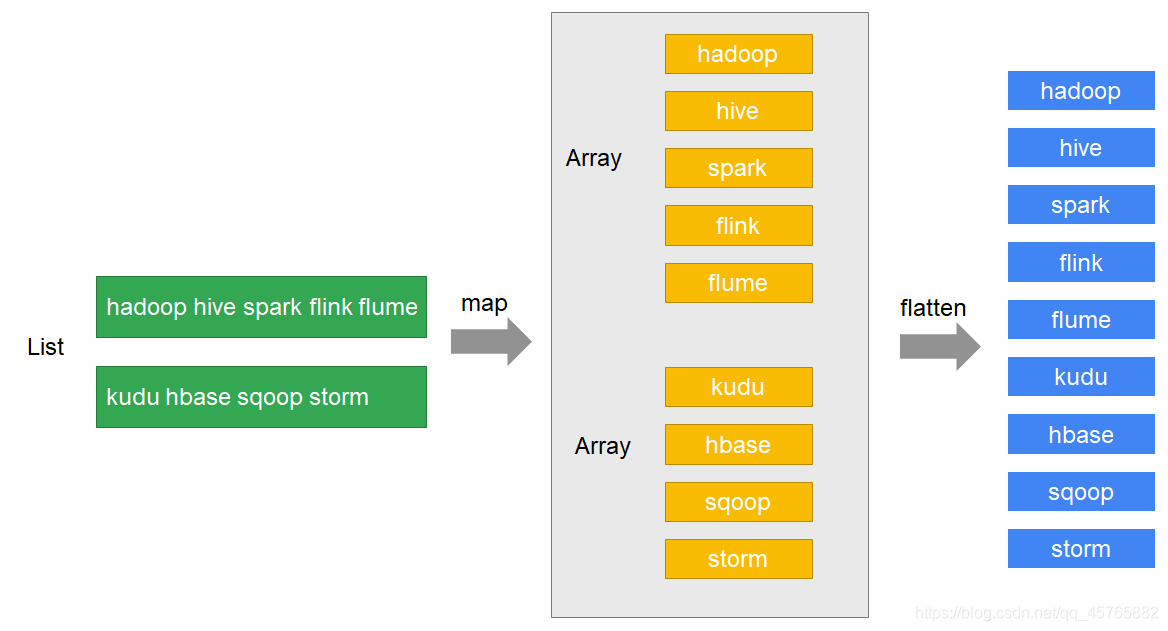
步骤
使用map将文本行拆分成数组 再对数组进行扁平化
参考代码
scala // 定义文本行列表
scala> val a = List("hadoop hive spark flink flume", "kudu hbase sqoop storm")
a: List[String] = List(hadoop hive spark flink flume, kudu hbase sqoop storm)

// 使用map将文本行转换为单词数组
scala> a.map(x=>x.split(" "))
res5: List[Array[String]] = List(Array(hadoop, hive, spark, flink, flume), Array(kudu, hbase, sqoop, storm))
 // 扁平化,将数组中的
// 扁平化,将数组中的
scala> a.map(x=>x.split(" ")).flatten
res6: List[String] = List(hadoop, hive, spark, flink, flume, kudu,hbase, sqoop, storm)

使用flatMap简化操作
参考代码
scala scala> val a = List("hadoop hive spark flink flume", "kudu hbase sqoop storm")
a: List[String] = List(hadoop hive spark flink flume, kudu hbase sqoop storm)

scala> a.flatMap(_.split(" "))
res7: List[String] = List(hadoop, hive, spark, flink, flume, kudu, hbase, sqoop, storm)

