python网络爬虫一(对爬虫的理解)
大家好,这是我的第一个关于python网络爬虫的案例,请多多指教。
由于对python好奇的缘故,网上各种说“人生苦短,我选python”。自从开始学习python之后,不由得发现,python简单易学,而且功能强大。
前言
第一次接触到网络爬虫。自己还是一个大二的小白,对很多外面的技术一无所知。偶然一次机会有幸进入一家金融公司学习,在IT部门待了一个月,从那开始身边的技术大牛给我讲解各种技术知识。学习的第一步就是看WebMagic爬虫框架。一个用Java实现的网络爬虫框架,WebMagic很适合小白去了解爬虫,虽然那个时候以我的基础硬是死记硬背了下来。但是从那开始之后,便在心里埋下了学习爬虫的种子。有兴趣的同学可以去看一下https://webmagic.io/docs/zh/ 。现在看来通俗易懂。
正文
好啦!开始开启我们的网络爬虫之旅。
什么是网络爬虫?
为了言简意赅,我们可以把网络比喻成一张由蜘蛛织成的大网,Spider可以在这张大网上按照一定的规则进行爬行,从而获取大网上的节点信息。
网络爬虫的工作原理
网络爬虫,即从一个或若干个初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足一定条件才会停止爬取。具体的流程如图:
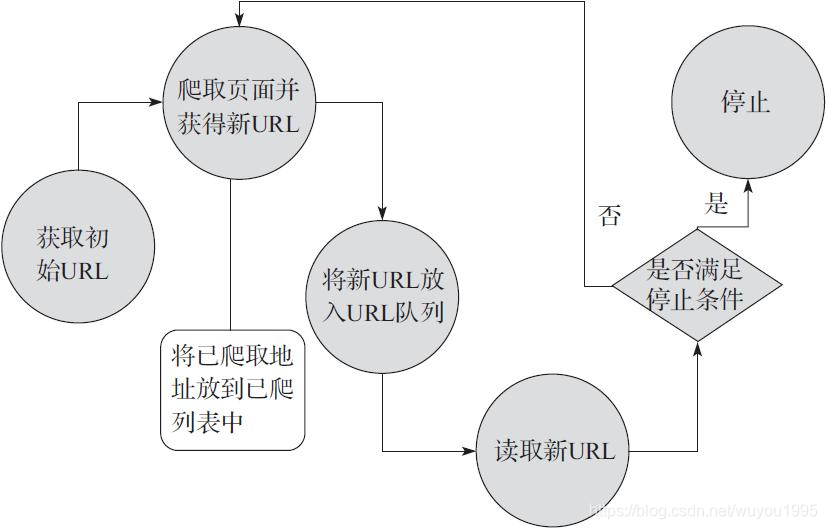
相信大家对爬虫工作原理有了深刻的印象。那么爬虫能干些啥呢?
爬虫最早来源于搜索引擎,可以使用爬虫来抓取Web网页、文档、甚至图片、音频、视频等资源,用于对网络数据的抓取和处理。只要你有想法,你可以抓取任何对你有用的数据。
学习网络爬虫需要晓的些什么?
- 首先对网络爬虫的工作原理要了解是必须的
- 还需了解URL(统一资源定位符)、超级链接、HTTP协议(Request/Response)、HTTP认证、HEAD方法、Cookie机制、DNS本地缓存这些网络的基本知识
- 当然对前端HTML、CSS、JavaScript能看的懂,便于对页面元素的提取
- 既然是python爬虫,那么python 同样要花点时间去看看基础语法。
总所周知,爬虫是按照一定规则自动化的。那非自动化爬取的流程是什么呢?浏览器和服务端的交互是什么样的?
非自动化爬取也就是人为爬取,打开浏览器----目标页面----可访问的超链接----依次点击每页超链接页面中的页面。如此循环。也就是人们日常浏览网页的顺序。
重点还是关于浏览器与服务端交互的过程。按照我的理解,如图:

用户在浏览器输入URL,浏览器的主线程会创建一个子线程,同时讲URL传递给子线程交由子线程处理。子线程会向DNS发送DNS 请求,查询URL对应的IP地址。DNS会返还给IP地址,子线程拿到IP地址后,浏览器才能与服务器建立连接,子线程向服务器发送HTTP Request请求,服务器会返回HTTP Response响应信息给浏览器,紧接着浏览器会根据响应信息进行页面解析,将页面呈现给用户。
这些只是我对爬虫的一些理解。每个人都有不同的理解。希望能帮助到大家。
其实人跟树是一样的,越是向往高处的阳光,它的根就越要伸向黑暗的地底
