题目
假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,可共享相同的存储空间,例如,"loading"和"being"的存储映像如下图所示。
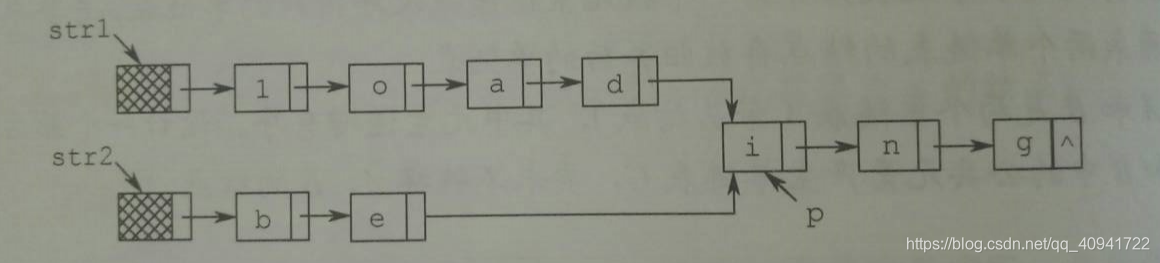
设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为
| data | next |
|---|
请设计一个尽可能高效的算法,找出由str1和str2所指向两个单链表共同后缀的起始位置。
分析
- 这其实是两个链表公共结点的问题;
- 两个链表有公共结点,即两个链表从某一结点开始,他们的
next都指向同一个结点。有与每个单链表结点只有一个next域,因此从第一个公共结点开始,之后他们所有的结点都是重合的,不可能再出现分叉,所以两个有公共结点而部分重合的单链表,拓扑形状看起来像 。 - 若两个链表有一个公共结点,则该公共节点之后的所有结点都是重合的,及它们的最后一个结点必然重合,因此,我们判断两个链表是不是有重合的部分时,指向分别遍历两个链表到最后一个结点,若两个尾结点是一样的,则说明他们有公共结点,否则两个链表没有公共结点。
- 注意,只有当两个链表同时遍历到尾部时,才能判断是否有公共部分,当两个链表长度不一致时,如 ,若有公共部分的话,公共部分的最大长度就是 ,而长链表的前 部分不可能是公共部分,因此不用参加同步遍历。
代码
#include<iostream>
#include<stdio.h>
using namespace std;
struct LNode{
char data;
LNode *next;
};
LNode* Insert(LNode &L, LNode *r, char ch){
LNode *tmp;
tmp = new LNode;
tmp->data = ch;
if(r == NULL){
tmp->next = L.next;
L.next = tmp;
return tmp;
}
tmp->next = r->next;
r->next = tmp;
return tmp;
}
int ListLen(LNode L){
int len = 0;
LNode *p = L.next;
while(p != NULL){
len++;
p = p->next;
}
return len;
}
LNode* FindAddr(LNode str1, LNode str2){
LNode *p, *q;
int m, n;
m = ListLen(str1);
n = ListLen(str2);
for(p=str1.next; m>n; m--)
p = p->next;
for(q=str2.next; n>m; n--)
q = q->next;
while(p != NULL && p != q){
p = p->next;
q = q->next;
}
return p;
}
int main(){
LNode str1,str2,str3;
str1.next = str2.next = str3.next = NULL;
LNode *r;
r = str3.next;
r = Insert(str3, r, 'i');
r = Insert(str3, r, 'n');
r = Insert(str3, r, 'g');
r = str1.next;
r = Insert(str1, r, 'l');
r = Insert(str1, r, 'o');
r = Insert(str1, r, 'a');
r = Insert(str1, r, 'd');
r->next = str3.next;
r = str2.next;
r = Insert(str2, r, 'b');
r = Insert(str2, r, 'e');
r->next = str3.next;
LNode *p = FindAddr(str1, str2);
printf("%c\n", p->data);
}
总结
该算法的时间复杂度为 。
